Multi-level natural language anti-junk text method and system
A natural language, multi-level technology, applied in the field of information processing, can solve problems such as poor recognition of junk text, and achieve the effect of avoiding adverse effects, high robustness, and efficient recognition
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
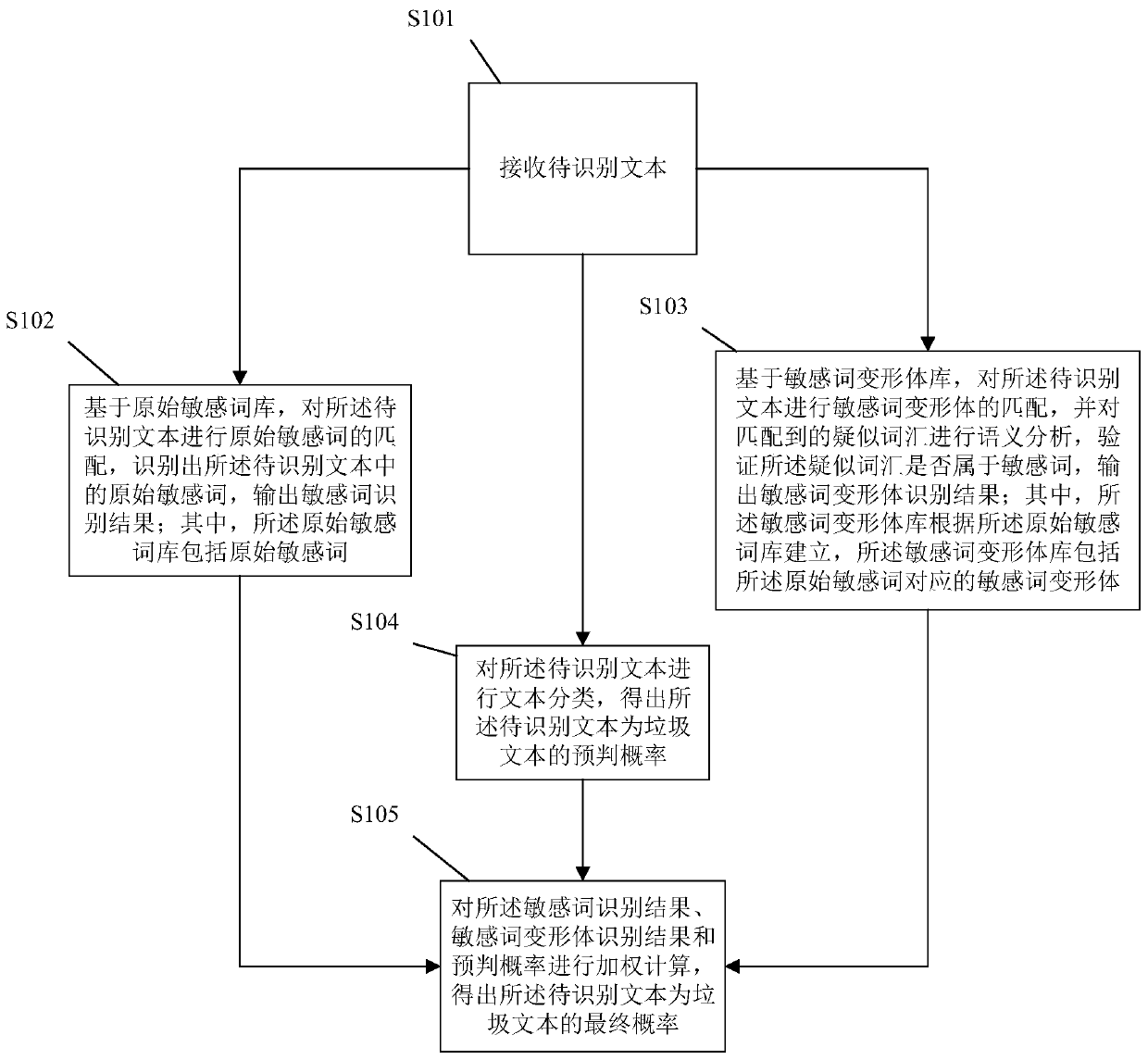
[0065] see figure 1 , a multi-level natural language anti-spam text method, comprising the following steps:
[0066] S101, receiving text to be recognized;
[0067] S102. Based on the original sensitive thesaurus, match the original sensitive words on the text to be recognized, identify the original sensitive words in the text to be recognized, and output the sensitive word recognition result; wherein, the original sensitive thesaurus includes the original Sensitive words;
[0068] S103, based on the database of sensitive word variants, perform matching of sensitive word variants on the text to be identified, perform semantic analysis on the matched suspected words, verify whether the suspected words belong to sensitive words, and output sensitive word variant identification Result; Wherein, described sensitive word deformation body database is established according to described original sensitive word database, and described sensitive word deformation body database comprise...
