

Image description generation method based on architectural short sentence constraint vector and dual visual attention mechanism
A technology of image description and dual vision, applied in the field of computer vision, to achieve the effect of strong representation ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

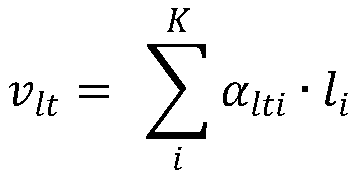
Examples
Embodiment 1
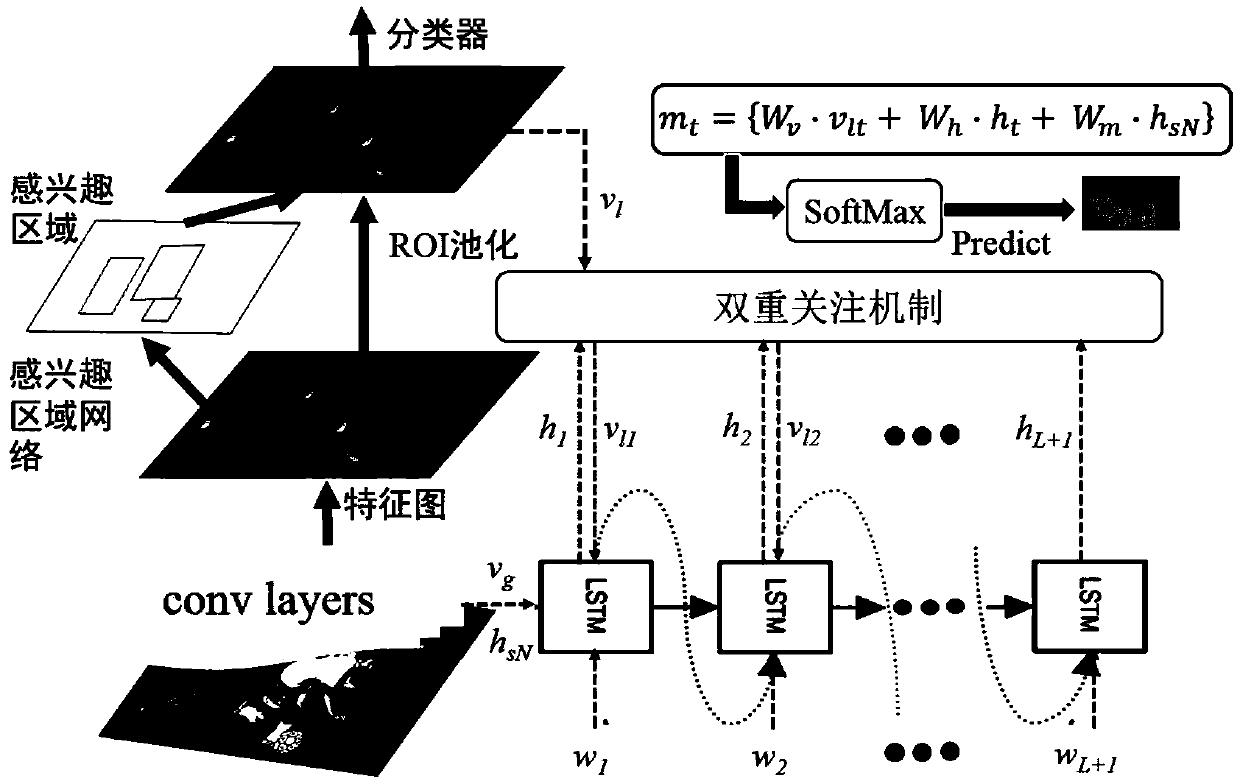
[0051] Figure 1~2 As shown in , the image description generation method based on the architectural phrase constraint vector and the dual visual attention mechanism includes the following steps:
[0052] S10. The training picture data in the training set contains 5 reference sentences. The words in each sentence are encoded by one-hot, and then projected into the embedding space through the embedding matrix to become a semantic word expression vector W t ;
[0053] S20. The word expression vector is used for the input of the circular convolutional neural network RNN at a certain time frame t, and the recurrent layer of the frame t at this time activates R t is the word expression vector of the current time frame and the recurrent layer R of the previous time frame t-1 t-1 Co-determined, the word input at each moment will be spliced with the visual features obtained by the dual visual attention mechanism as the LSTM input at that moment.
[0054] S30. The image extracts ...
Embodiment 2
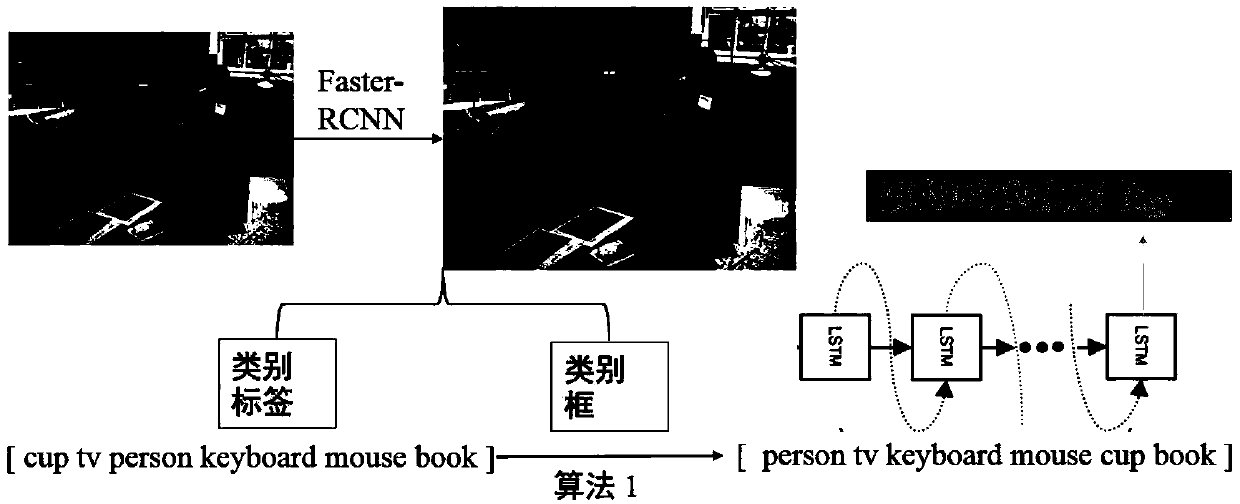
[0088] The pseudocode of generating the short sentences of the structure of the present invention is as follows,
[0089] Input: visual target label set L = {l 1 , l 2 ,..., l N}; visual target box B = {b 1 , b 2 ,...,b N}, and the position coordinate b corresponding to each target box i ={x i1 ,y i1 , x i2 ,y i2}, i∈{1,2,...,N}, N=10;
[0090] Output: Schema phrase L s ={l s1 , l s2 ,..., l sN};
[0091]
[0092]
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More