Data clustering method and system, storage medium and equipment
A technology of data clustering and clustering algorithm, applied in the field of data analysis, can solve the problem that the output quality of clustering results cannot be guaranteed, and achieve the effect of ensuring the output quality
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
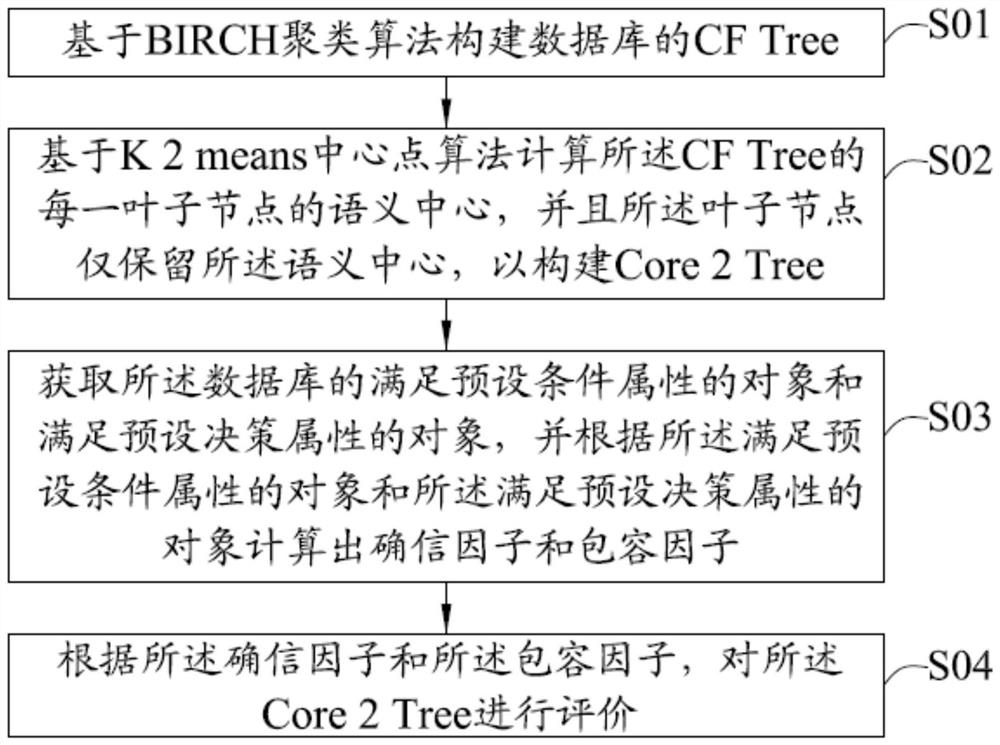
[0046] see figure 1 , which shows the data clustering method in Embodiment 1 of the present invention, which can be applied to a data clustering device. The data clustering method can be implemented by software and / or hardware, and the method specifically includes steps S01 to S01. S04.
[0047] Step S01, build a CF Tree of the database based on the BIRCH clustering algorithm.
[0048] Among them, the BIRCH (Balanced It 2erative Reducing and Clustering) clustering algorithm completes the clustering process by reading the objects one by one to construct a CF Tree (Clustering Feature Tree), so it is an incremental method, and the clustering structure outputs CF Tree structure. Another feature of the BIRCH clustering algorithm is that it can control the size of the CF tree to make the storage requirements match the actual memory size, which is suitable for large databases. In the specific implementation, the BIRCH algorithm can be used to scan the database once, and then the C...
Embodiment 2
[0081] Embodiment 2 of the present invention also proposes a data clustering method. The difference between the data clustering method in this embodiment and the data clustering method in the first embodiment is:
[0082] After the step of constructing the CF Tree of the database based on the BIRCH clustering algorithm, it also includes:
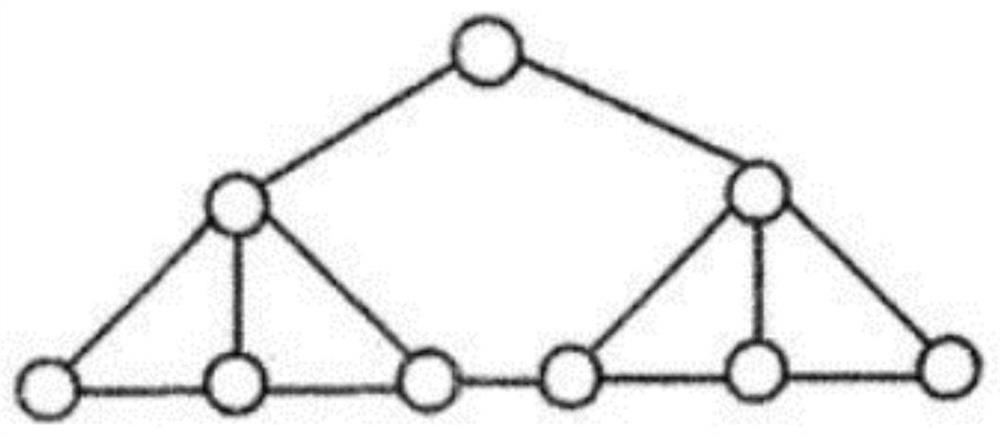
[0083] Connect any two adjacent leaf nodes of the CF Tree with a line segment to determine the left and right neighbors of each leaf node except the head leaf node and the tail leaf node.
