

Machine learning strategy based distance preferred optimal path selection method
A distance-first, best-path technology, applied in the field of IoT
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
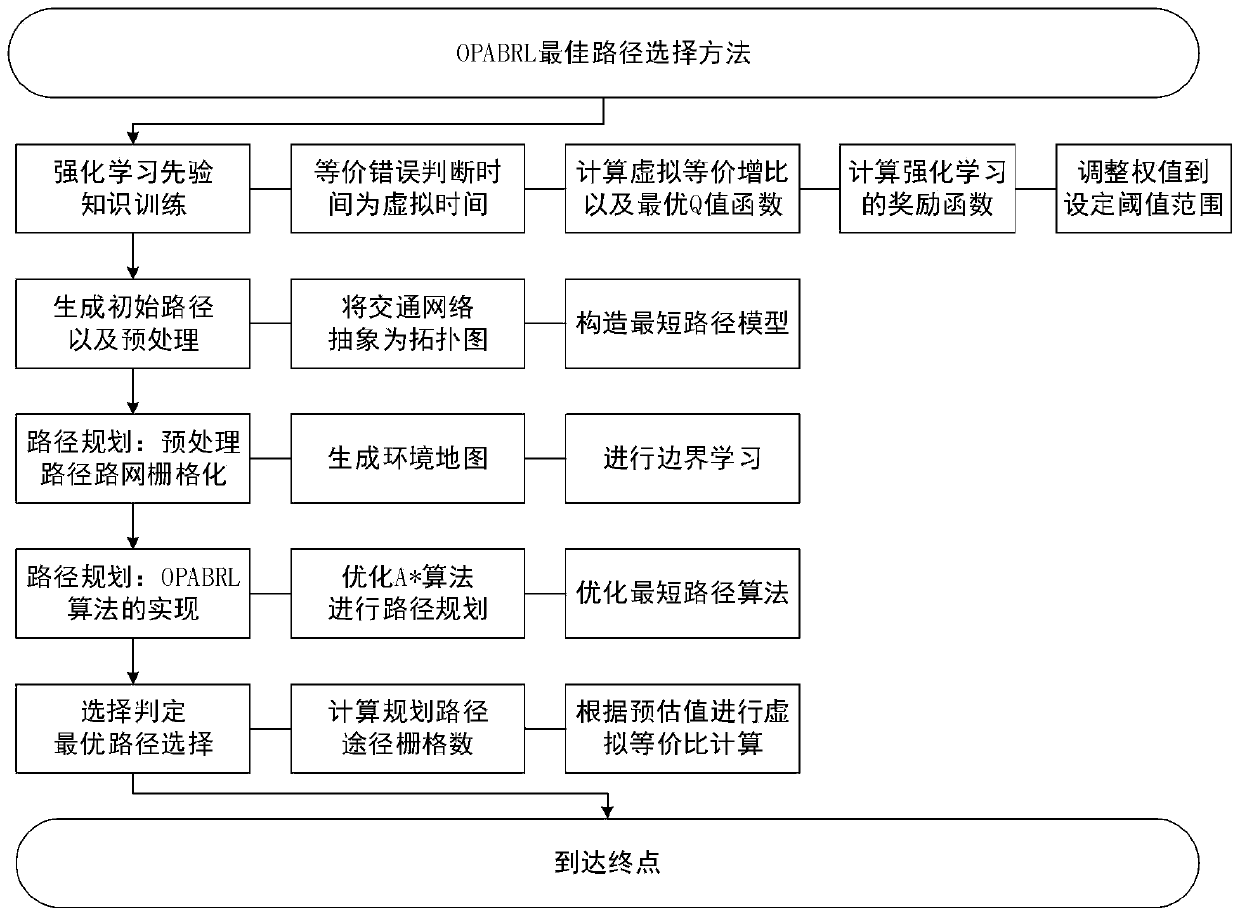
Embodiment Construction
[0042] For the Genetic Algorithm (GA), Ant Colony Optimization (ACO), Artificial Neural Networks (ANNs) and Particle Swarm Optimization (PSO), which are often used in intelligent robot path planning , compared with the design algorithm OPABRL in terms of algorithm function and performance, the advantages and disadvantages of the designed algorithm are explained by analyzing the results of the policy.
