Agent training method based on DQN
A training method and agent technology, applied in the field of DQN-based agent training, can solve problems such as reducing execution efficiency, accelerating network convergence, and long time resources, and achieving the effect of reducing time resources, improving immediacy, and speeding up execution efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
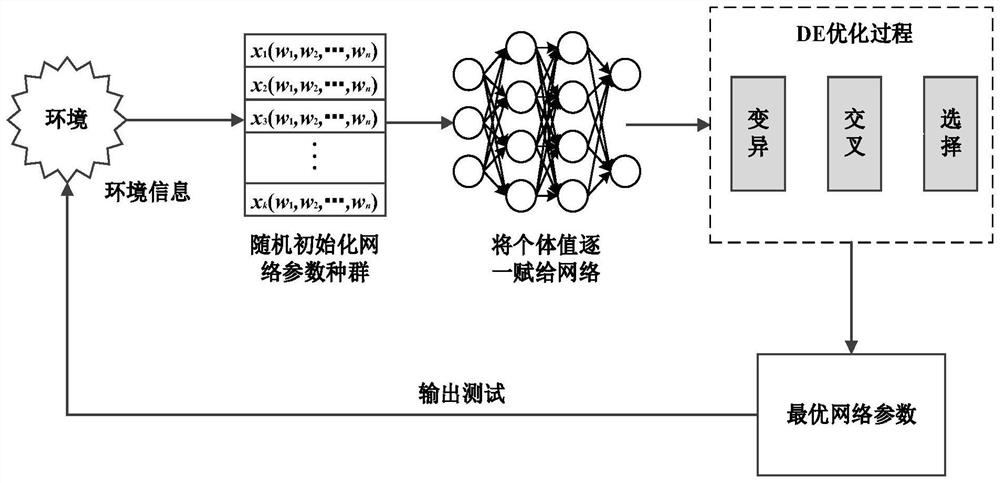
[0048] Please refer to figure 1 and figure 2 , figure 1 It is a schematic diagram of a DQN-based agent training method provided by an embodiment of the present invention; figure 2 It is a schematic diagram of a DQN network parameter optimization process provided by an embodiment of the present invention. As shown in the figure, the DQN-based agent training method of this embodiment includes:
[0049] S1: Randomly initialize the network parameters of the DQN network to obtain several initial DQN networks;
[0050] The DQN network consists of three parts: input layer and hidden layer, hidden layer and hidden layer, hidden layer and output layer. Since reinforcement learning is an unsupervised learning problem, each network output is also the network input of the next iteration, and The parameters are updated by gradient descent.
[0051] In this embodiment, the network parameter encoding method of the DQN network adopts floating-point encoding, specifically, the network p...
Embodiment 2
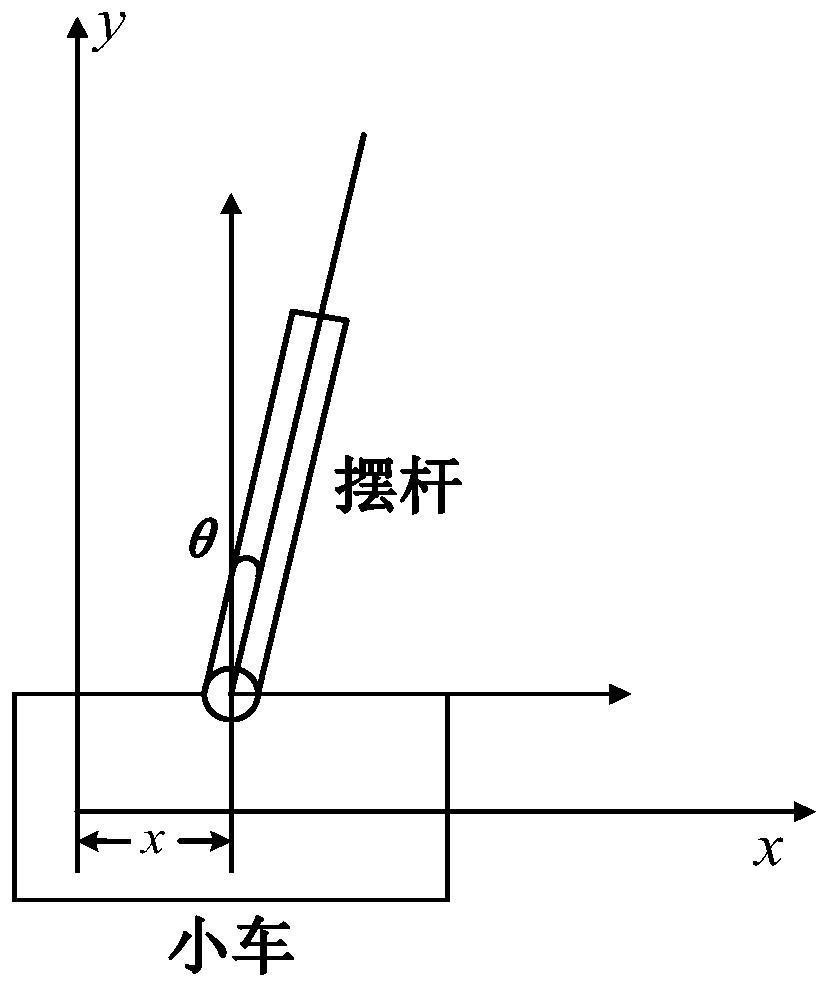
[0108] In this embodiment, the effect of the DQN-based agent training method in Embodiment 1 is verified and explained through a specific case. See image 3 , image 3 It is a structure diagram of a test case model provided by the embodiment of the present invention.
[0109] The experimental environment used in the test case of this embodiment is the open classic control model "CartPole-v1" under OpenAI Gym. The present invention improves the original model on the basis of it, and uses Matlab2018b for simulation. Among them, Table 1 and Table 2 give the parameter names and value ranges involved in the model.
[0110] Table 1 CartPole-v1 status (State) information
[0111]
[0112]
[0113] Table 2 CartPole-v1 action (Action) information
[0114]
[0115] This embodiment redefines the state variable (State), action space (Action), movement space of the inverted pendulum trolley, range of balance angle of the inverted pendulum and rendering of the picture of the m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com