High-dimensional feature data classification method and system based on distributed parallel decision tree
A technology of feature data and classification methods, which is applied in special data processing applications, relational databases, database models, etc., can solve problems such as inability to efficiently process high-dimensional feature data, achieve the effect of shortening the establishment time and improving parallel efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

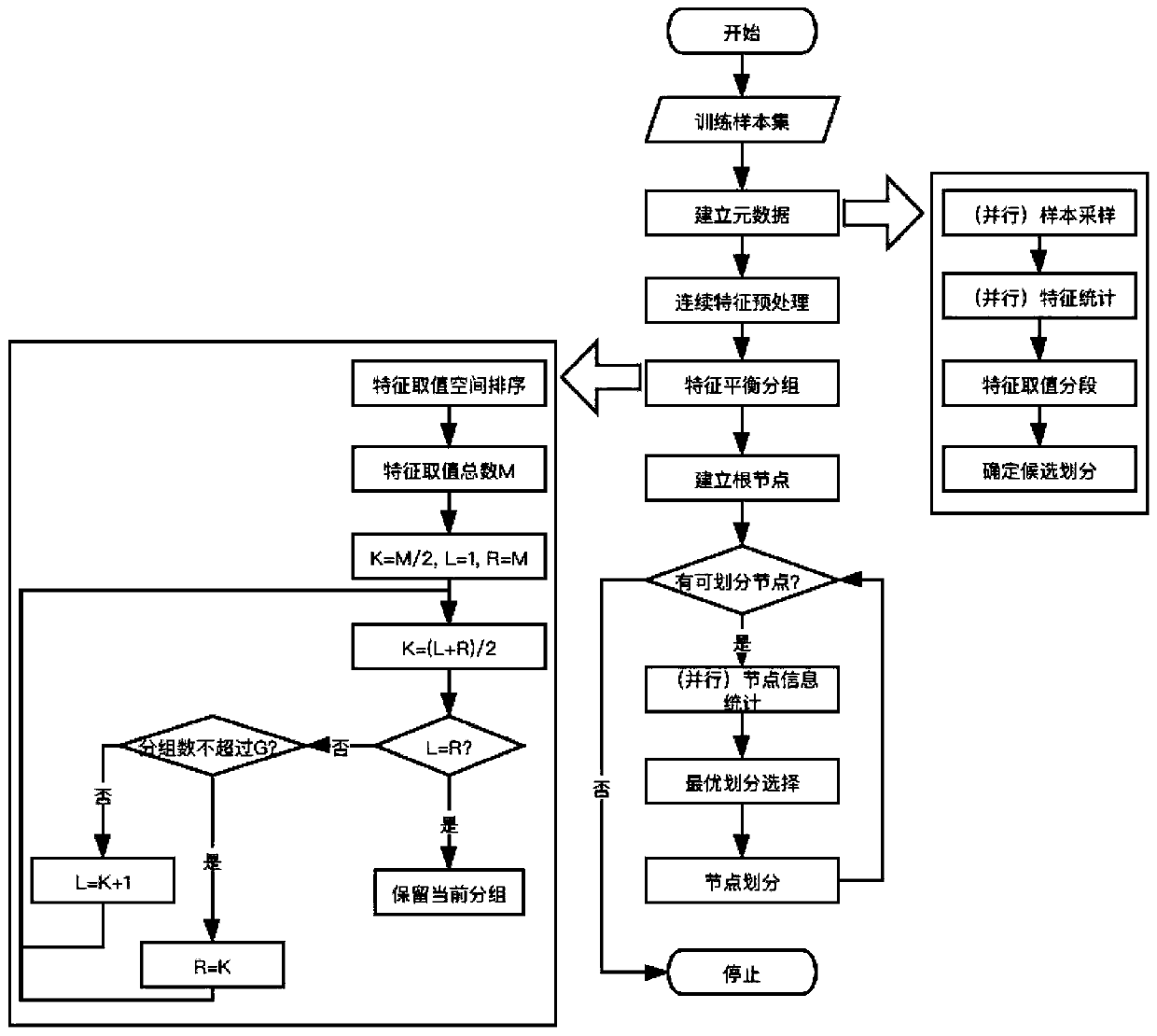
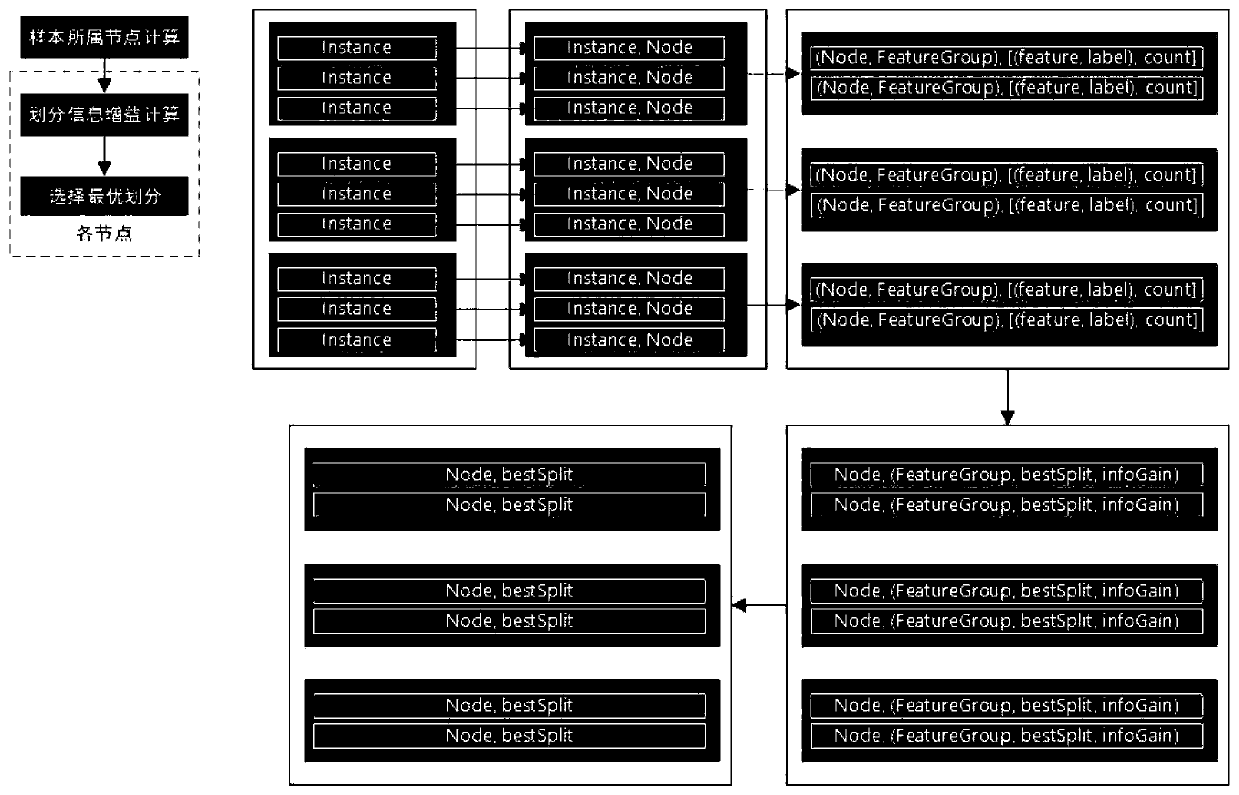
