

Multi-mode lip reading method based on facial physiological information
A physiological information, multi-modal technology, applied in 3D modeling, image data processing, computer parts and other directions, can solve the problem that has not yet involved the human inner vocal mechanism, the lip movement feature extraction method stays in the surface phenomenon observation, the three-dimensional space point Cloud's internal relationship is not clear and other issues
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
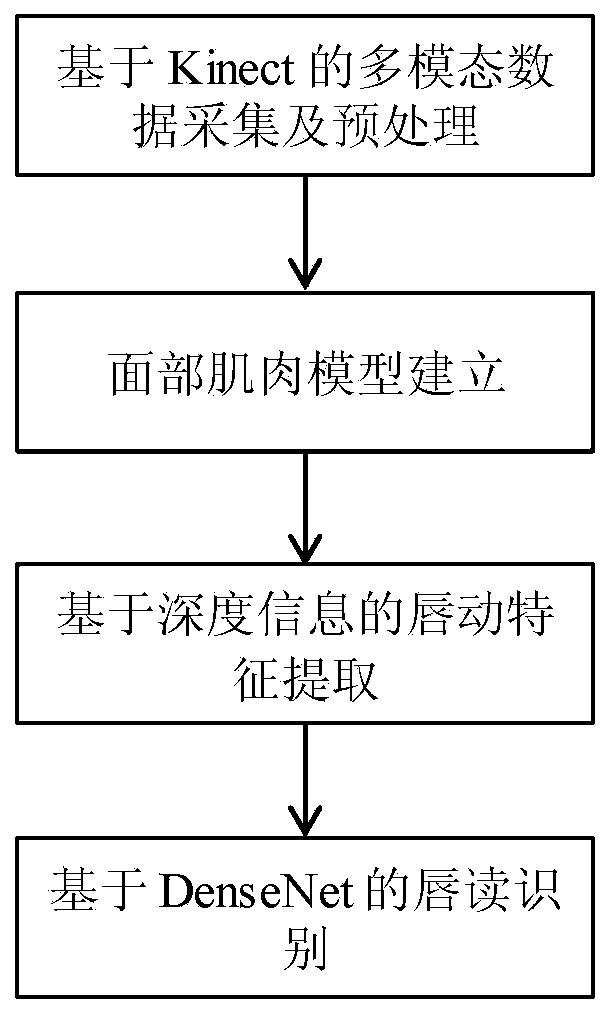
[0052] The embodiment of the present invention provides a multimodal lip reading method based on facial physiological information, see figure 1 , the method includes the following steps:
[0053] 101: Kinect-based multi-modal data acquisition and preprocessing;
[0054] 102: Facial muscle model establishment;
[0055] 103: Lip movement feature extraction based on depth information;
[0056] 104: Lip reading recognition based on DenseNet.
[0057] In one embodiment, step 101 synchronously collects the audio data, color image data and depth data during the lip movement of the speaker, and then preprocesses the collected data. The specific method is as follows:
[0058] Use the P2FA tool to force the alignment of the audio, and segment the color image and 3D depth information according to the alignment results. For color image data, first use the cascade classifier based on the OpenCV vision library to detect the face in the image to determine the position of the speaker's fa...
Embodiment 2
[0064] The scheme in embodiment 1 is further introduced below in conjunction with specific calculation formulas and examples, see the following description for details:
[0065] 201: After the multimodal data is collected, the data must first be preprocessed, the audio is forced to be aligned, and the color image and 3D depth information are segmented according to the alignment result;
[0066] 202: Perform face detection, lip area positioning, and data expansion on color image data;
[0067] Wherein, brightness change is used in data expansion, and the embodiment of the present invention uses gamma transformation to correct color image information, as shown in formula (1).
[0068] S=cg γ (1)
[0069] In the formula, both c and γ are positive real numbers, g represents the gray value of the input image, and s represents the transformed gray value. If γ is greater than 1, the grayscale of the brighter area in the image is stretched, the grayscale of the darker area is comp...
Embodiment 3
[0129] Below in conjunction with concrete experimental data, the scheme in embodiment 1 and 2 is carried out feasibility verification, see the following description for details:
[0130] The embodiment of the present invention uses DenseNet for lip reading recognition with temporal continuity for the first time, and proposes a new method of preserving the temporal continuity of images by splicing. Using color image data of 8-speaker pairs of vowels / a / , / o / , / e / , / i / , / u / to demonstrate the feasibility of the network model for lip reading recognition and the concatenation method for retention time Continuity of effectiveness.
[0131] The obtained classification results are as Figure 7 As shown, the recognition rate of the five vowels reached 99.17%, and the recognition rates of the syllables / a / , / e / all reached 100%. This result shows that a part of time information can be preserved through image splicing. In addition, the DenseNet network structure used in the present in...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More