Single-step delay stochastic gradient descent training method for machine learning
A stochastic gradient descent and training method technology, applied in the optimization field of distributed training, can solve problems such as low convergence accuracy, achieve the effects of improving training speed, improving utilization rate, and ensuring training accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0018] Example 1: One-step delayed stochastic gradient descent training method for machine learning.
[0019] This embodiment implements OD-SGD in MXNet, which is an efficient and flexible distributed training framework specially designed for neural network training. MXNet is implemented based on the parameter server structure. One of its key designs is the dependency engine, which is a static library that is scheduled according to the dependencies between operations. During the training process, operations without dependencies can be executed in parallel. The default MXNet framework only defines one update function in one training mode. Although OD-SGD is implemented in MXNet, it is equally applicable to point-to-point deep learning frameworks such as Pytorch and Caffe. The method includes the following steps:
[0020] S1: Define global update function and local update function
[0021] The single-step delay stochastic gradient descent training method includes a global upd...
Embodiment 2
[0029] Example 2: OD-SGD implements the method in the MXNet framework.
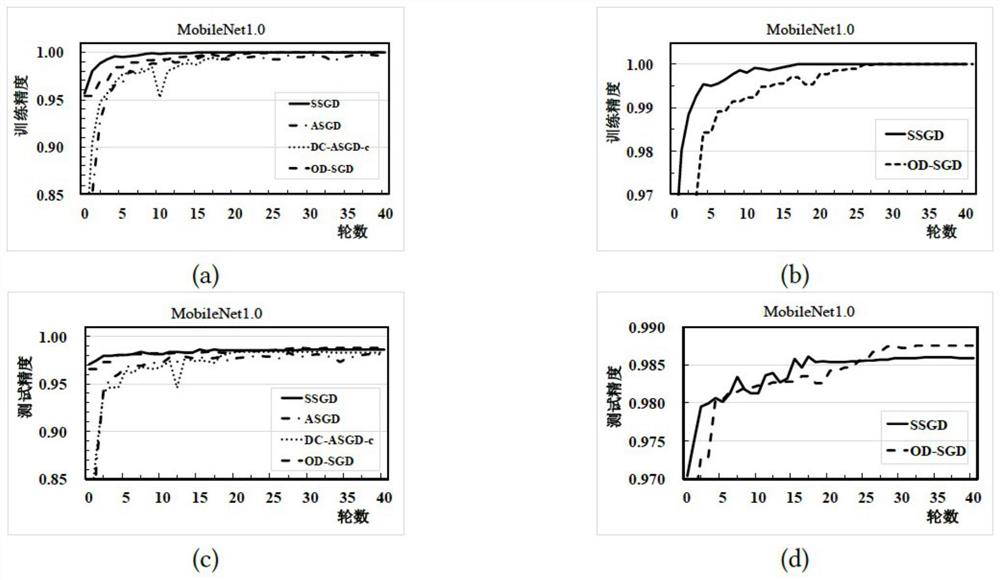
[0030] OD-SGD is implemented in the MXNet framework, and evaluation experiments are conducted on GPU clusters with 5, 9 and 13 computers. Each machine has 20 2.60GHz Intel cores, 256G memory, and is equipped with 2 K80 (dual GPU) Tesla GPU processors. The clusters are interconnected via Ethernet and InfiniBand with network bandwidths of 10Gbps and 56Gbps respectively. All machines are installed Red Hat4.8.3, CUDA8.0 and cuDNN 6.0. During the implementation, one of the machines is set as a parameter server and scheduling node, and the rest of the machines are set as computing nodes.
[0031] In order to prove the effectiveness of the method of the present invention, three data sets are used for implementation: (1) MNIST, which is a handwritten digit database, consists of 60,000 training samples and 10,000 testing samples. (2) CIFAR-10, which contains 60000 32x32 color images of 10 different categories, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More