

Video encoding apparatus and method
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
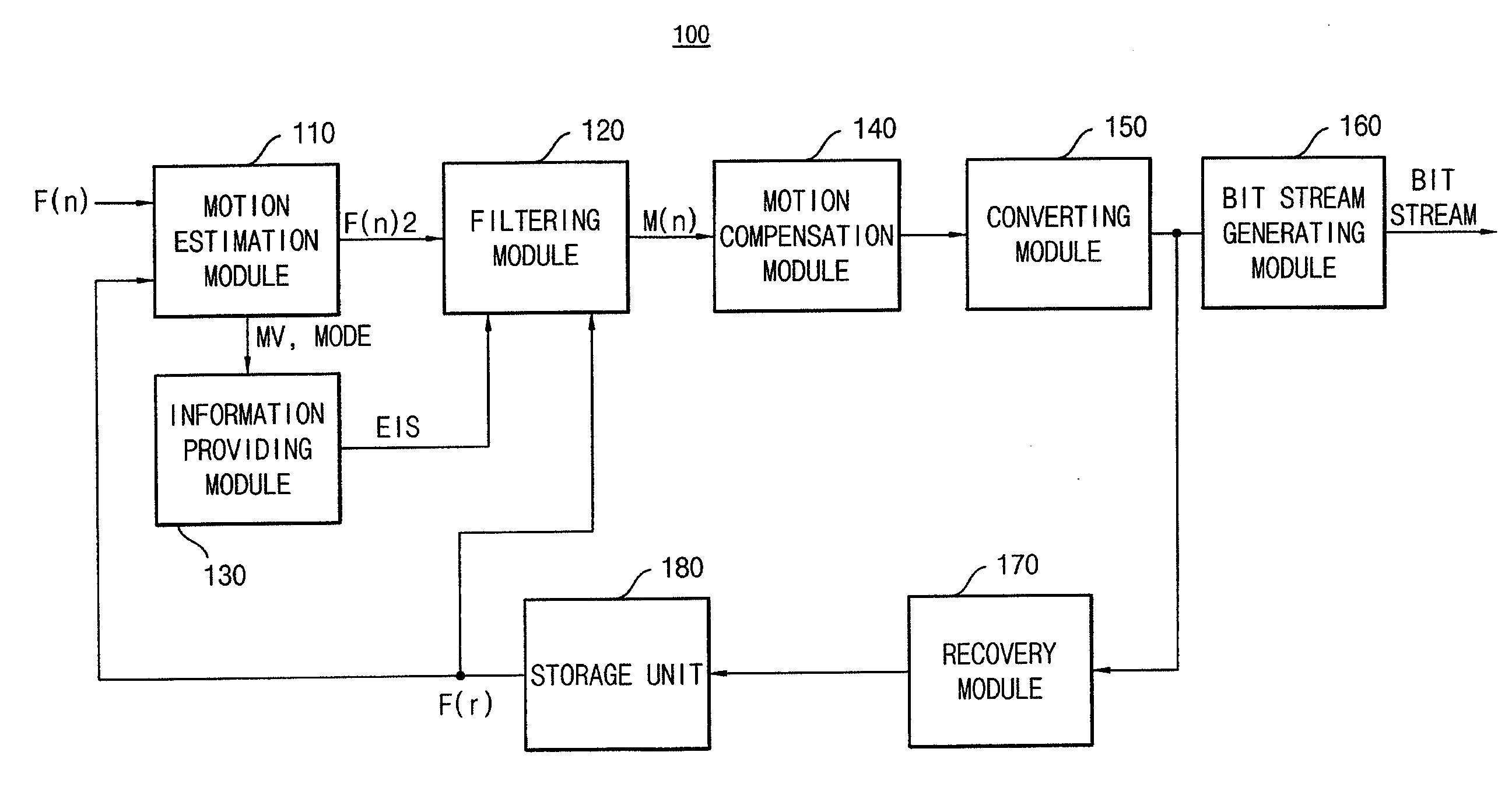
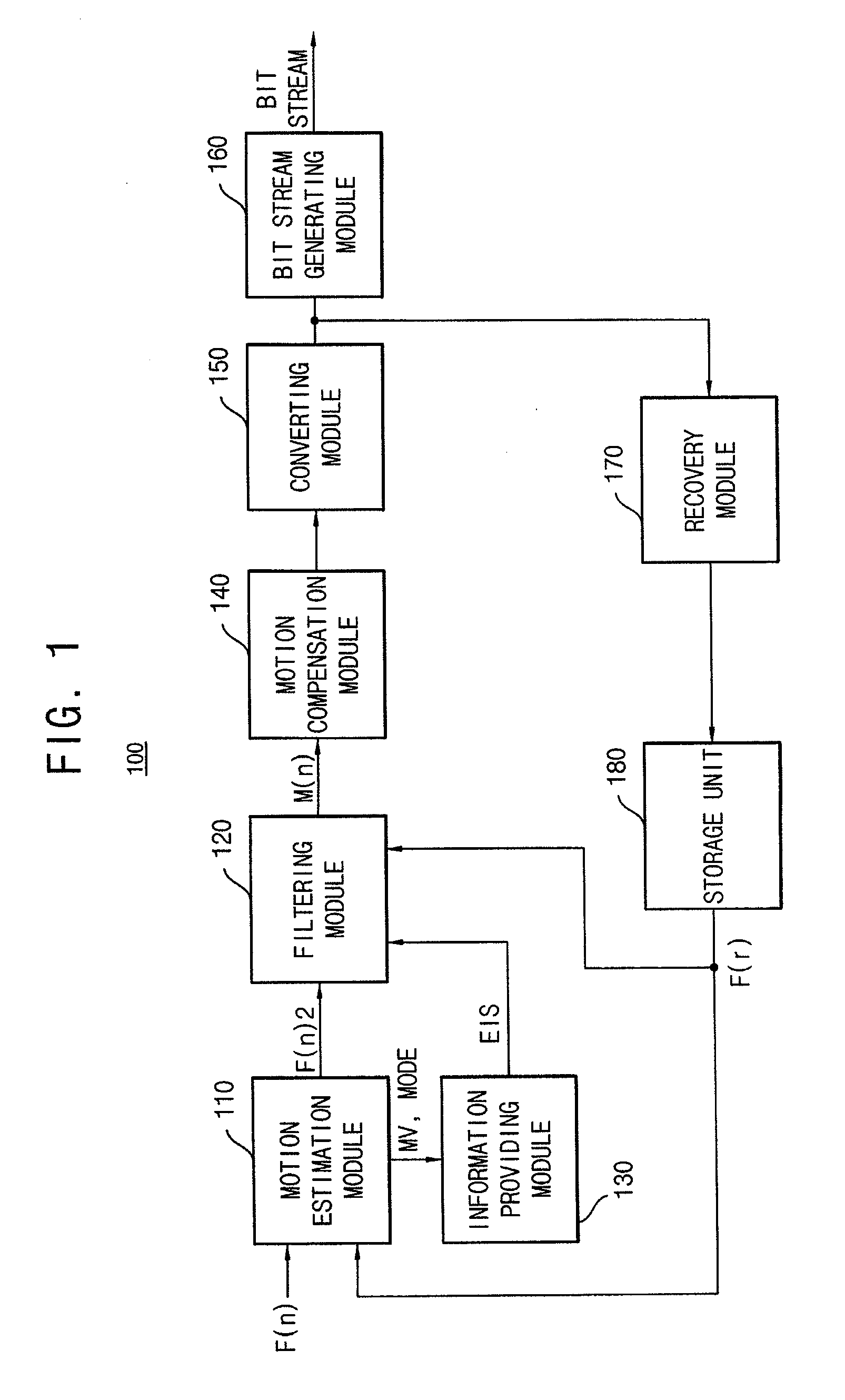
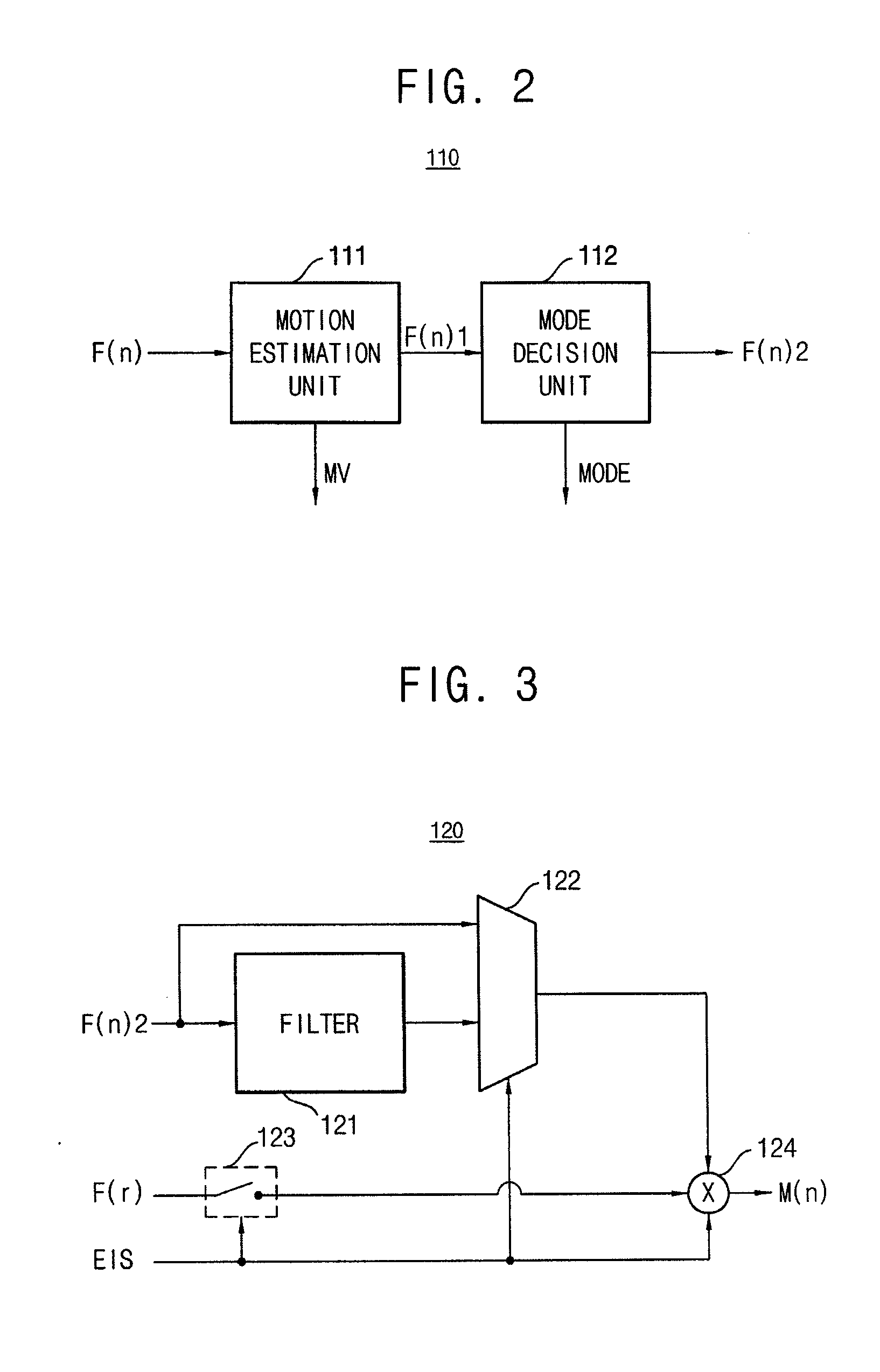
Embodiment Construction
[0037]Korean Patent Application No. 10-2009-0103890, filed on Oct. 30, 2009, in the Korean Intellectual Property Office, and entitled: “Video Encoding Apparatus and Method,” is incorporated by reference herein in its entirety.
[0038]Various example embodiments will be described more fully hereinafter with reference to the accompanying drawings, in which some example embodiments are shown. The present inventive concept may, however, be embodied in many different forms and should not be construed as limited to the example embodiments set forth herein. Rather, these example embodiments are provided so that this disclosure will be thorough and complete, and will fully convey the scope of the present inventive concept to those skilled in the art. In the drawings, the sizes and relative sizes of layers and regions may be exaggerated for clarity. Like numerals refer to like elements throughout.
[0039]It will be understood that, although the terms first, second, third, etc. may be used herein...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More