

Method for long text retrieval in open domain question and answer task, and electronic equipment
An open-field, long-text technology, applied in the direction of unstructured text data retrieval, text database query, special data processing applications, etc., can solve problems such as error-prone, poor generalization, cumbersome process, etc., to improve accuracy, improve Ambiguity problem, strong reusability effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
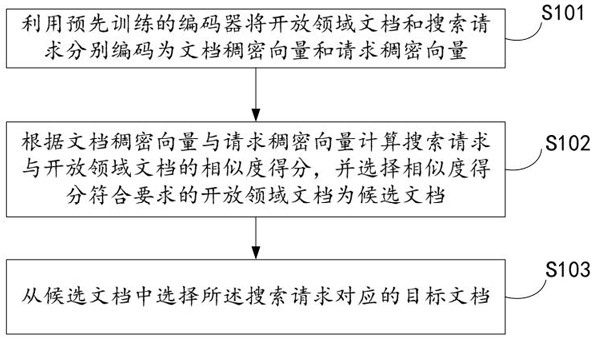
[0050] Such as figure 1 As shown, the embodiment of the present invention provides a method for long text retrieval in an open domain question answering task, including:
[0051]S101, using a pre-trained encoder to encode open domain documents and search requests into document dense vectors and request dense vectors respectively; wherein, the encoder uses historical search requests, positive samples and negative samples as sample data for training;
[0052] S102. Calculate the similarity score between the search request and the open domain document according to the document dense vector and the request dense vector, and select the open domain document whose similarity score meets the requirements as a candidate document;
[0053] S103. Select a target document corresponding to the search request from the candidate documents.
[0054] The above method can be described as:
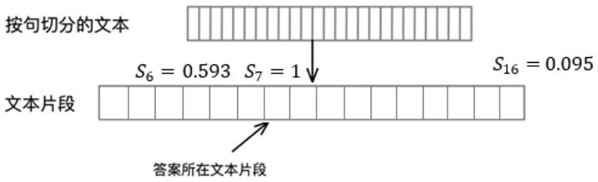
[0055] Given a collection of historical search requests , the document collection where the answer co...
Embodiment 2
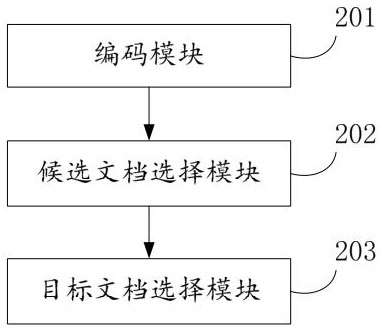
[0100] Such as image 3 As shown, another aspect of the present invention also includes a functional module architecture completely corresponding to the aforementioned method flow, that is, the embodiment of the present invention also provides a device for long text retrieval in an open domain question answering task, including:
[0101] The encoding module 201 is used to encode the open-domain documents and search requests into document dense vectors and request dense vectors respectively by using a pre-trained encoder; wherein, the encoder uses historical search requests, positive samples and negative samples as sample data to perform train;
[0102] A candidate document selection module 202, configured to calculate the similarity score between the search request and the open domain document according to the document dense vector and the request dense vector, and select the open domain document whose similarity score meets the requirements as a candidate document;
[0103] ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More