

Group discovery algorithm model based on big data mining and analysis module
An algorithm model, big data technology, applied in network data retrieval, data processing applications, other database retrieval and other directions, to achieve the effect of long-term operation, good ventilation and heat dissipation, and good heat dissipation performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

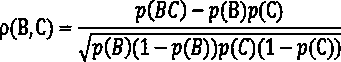
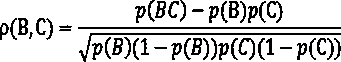
Examples
Embodiment 1
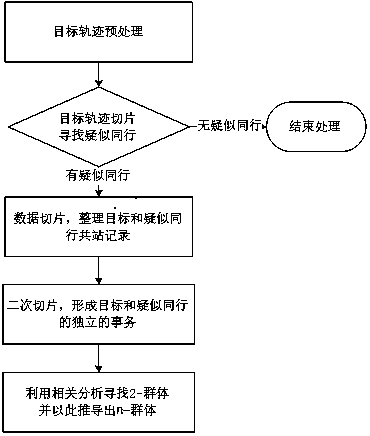
[0045] Such as figure 1 As shown, a kind of group discovery algorithm model based on big data mining described in the present invention comprises the following steps:
[0046] S1: Obtain each track data of the target and perform preprocessing;
[0047] For target A, for all records of A within the specified time range, and grouped by site, each group is sorted by time, and the grouped data is deduplicated with a fixed interval, that is, if a person is in a site for a short time (interval) appears multiple times in a row, and only the first record is kept; in addition, if the repeated data lasts longer than △t, then every △t, keep a nearby record (if equal, keep the one with the earlier time) record), and the subsequent data retention time is based on the last data retention time.
[0048] S2: Take each valid trajectory data of the target as the starting point, intercept the preprocessed trajectory data with the specified time length δ, and perform preprocessing on each inter...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More