

Adaptive emotion expression speaker facial animation generation method and electronic device
A speaker and face technology, applied in the field of human-computer interaction, can solve the problems of cold face animation, poor effect, and sense of distance, and achieve the effect of ensuring diversity, continuity, and naturalness.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0046] The present invention will be described in detail below in conjunction with the accompanying drawings. It should be noted that the described embodiments are for the purpose of illustration only, and do not limit the scope of the present invention.
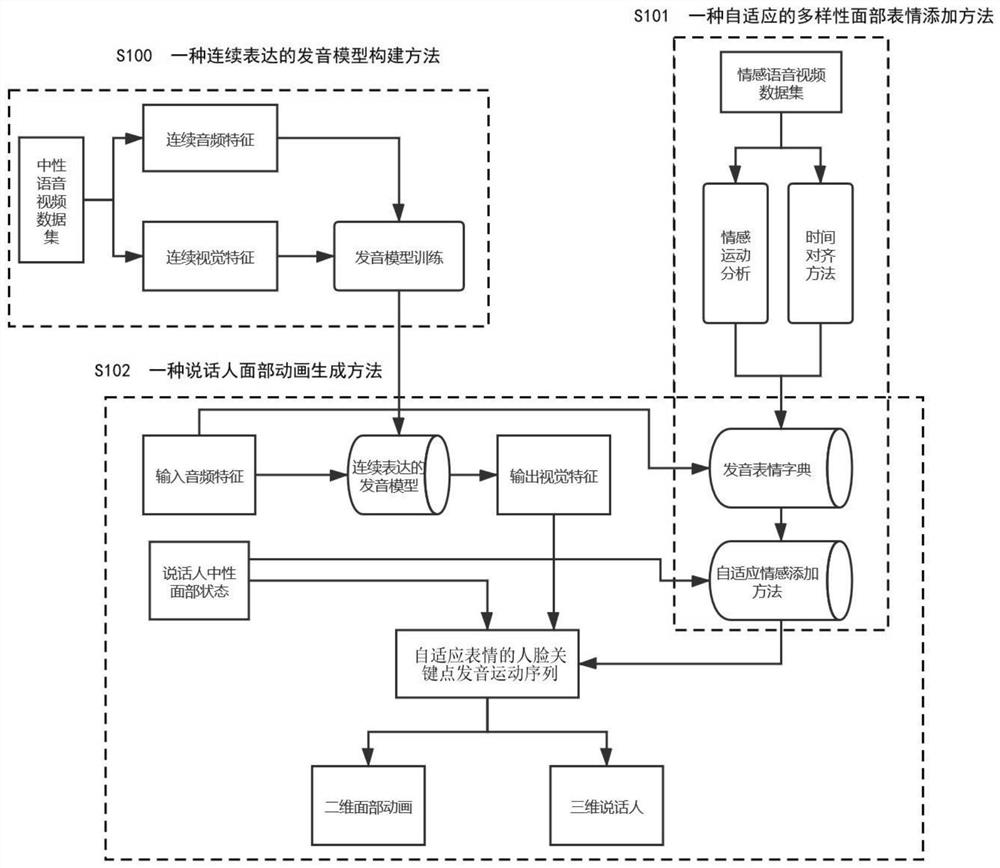
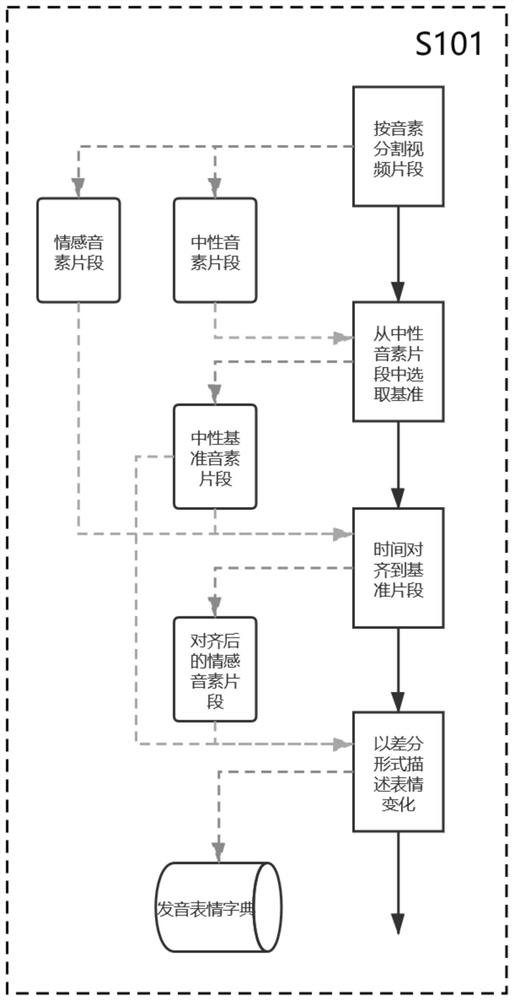
[0047] The invention discloses a method for generating a speaker's facial animation for adaptive emotional expression. The structural diagram of the method is as follows figure 1 shown.
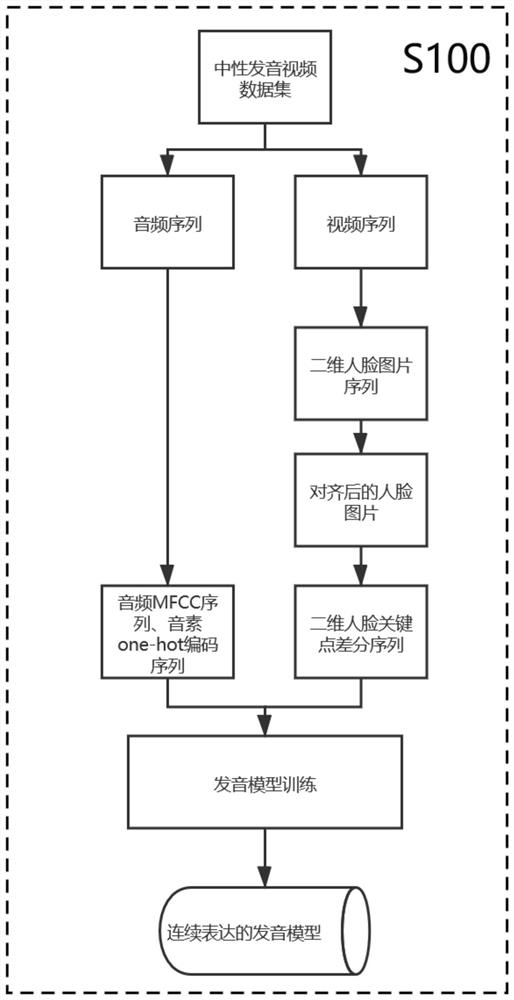
[0048] S100, a continuous expression pronunciation model construction method.
[0049]The pronunciation model is a phoneme-level pronunciation fitting model of cross-modal audio-visual nonlinear mapping, which establishes the mapping relationship between continuous input audio features and output visual features. Before training the pronunciation model, continuous audio features and visual features are obtained from the neutral pronunciation video dataset. The audio features include phoneme features and spectral features, and the visual ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More