[0084] Specifically, when the first step of the BIRCH algorithm is executed, a CF Tree will be stored in the memory, and all the leaves of the CFTree will be connected at this time, such as figure 2 As shown, each leaf node has left and right neighbors (except the head leaf and tail leaf). What needs to be explained here is that an important feature of cluster analysis is that it does not depend on the order, and the BIRCH algorithm is very sensitive to...
Embodiment 3
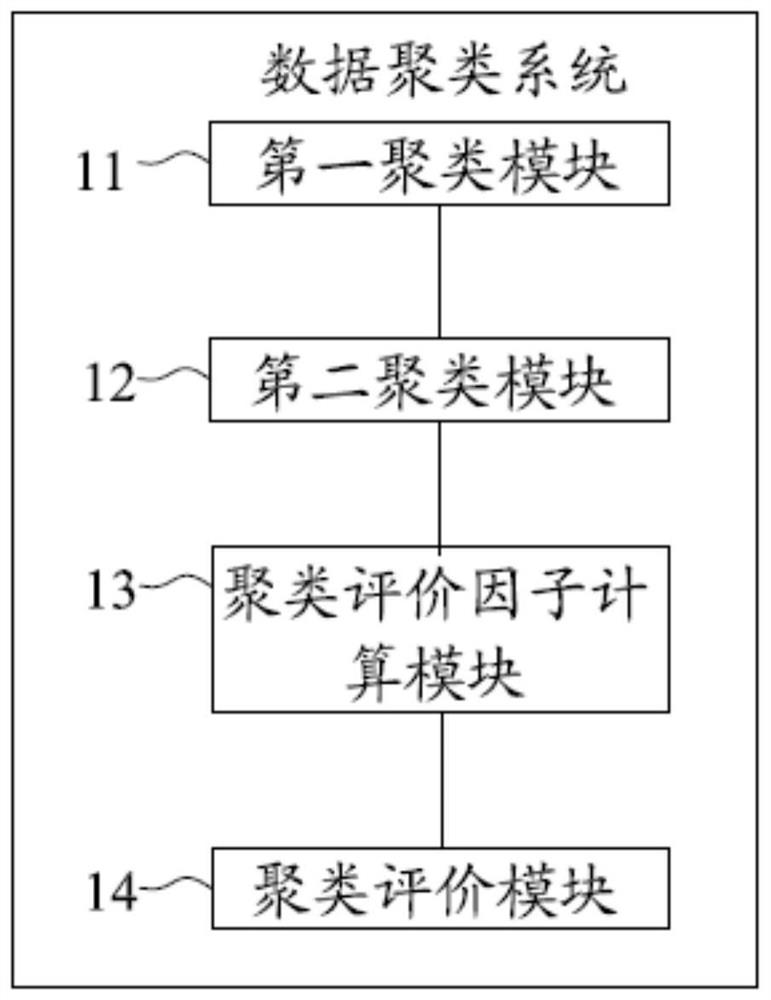
[0090] Another aspect of the present invention also provides a data clustering system, please refer to image 3 , shows the data clustering system in Embodiment 3 of the present invention, which can be applied to data clustering equipment, and the data clustering system specifically includes:
[0091] The first clustering module 11 is used to construct the CF Tree of the database based on the BIRCH clustering algorithm;
[0092] The second clustering module 12 is used to calculate the semantic center of each leaf node of the CF Tree based on the K2means center point algorithm, and the leaf node only retains the semantic center to construct Core 2 Tree;
[0093] The clustering evaluation factor calculation module 13 is used to obtain the objects satisfying the preset condition attributes and the objects satisfying the preset decision attributes of the database, and according to the objects satisfying the preset condition attributes and the satisfying preset decision attributes ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com