

Method and device for determining semantic similarity of text based on graph data
A graph data and similarity technology, applied in the computer field, can solve the problems of limited effect of training text similarity model, complex semantic expression, large amount of data, etc., and achieve the effect of an effective text semantic similarity determination method
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
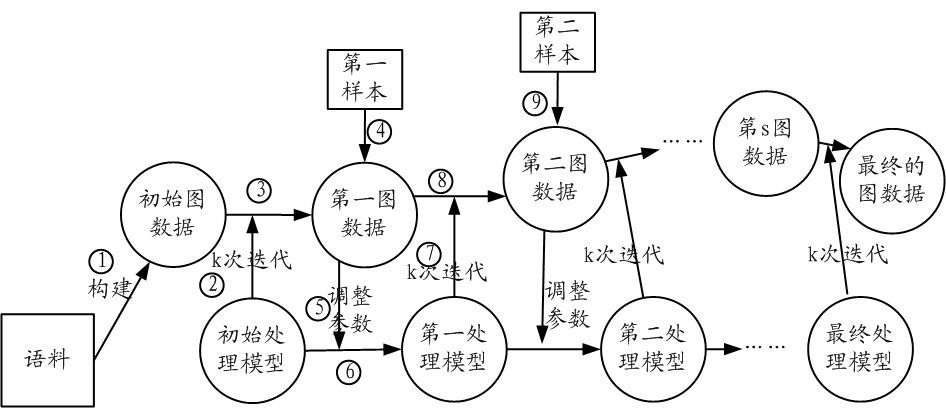
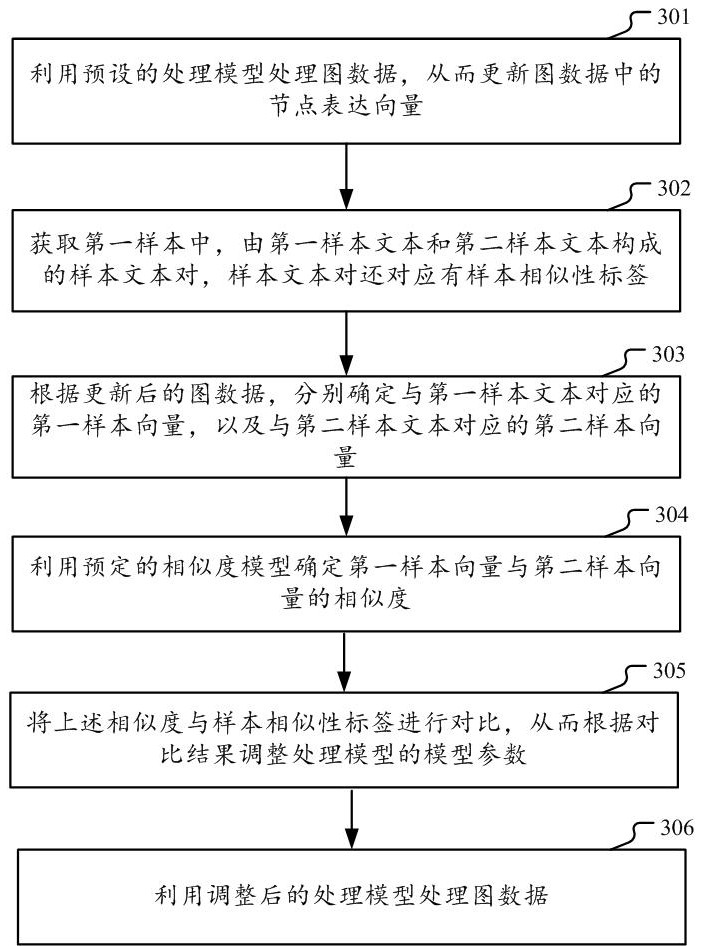
[0046] The solutions provided in this specification will be described below in conjunction with the accompanying drawings.
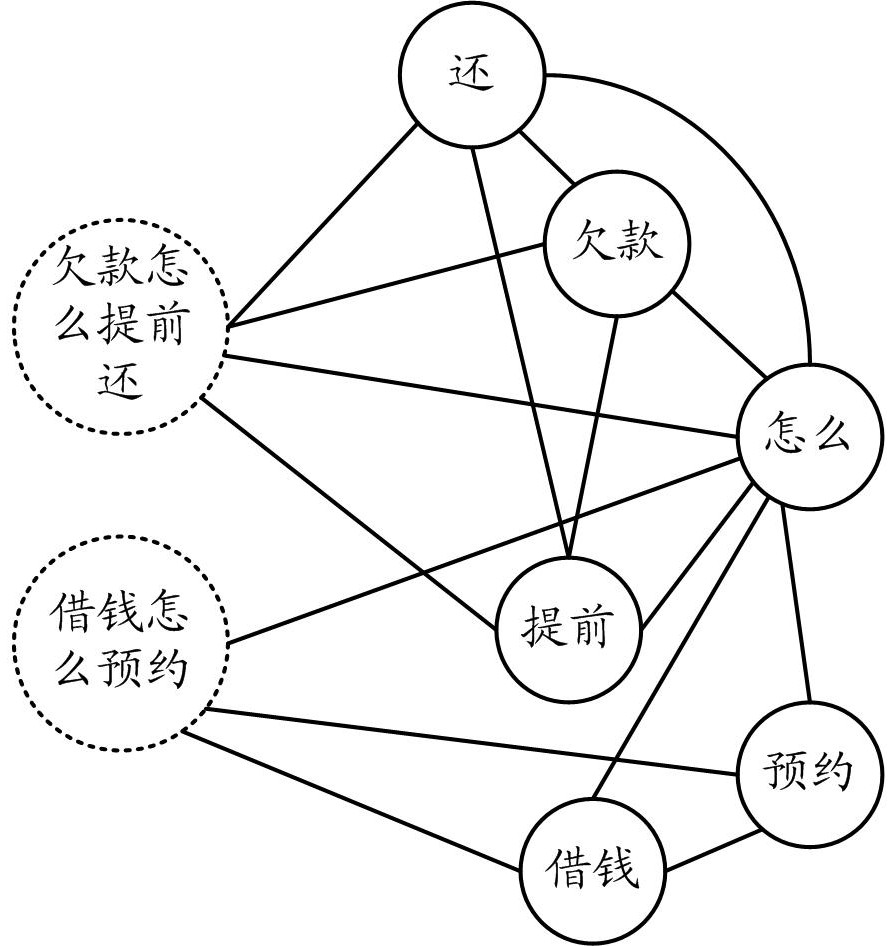
[0047] figure 1 A schematic diagram of graph data suitable for the implementation architecture of this specification is shown. The graph data applicable to the implementation framework of this specification can describe the sentences and words in the corpus, as well as the relationship between them. In graph data, sentences and words correspond to each node, and each node can be represented by a corresponding node vector. The connection relationship between nodes is represented by connecting edges. Among them, the corpus can include corpus data obtained from various channels or sources, such as news corpus, daily chat corpus, diplomatic corpus, professional academic data (such as agricultural, medical and other professional corpus), and customer service of various network platforms. corpus and so on.
[0048] exist figure 1 In , graph data is given ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More