

Webpage data extracting method based on extensible language query
A web page data and language query technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of reduced extraction efficiency, difficulty in expressing missing attributes, and low extraction efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0080] Below in conjunction with accompanying drawing and embodiment the present invention is described in further detail:
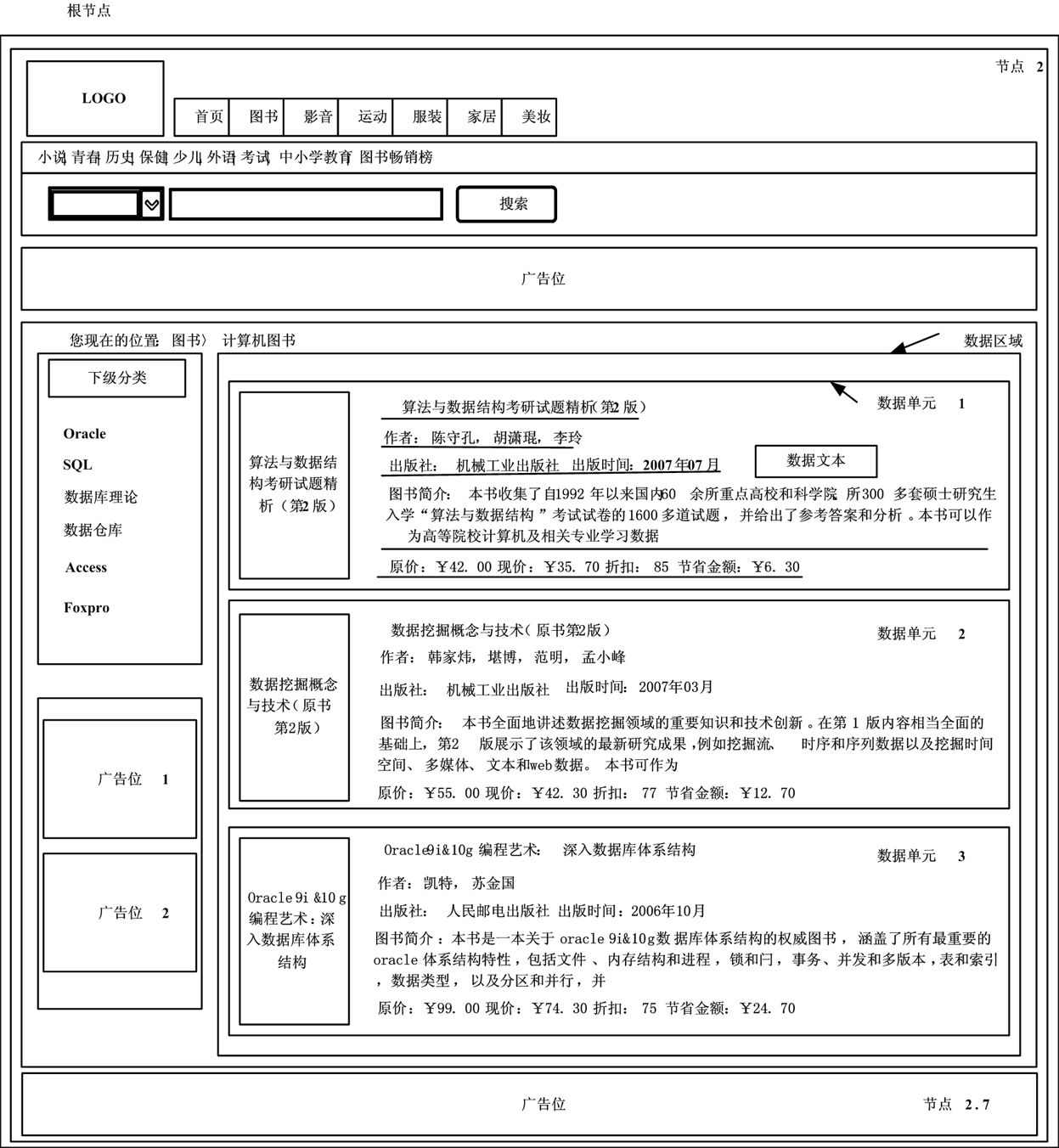
