

Auxiliary diagnosis method and system based on electronic medical record texts
An electronic medical record and auxiliary diagnosis technology, applied in the field of healthcare informatics, can solve the problems of difficult to achieve accuracy, low model accuracy upper limit, etc., and achieve the effect of small difference in data nature, high accuracy upper limit, and low cost.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
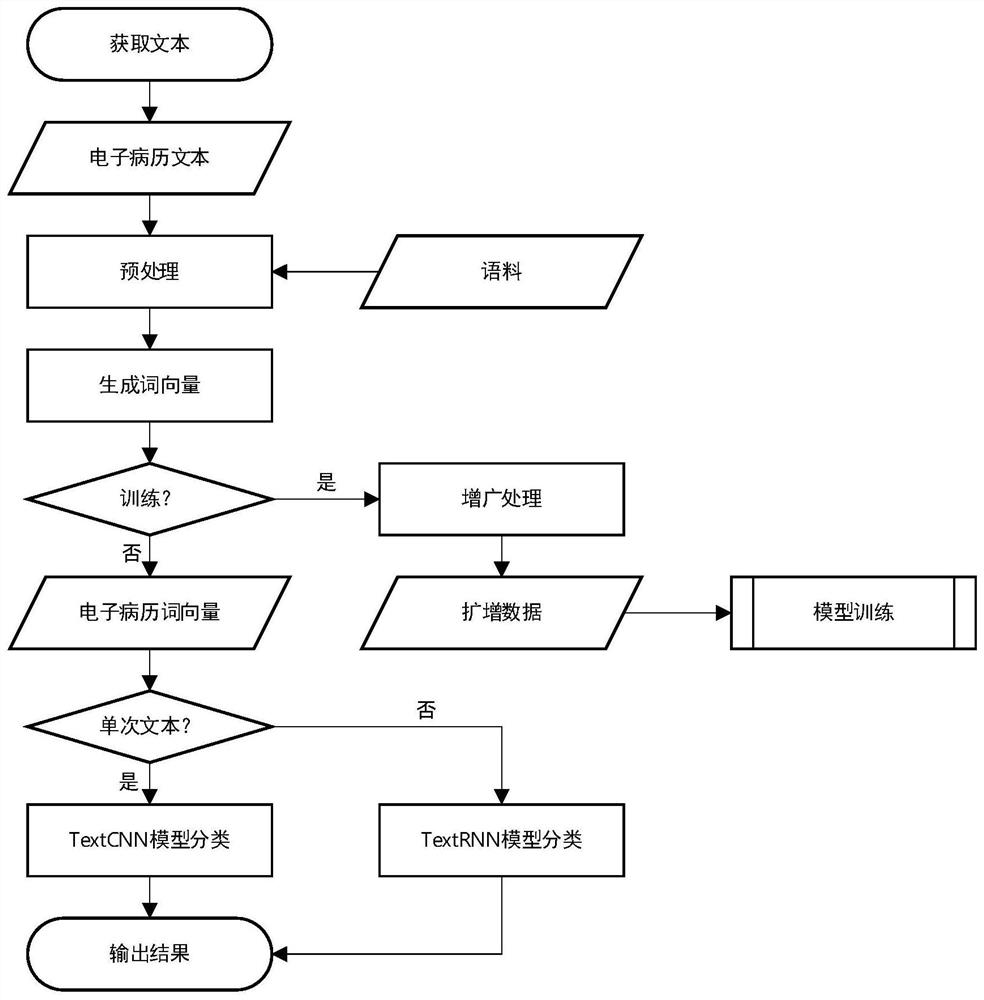
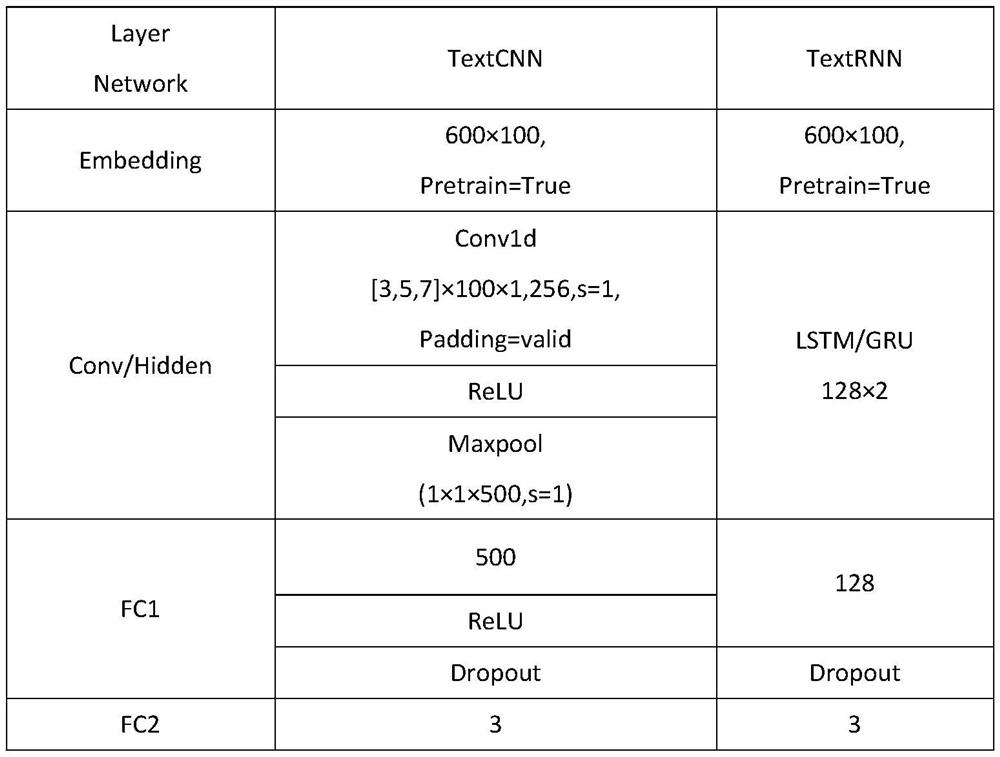
[0029] like figure 1 A method for auxiliary diagnosis based on electronic medical record text is shown, using the TextCNN model and the TextRNN model, respectively for the medical record text obtained from a single consultation activity and the medical record text obtained from multiple observations, after preprocessing and generating word vectors Classify diseases.