[0043] 1. Reinforcement learning prior knowledge training;
[0044] In the process of intelligent vehicle travel, the problems we have to solve include two aspects: path planning and path selection. In order to simplify the system, we first describe the reinforcement learning strategy and update rules based on prior knowledge:
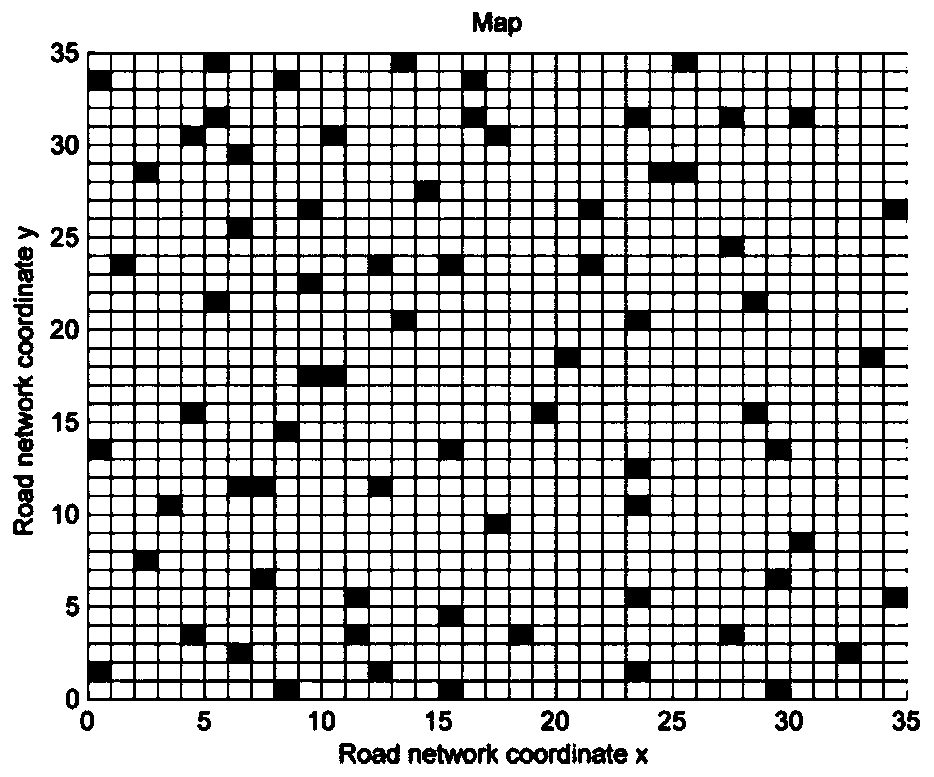
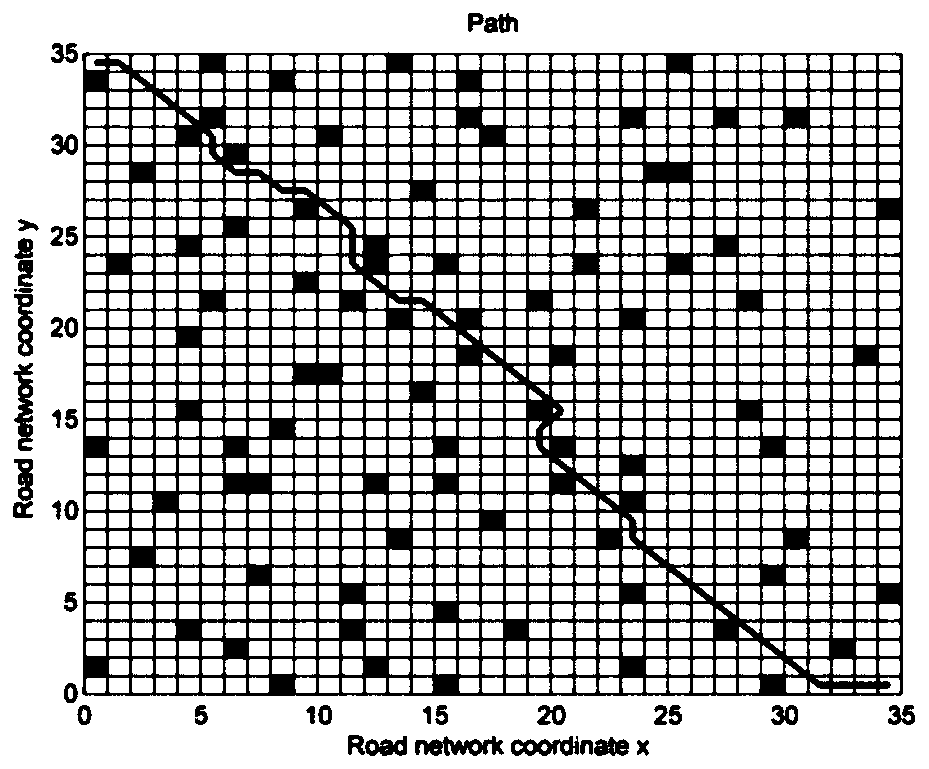
[0045] Assuming that the intelligent driving vehicle has been driving on a road with a certain width, the problem of path planning can be understood as solving the problem of planning one or more roads that can reach the end point from the starting poin...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More