

Face image super-resolution reconstruction method based on an attribute description generative adversarial network
A super-resolution reconstruction and face image technology, which is applied in the field of digital image/video signal processing, can solve problems such as the difficulty in reconstructing the real attribute information of face identity, and achieve the effects of improving learning ability, promoting generation ability, and enhancing quality
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0052] Below in conjunction with accompanying drawing of description, the embodiment of the present invention is described in detail:
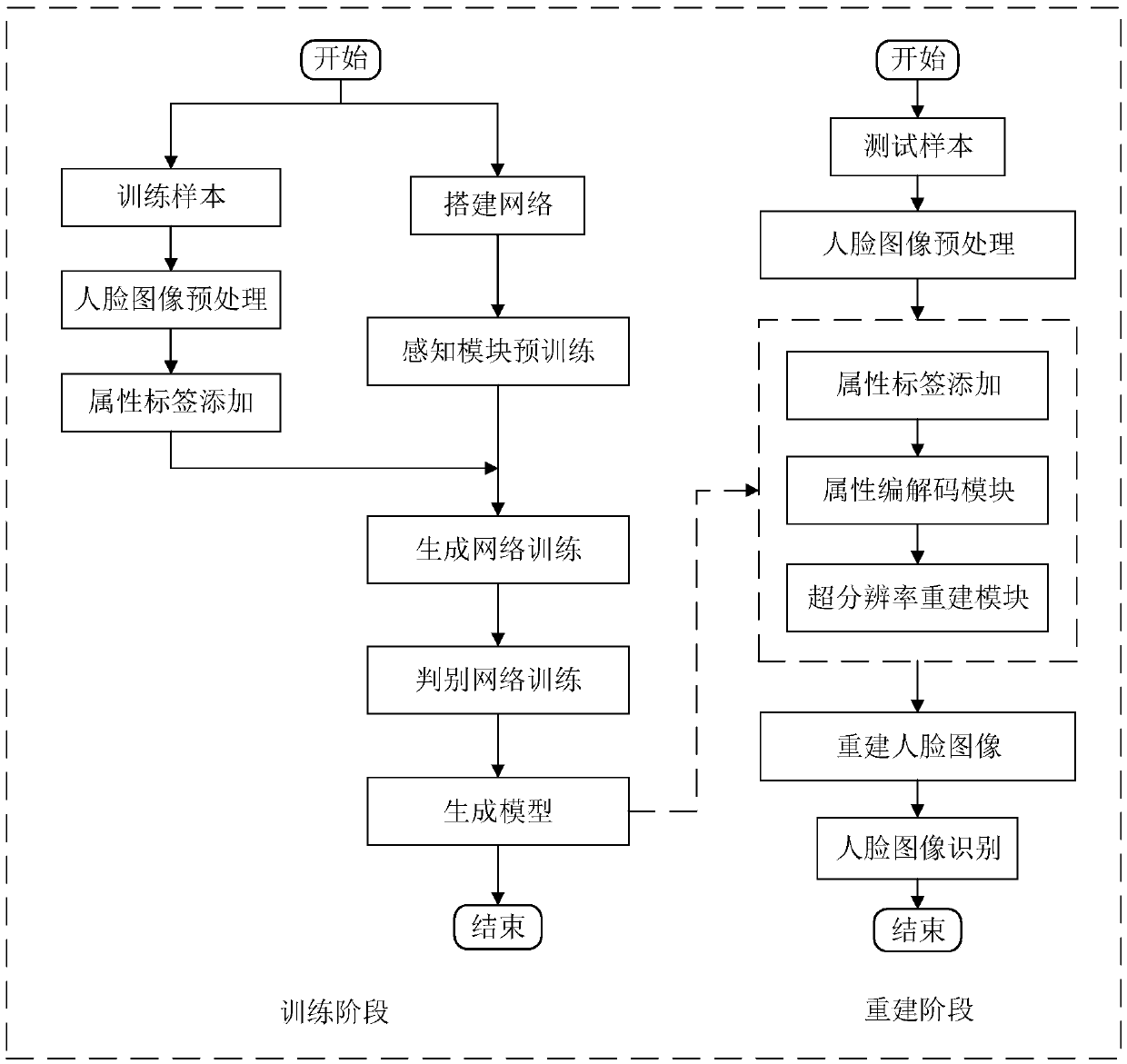
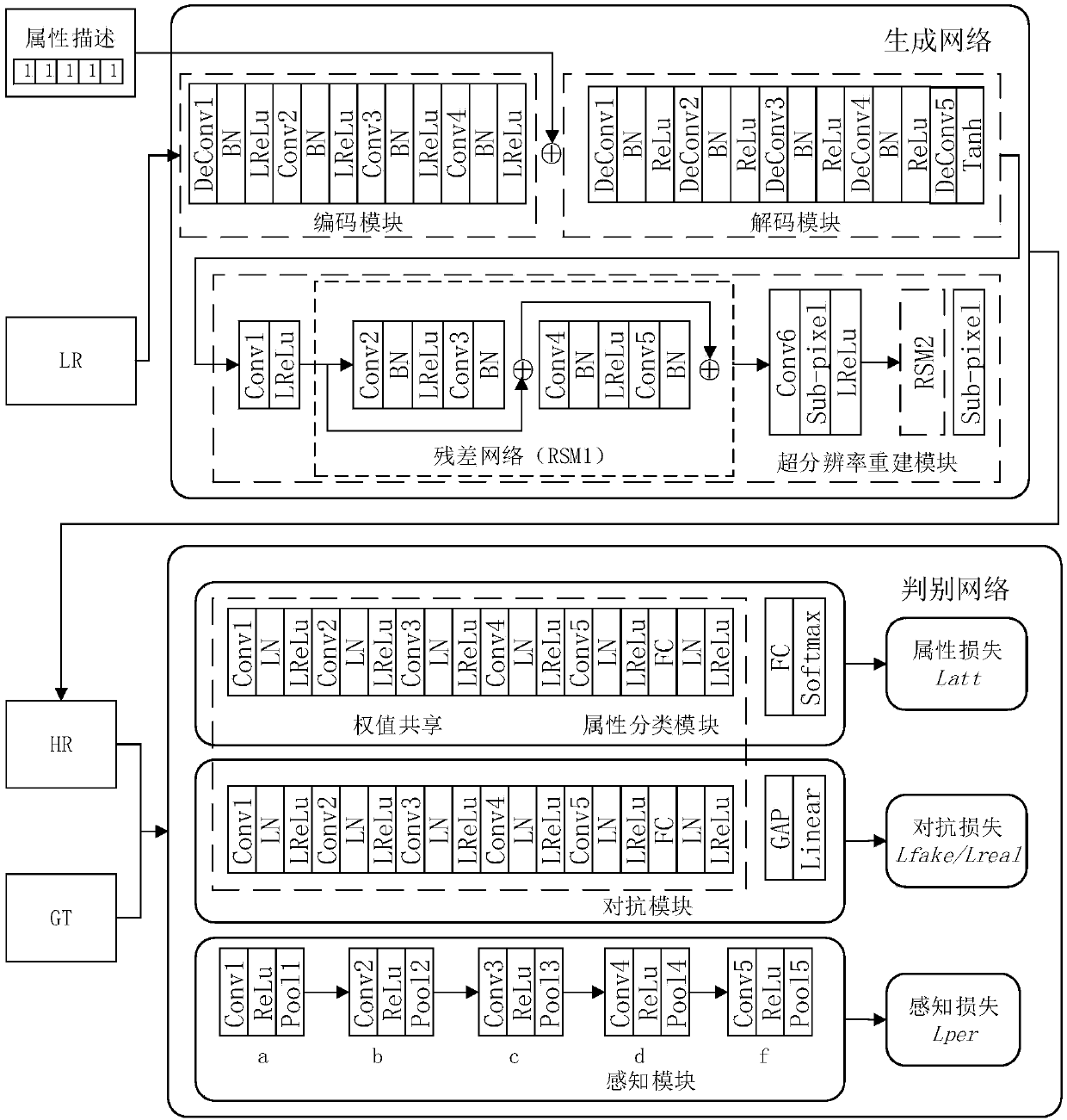
[0053] A face image super-resolution reconstruction method based on attribute description generative confrontation network, which is divided into training phase and reconstruction phase. The overall flow chart is attached figure 1 shown; the overall network structure diagram of the generated confrontation network is shown in the attached figure 2 shown.
[0054] (1) In the process of training data preprocessing, in order to reduce the error caused by different face image backgrounds and postures, the present invention obtains the training sample database through three stages. In the first stage, considering that the domestic and foreign common face data sets "CelebA" and "LFW" are obtained from actual monitoring, and they are universal and important for experimental comparison, the present invention uses data including 202,599 face images S...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More