Query task optimization method based on science and technology consultation large-scale graph data
A technology of task optimization and query optimization, which is applied in the direction of electronic digital data processing, special data processing applications, digital data information retrieval, etc., can solve the problems of high communication cost and processing overhead and inapplicability of servers, so as to improve flexibility and reduce Complexity, the effect of improving query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
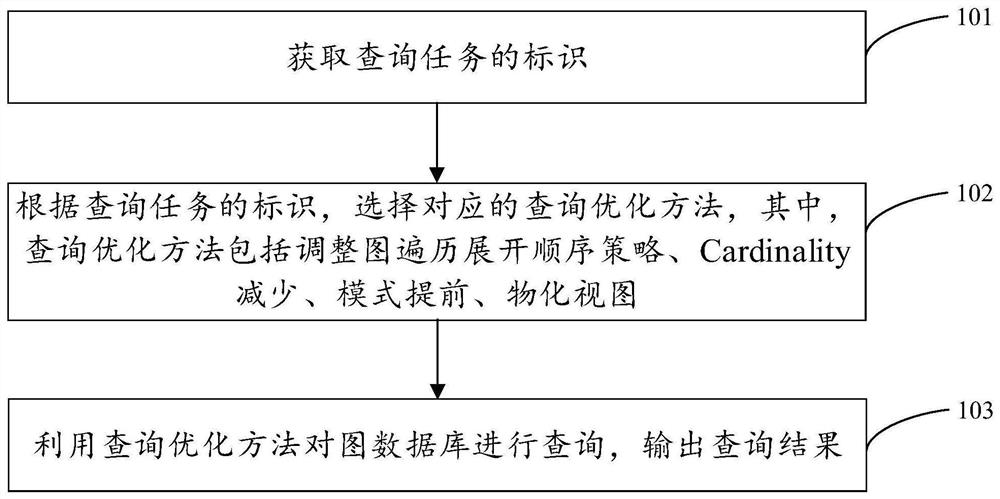
[0025] figure 1 It is a schematic flowchart of a query task optimization method based on large-scale graph data for scientific and technological consulting provided according to an embodiment of the present application, as shown in figure 1 As shown, the method may include:
[0026] Step 101. Obtain the identifier of the query task.
[0027] It should be noted that, in the embodiments of the present disclosure, the query task may include organization, talent, and industry chain. Among them, in the embodiment of the present disclosure, the organization can be the ID of the company, and the talent can be the personnel
[0028] Wherein, in the embodiments of the present disclosure, the identifier of the query task may be acquired according to the content of the query task. As an example, in the embodiment of the present disclosure, assuming that the query task is to view the company and patent information associated with a certain person, the identifier of the query task is ob...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