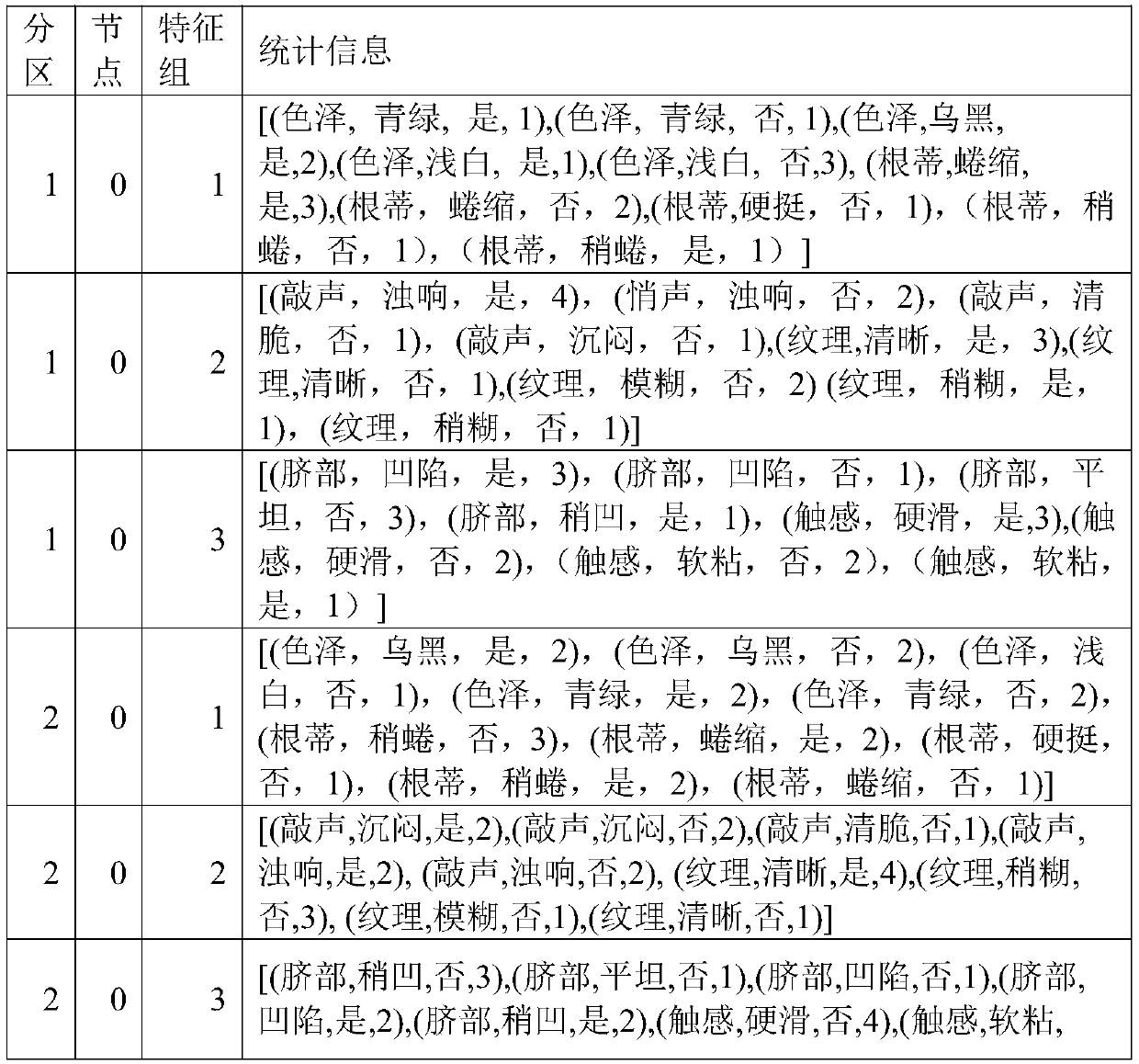
Examples
Embodiment Construction
[0037] When the inventors conduct large-scale data mining research, they find that the data dimension is very large, and the existing decision tree algorithm cannot handle this data well. The reason is that the serial decision tree cannot handle large-scale data, and the existing parallel decision tree algorithm has a low degree of parallelism, and the fastest algorithm is only parallel at the node level, but not in the optimal feature selection part. In the case of large feature dimensions and many feature values, using a multi-fork decision tree will lead to too many decision tree nodes, resulting in excessive memory usage and overfitting. Using a binary decision tree must divide all possible nodes. Traversal, finding the information gain of each division and deciding the optimal node will also bring a lot of time consumption. Existing parallel decision tree algorithms do not take this into account, because naturally occurring data rarely have particularly large feature dime...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com