[0030] When the TextCNN model and the TextRNN model need to be trained, augmentation processing is performed after the word vector is generated from the electronic medical record text.
[0031] A typical process of preprocessing and generating word vectors is as follows:
[0032] 1) Based on the stop word corpus, remove the words that appear frequently in the electronic medical record text but have nothing to do with the content expression;
[0033] 2) Using the Word2Vec model technology, the electronic medical record text vocabulary is mapped to a vector to provide a basic semantic model for subsequent classif...
Embodiment 2
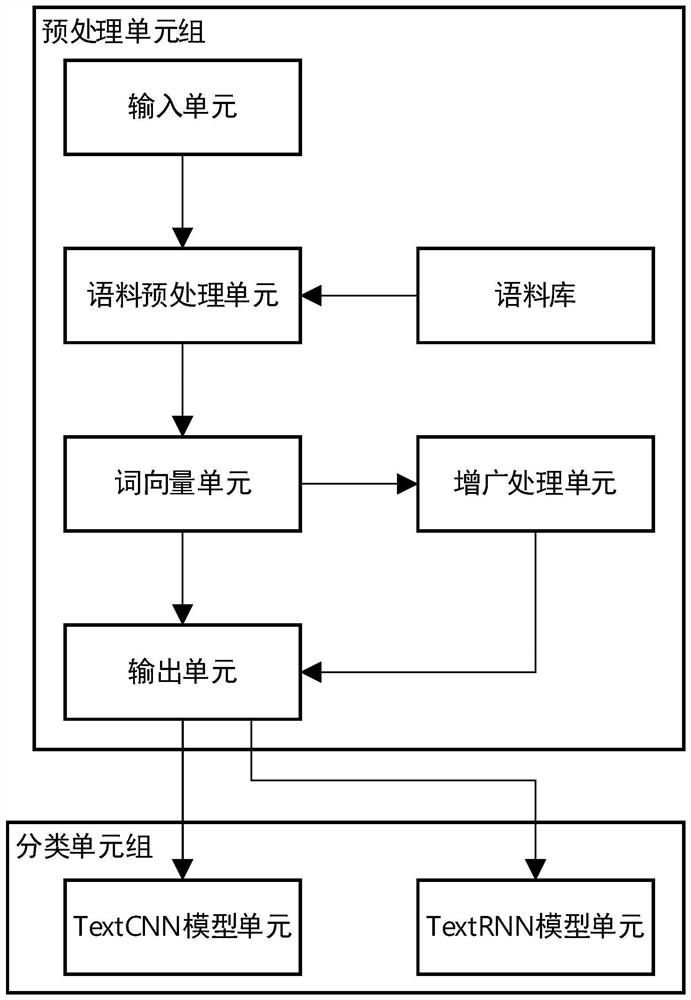
[0038] like figure 2 A system for auxiliary diagnosis based on electronic medical record text is shown, including a preprocessing unit group and a taxonomic unit group;
[0039] The taxon group includes TextCNN model units and TextRNN model units;
[0040] The preprocessing unit group obtains and preprocesses a variety of electronic medical record texts, and sends the processing results of the medical record texts obtained from a single consultation activity to the TextCNN model unit, and sends the medical record texts obtained from multiple observations to the TextRNN model unit .
[0041] The preprocessing unit group includes input unit, corpus preprocessing unit, word vector unit, augmentation processing unit, and output unit;
[0042] Input unit: get the text of the electronic medical record, and mark the type of the text of the electronic medical record;
[0043] Corpus preprocessing unit: based on the stop word corpus, delete content-irrelevant words in the electroni...
Embodiment 3
[0054] Another realization of the integration of the above schemes is to obtain more accurate auxiliary diagnosis conclusions through the analysis of various clinical data generated during the fusion diagnosis process. Specifically, the following three stages are adopted:
[0055] Phase 1: Data Preprocessing
[0056] Step 1: Electronic medical record text data preprocessing
[0057] Based on the stop word corpus, the words that appear frequently in the electronic medical record text but have nothing to do with the content expression are removed;
[0058] Using the Word2Vec model technology, the electronic medical record text vocabulary is mapped to a vector to provide a basic semantic model for subsequent classification tasks;
[0059] Based on the above basic semantic model, apply the Skip-Gram algorithm to generate word vectors;
[0060] Perform data augmentation processing on electronic medical record text data:
[0061] Aiming at the problem that the text data of elect...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More