

Distributed file system and method based on multi-client collaboration and client
A distributed file, multi-client technology, applied in the field of distributed file systems, can solve the problems of slow metadata access, slow real-time file writing, and inability to fully access real-time data from multiple clients, saving bandwidth and speeding up query access. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
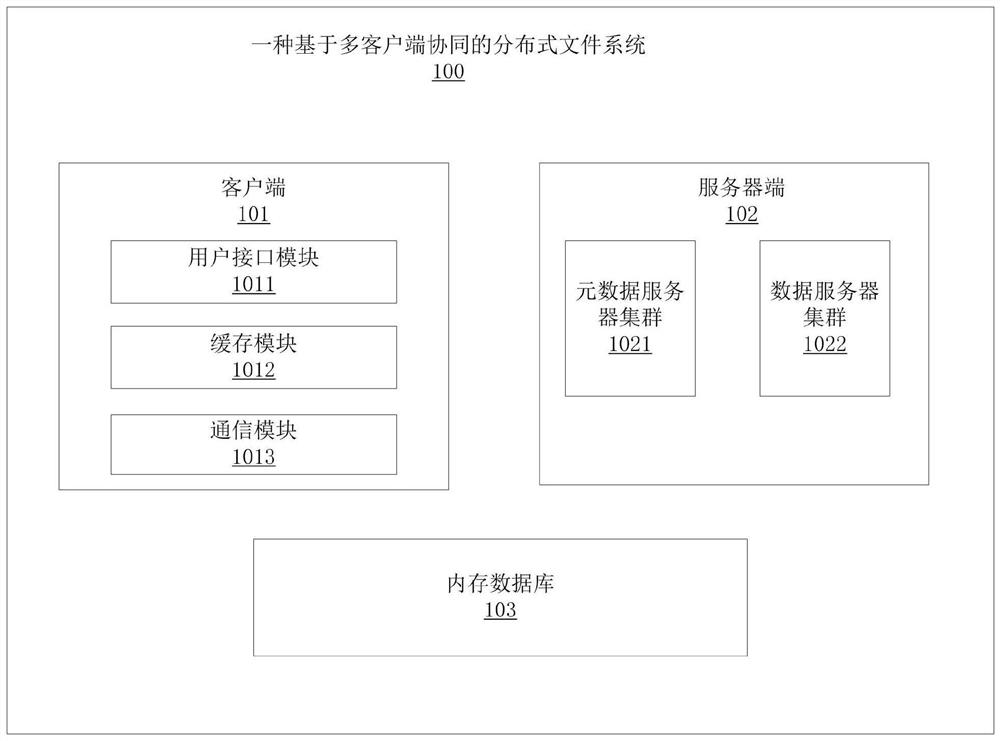
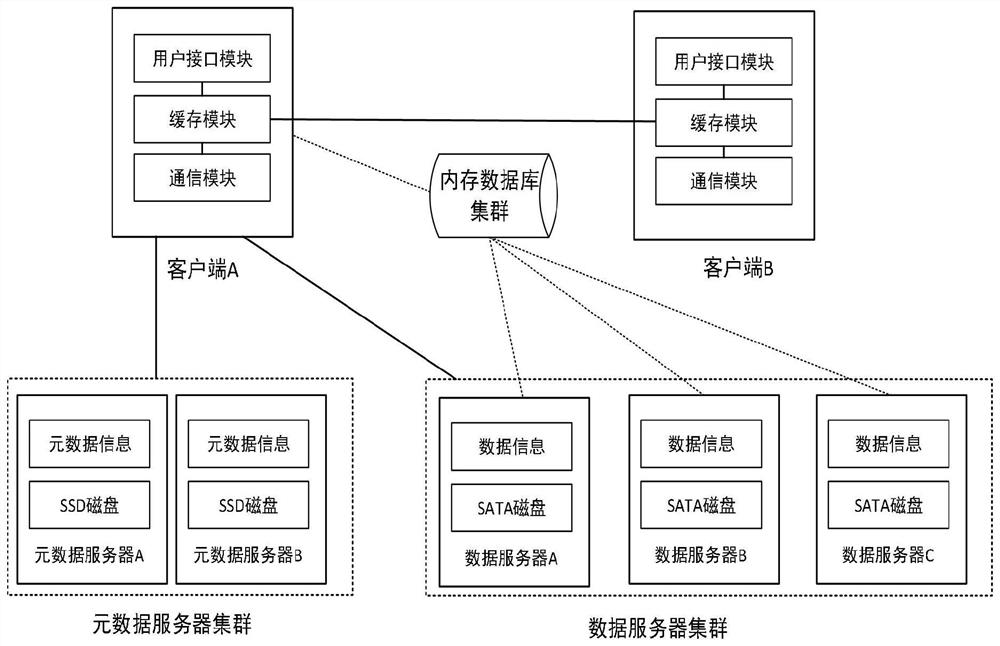
[0067] Such as figure 1 and figure 2 As shown, a distributed file system 100 based on multi-client collaboration includes: a server 102, a client 101, and an in-memory database 103; the server 102 includes: a metadata server cluster 1021 and a data server cluster 1022, the The metadata server cluster 1021 and the data server cluster 1022 separately provide independent volumes for the client 101 to mount and use; the client 101 includes: a user interface module 1011, a caching module 1012 and a communication module 1013. The files are written in blocks; the memory database 103 is used to: record the data block block information and distribution information of the files uploaded to the data server.
