Method and device for reading RAID1 (Redundant Array of Inexpensive Disk 1) equipment
A technology for reading devices and equipment, which is used in instruments, electrical digital data processing, input/output to record carriers, etc., to achieve the effect of shortening response time and improving reading performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
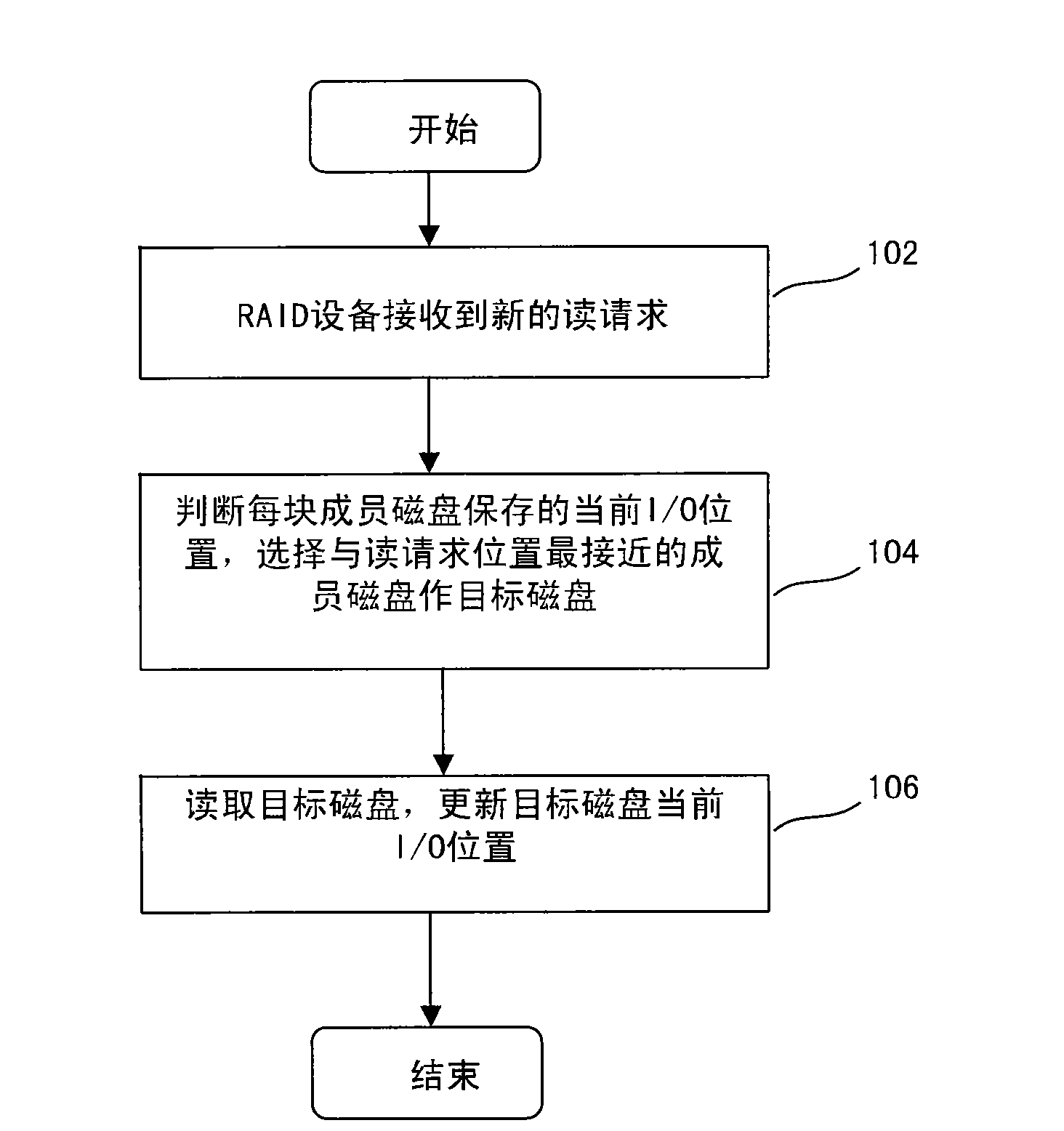
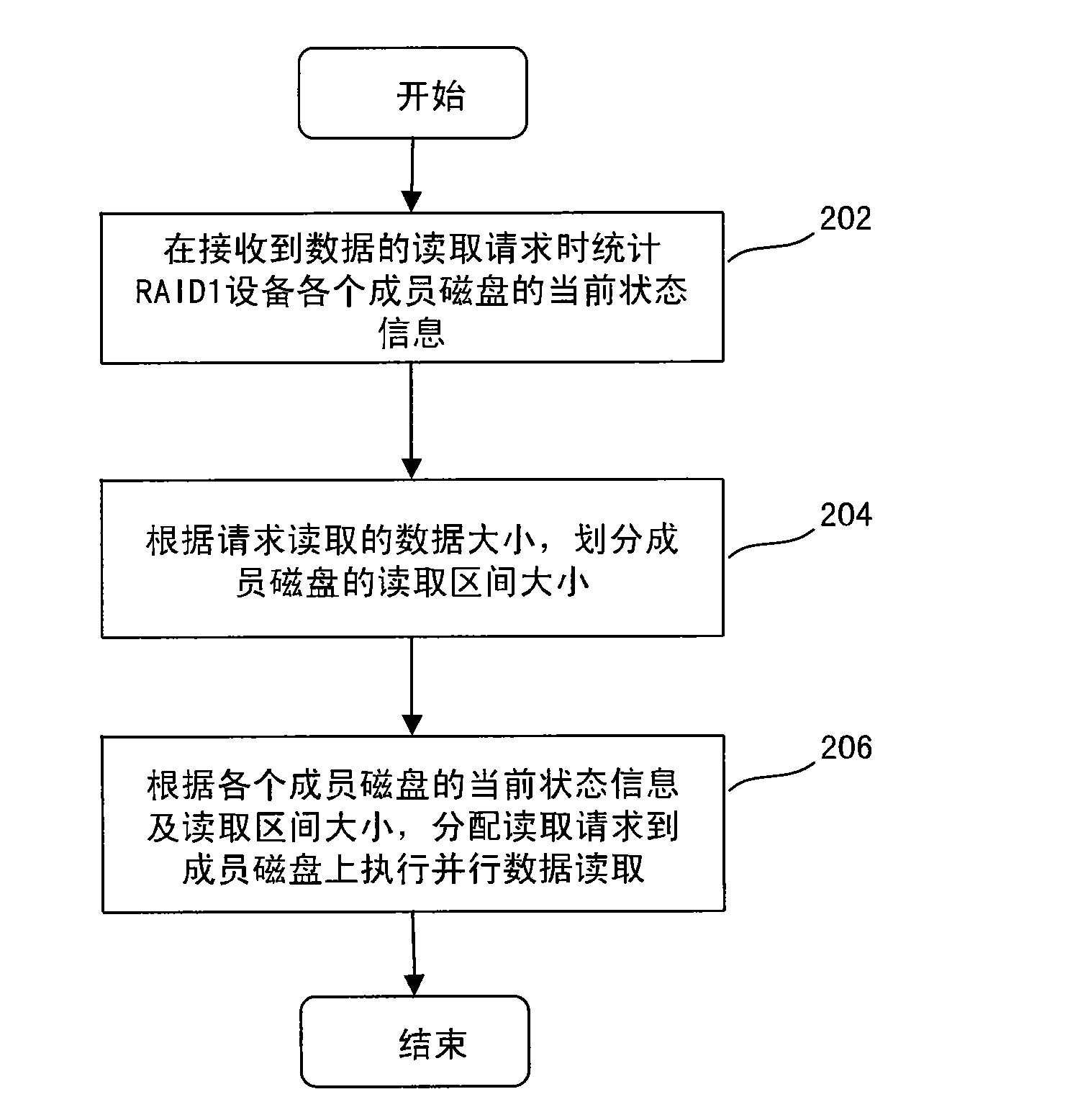
[0022] The following describes in detail the embodiments of the present invention, examples of which are illustrated in the accompanying drawings, wherein the same or similar reference numerals refer to the same or similar components or components having the same or similar functions throughout. The embodiments described below with reference to the accompanying drawings are exemplary and are only used to explain the present invention, but not to be construed as a limitation of the present invention.