Embodiment 2
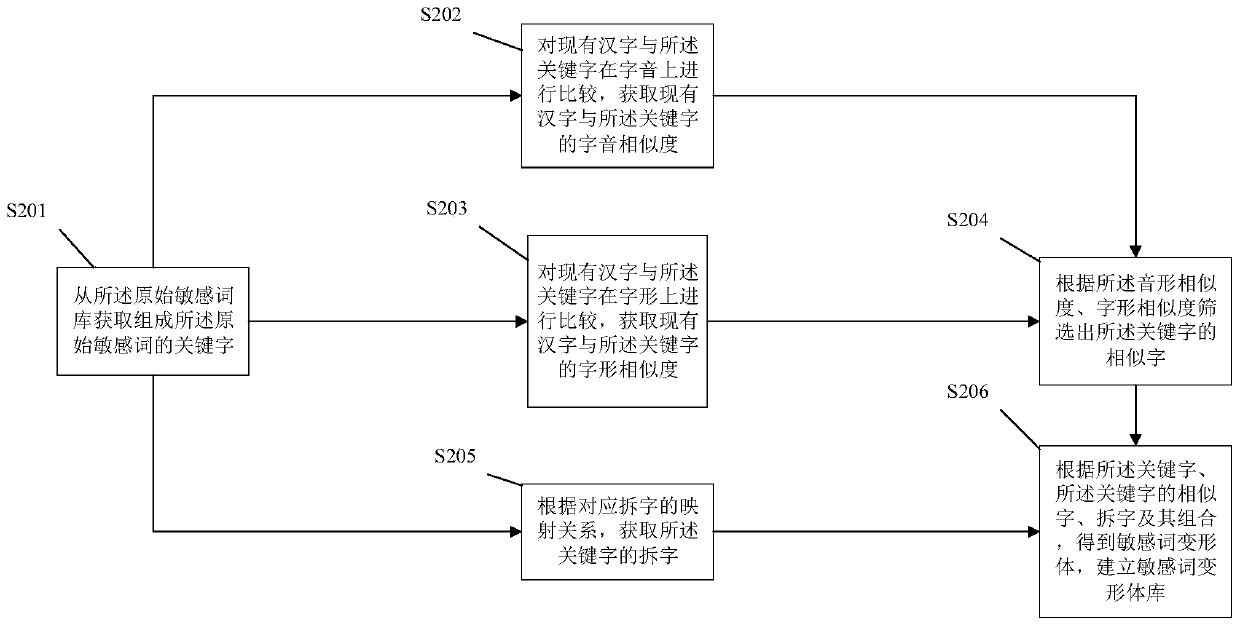
[0084] Embodiment 2 is an improvement on the basis of Embodiment 1, mainly for how to set up the database of sensitive word variants, please refer to figure 2 , the establishment of the sensitive word variant database, comprising the following steps:
[0085] S201. Obtain keywords that form the original sensitive words from the original sensitive thesaurus;
[0086] S202. Comparing the pronunciation of the existing Chinese characters with the keyword, and obtaining the similarity in pronunciation between the existing Chinese characters and the keyword;
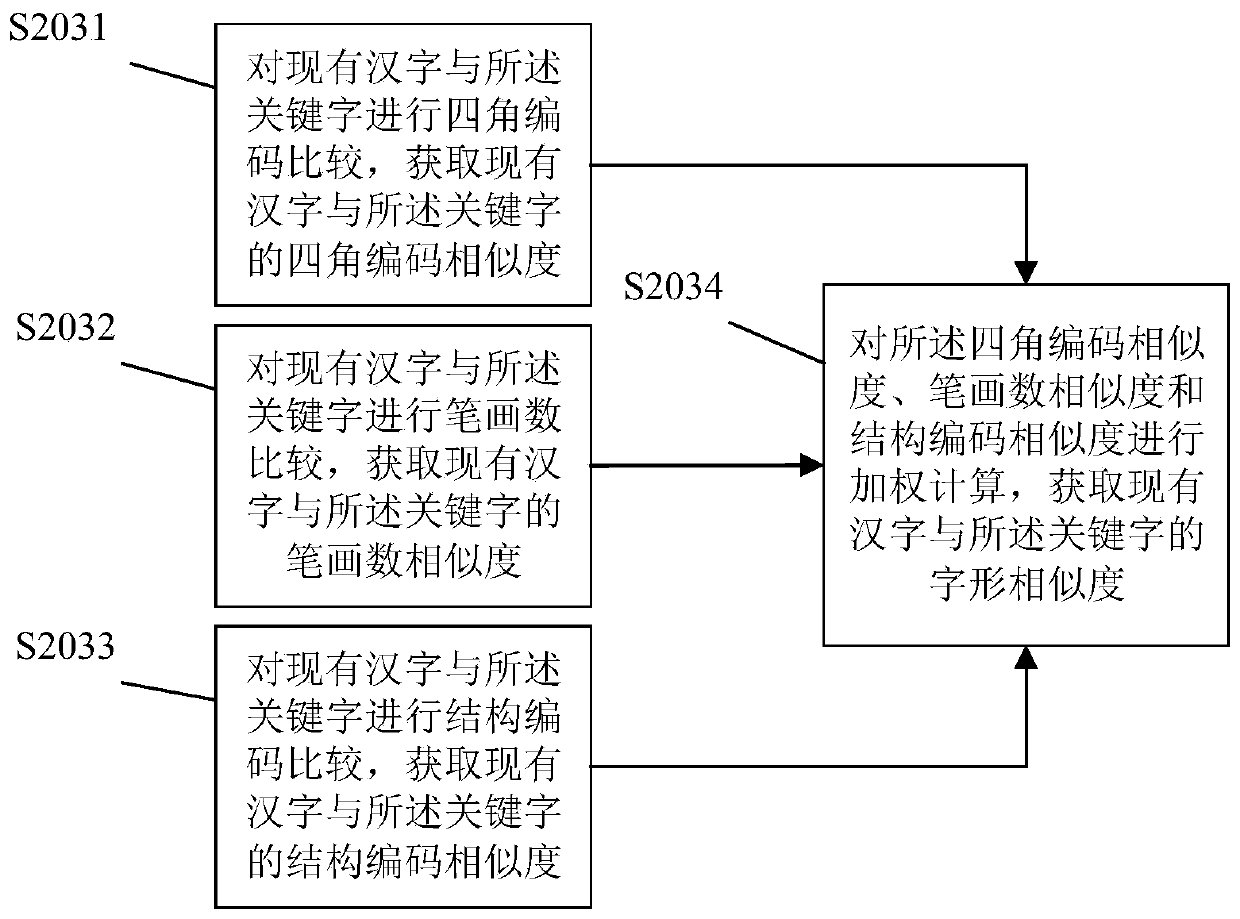
[0087] S203. Comparing the existing Chinese characters with the keyword in terms of font, and obtaining the font similarity between the existing Chinese character and the keyword;
[0088] S204, filter out similar words of the keyword according to the phonetic-shape similarity and font-shape similarity;
[0089] S205. According to the mapping relationship corresponding to the split characters, acquire the split characters o...
Embodiment 3
[0114] Embodiment 3 is an improvement on the basis of Embodiment 1 or 2. It is mainly aimed at how to classify the text to be recognized to obtain the predicted probability that the text to be recognized is junk text. Please refer to Figure 4 , including the following steps:
[0115] S301. Segment and vectorize the text to be recognized to form vectorized information to be recognized;
[0116] S302, using a deep neural network classification model combined with a convolutional neural network and a long-term short-term memory network and trained by a corpus data set to process the vectorized information to be identified, and obtain a predicted probability that the text to be identified is junk text .
[0117] Through the above steps, the continuous text is segmented and vectorized, which is easy to analyze with the method of mathematical model; the deep neural network classification model combined with convolutional neural network and long-term short-term memory network and t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com