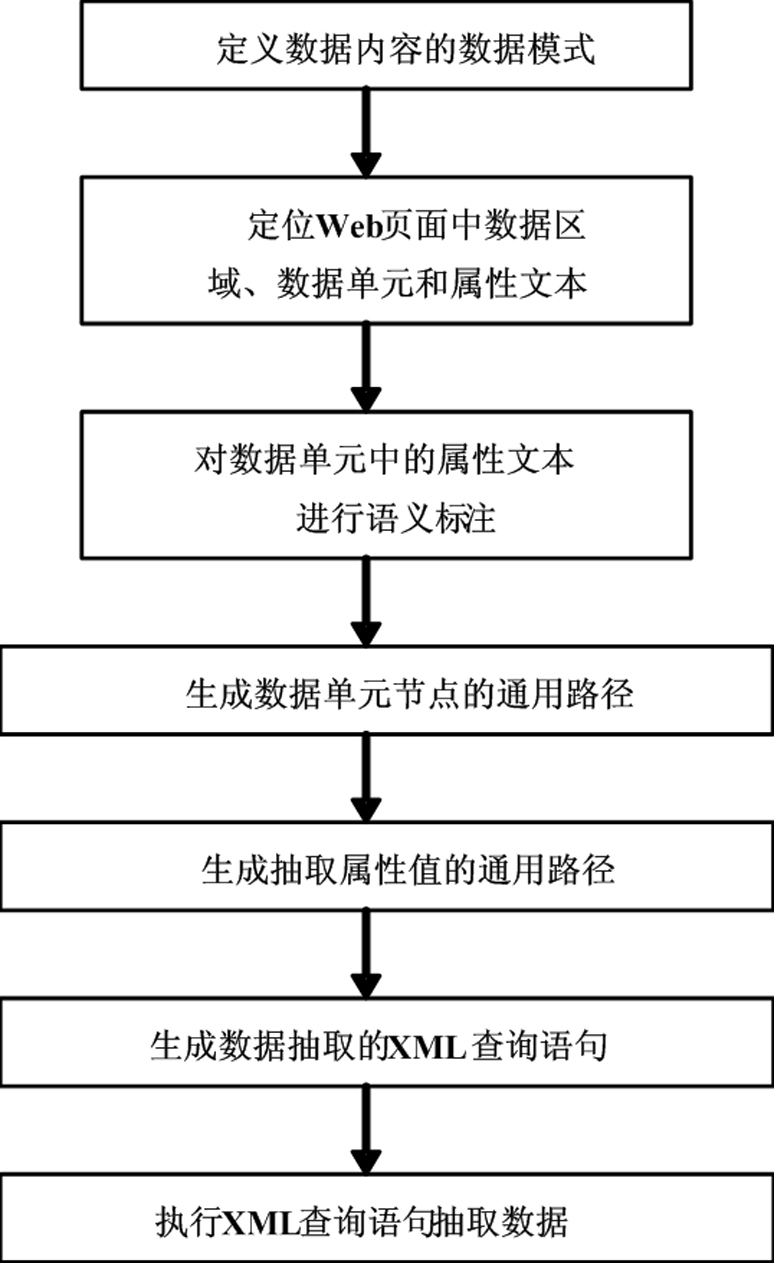
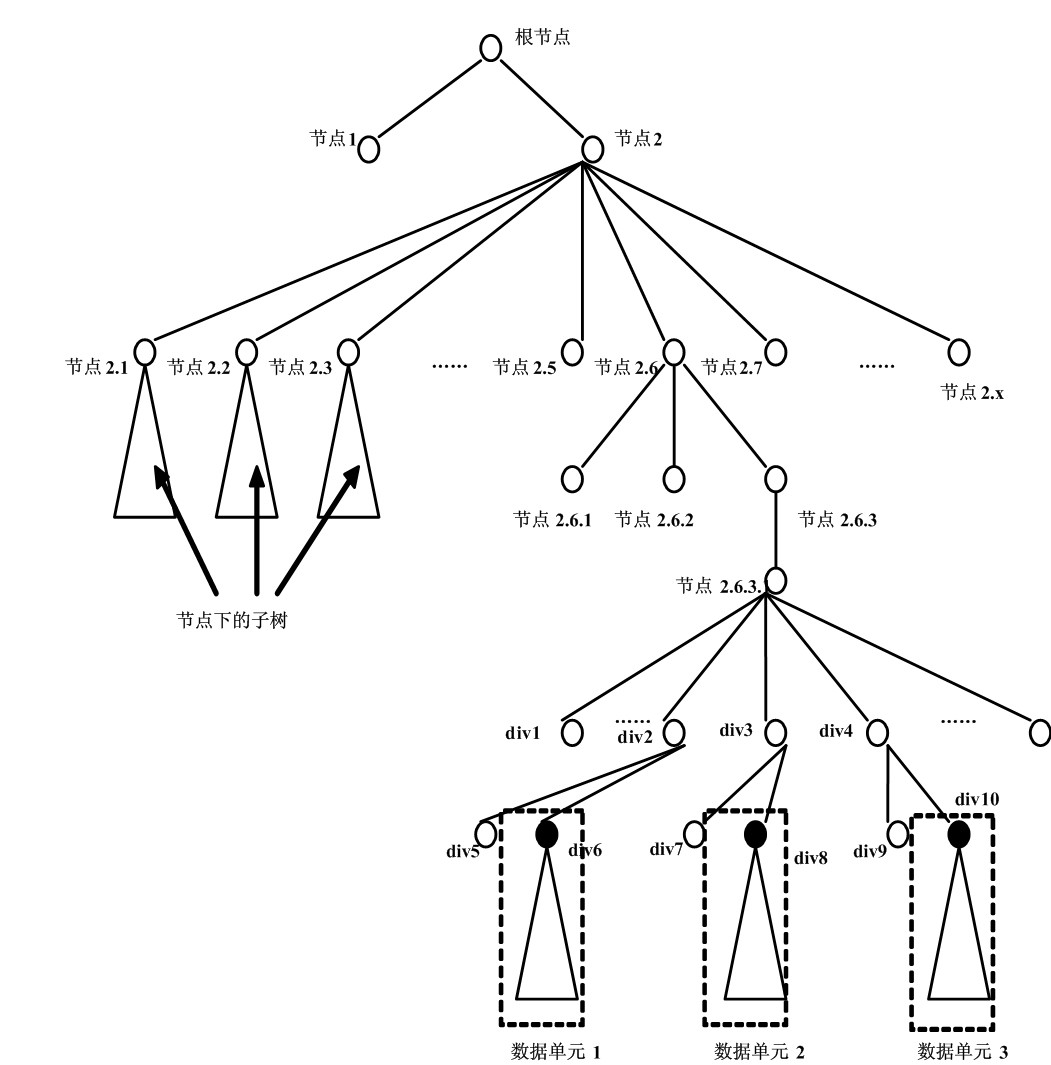
[0081] figure 1 For a Web data page of a certain electronic book selling website, the flow process of the method of the present invention is as follows figure 2 As shown, the steps are as follows:
[0082] Step 1: Determine the corresponding data pattern S when extracting data content from the web page, where the data entity name E is "book", and the attribute names and attribute data types contained in the attribute collection are shown in Table 1:
[0083] Table 1 shows the attribute names and attribute data types contained in the data entity "Book"
[0084]
attribute 1
attribute 2
attribute 3
attribute 4
attribute 5
attribute 6
attribute 7
attribute 8
attribute 9
name
book title
author
publishing house
Published date
book introduction
original price
D...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More