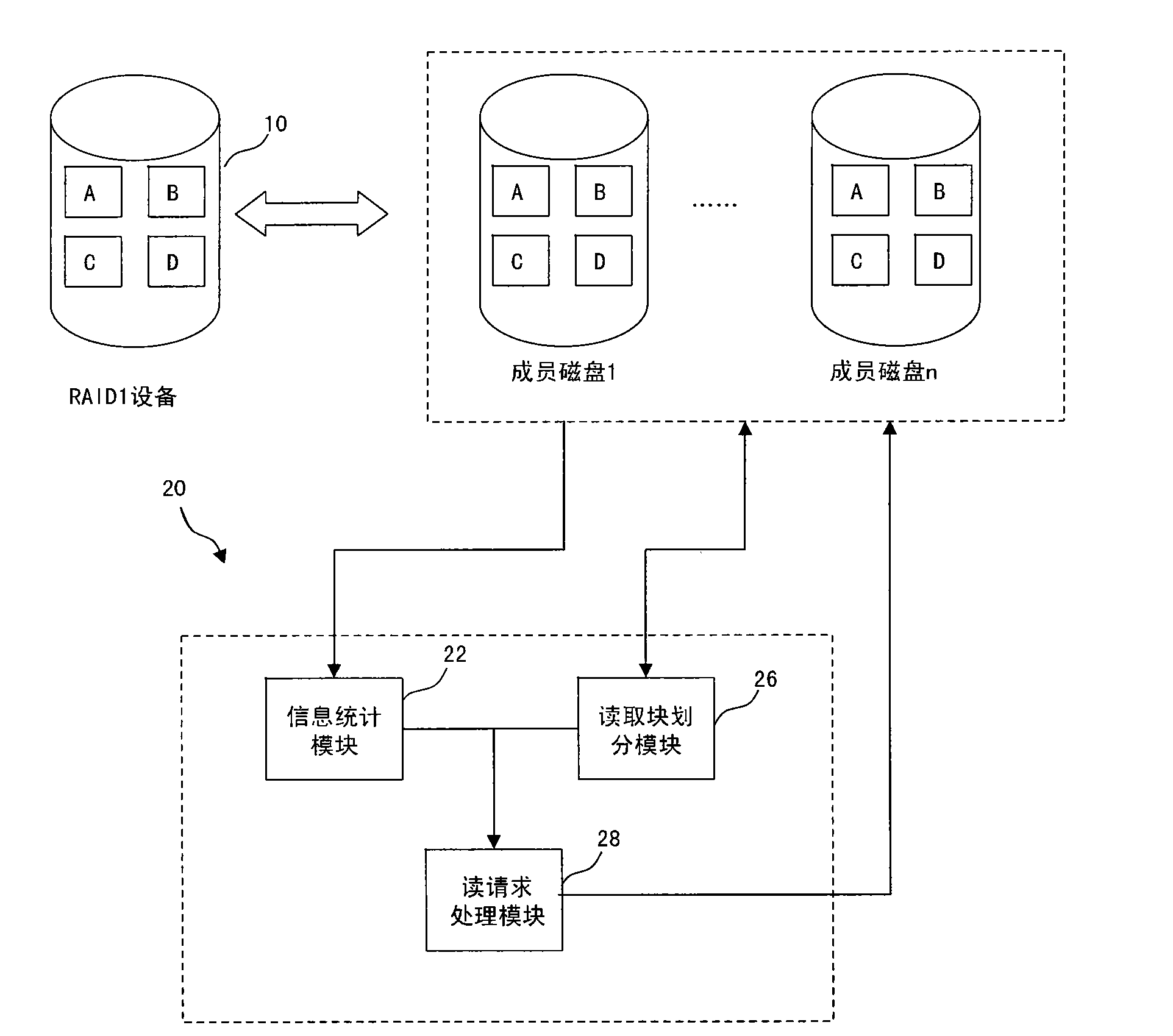
[0023] First refer to figure 2 , which shows a schematic structural diagram of a reading device of a RAID1 device according to an embodiment of the present invention. like figure 2 As shown, for a RAID1 device 10 composed of a plurality of member disks, member disk 1, member disk 2, . . . Block dividing module 26 and read request processing module 28 . The information statistics module 22 collects statistics on the current status information of each member disk 1-n included ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More