[0068] Among them, the metadata server cluster 1021 is mainly used to maintain metadata and is responsible for controlling functions such as garbage collection and load balancing. The metadata server uses SSD disks to speed up data access; the data server cluster 1022 is responsib...
Embodiment 2
[0073] In practical applications, the implementation of data upload based on the multi-client 101-based distributed file system is as follows:
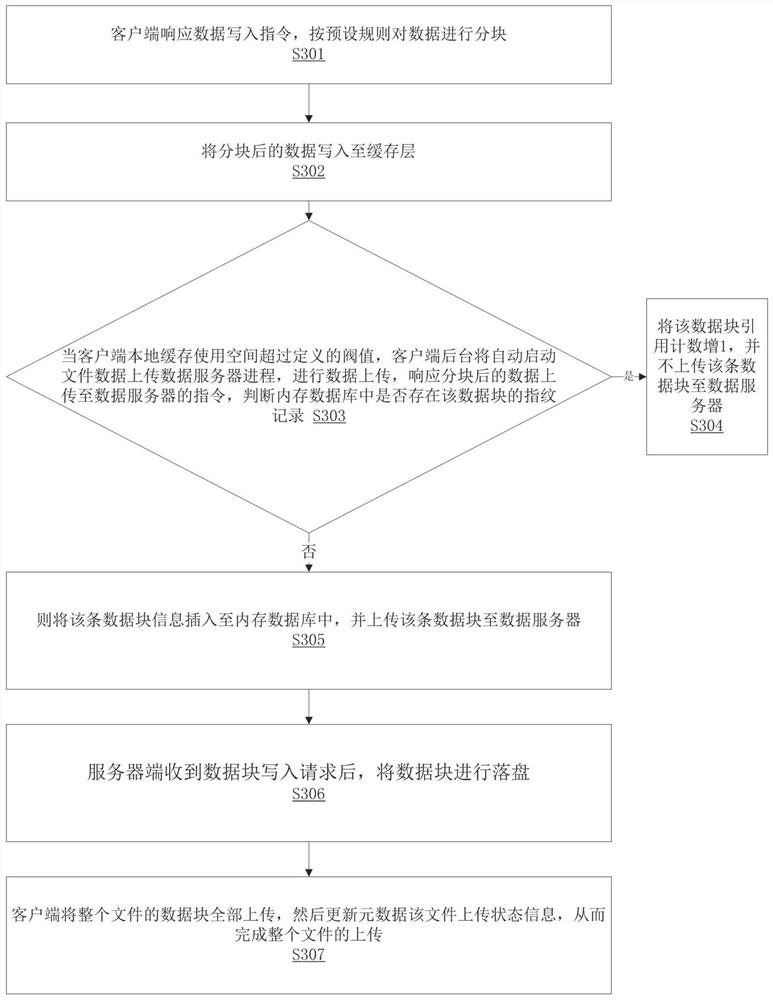
[0074] When there is data to be written, at first through the user interface module 1011 of the client 101, the write request is sent to the metadata server cluster 1021, such as the owner of the file, time, and file size, creating the file client 101, and uploading the file Data server completion status and other information. It should be noted that the file size is only the information recorded in the extended attribute of the file, without specific file data, and does not occupy disk space. After receiving the request, the metadata server cluster 1021 records the metadata information of the file, and returns a confirmation message to the client 101. After the client 101 receives the confirmation message, it starts to write data. First, the data is written into the local cache module 1012 in blocks (such as 4M). After the data is w...
Embodiment 3
[0079] In practical applications, the implementation of data reading based on the multi-client 101-based distributed file system is as follows:
[0080] When the client 101 reads data, it first accesses the metadata server to obtain the identification information of the file. Afterwards, through the identification information of the file, the client 101 queries the memory database 103, obtains the current block information of the file, and obtains the information of the data server where the data block is located, and then the client 101 establishes a link with the data server where the data block of the file is located, and finally obtains All data blocks. Afterwards, the data is synthesized on the client 101 to complete the pulling of the entire file.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More