

New word discovery-based cross-domain Chinese word segmentation system and method
A new word discovery, Chinese word segmentation technology, applied in semantic analysis, instruments, biological neural network models, etc., can solve problems such as time-consuming, unrealistic, and difficult to achieve good results in cross-domain Chinese word segmentation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0079] The structural block diagram of the cross-domain Chinese word segmentation system based on new word discovery disclosed in this embodiment is as follows: figure 1 As shown, it is composed of a new word discovery module, an automatic tagging module and a cross-domain word segmentation module. The new word discovery module, the automatic tagging module and the cross-domain word segmentation module are connected in sequence, and are used to mine data from unlabeled target domain corpus. New words, automatic labeling of unlabeled target domain corpus, and training of neural networks for cross-domain Chinese word segmentation.
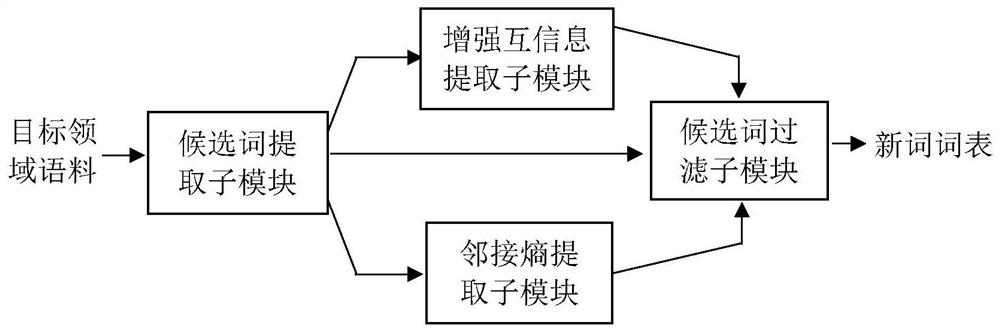
[0080] In the present embodiment, the block diagram of the new word discovery module structure is as figure 2 As shown, it is composed of the candidate word extraction submodule, the enhanced mutual information extraction submodule, the adjacency entropy extraction submodule and the candidate word filtering submodule, wherein the candidate word extr...
Embodiment 2
[0087] This embodiment provides a cross-domain Chinese word segmentation method based on the cross-domain Chinese word segmentation system based on new word discovery, and adopts the following steps to realize the word segmentation of corpus in different fields:
[0088] Step S1: Use the new word discovery module to mine the vocabulary of new words in the target field from the corpus. In the above step S1, use the new word discovery module to mine the new word vocabulary of the field from the target field corpus, including the following steps:
[0089] Step S1.1: Use the candidate word extraction sub-module to extract all candidate words whose length does not exceed n from the unlabeled target domain corpus.
[0090] In this embodiment, the candidate word extraction submodule splits the corpus according to non-Chinese characters, sets the maximum candidate word length to 6, and extracts all candidate words whose length does not exceed 6 from the sentences of the segmented corp...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More