Method and system for parallel batch importing of data into read-only query system
A read-only query and query system technology, applied in the field of cloud computing, can solve problems such as low efficiency, large consumption of CPU and memory resources, and impact on online system service throughput, so as to enhance service capabilities, reduce switching time, and avoid computing The effect of resource consumption
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

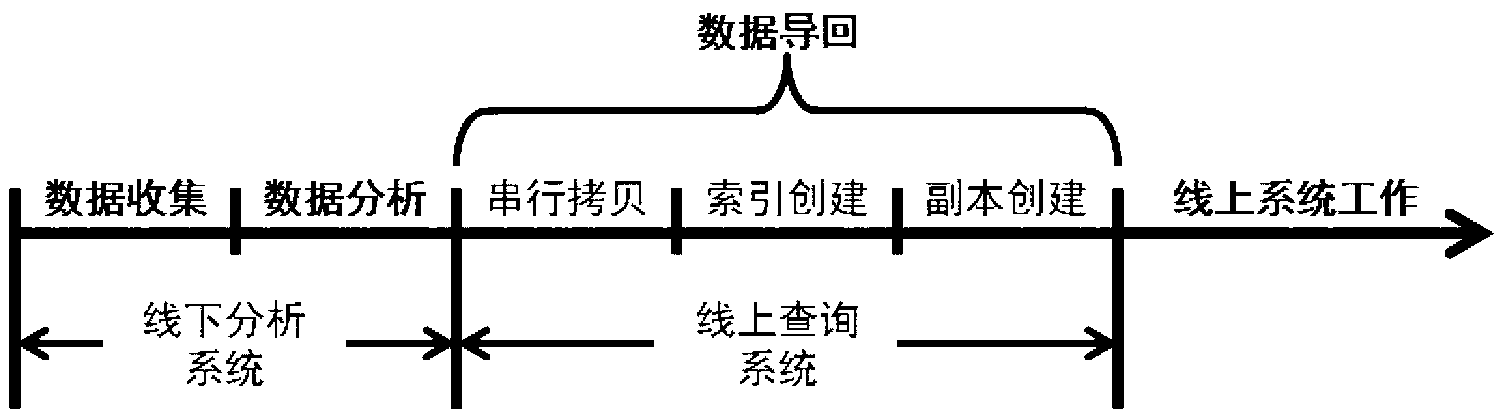
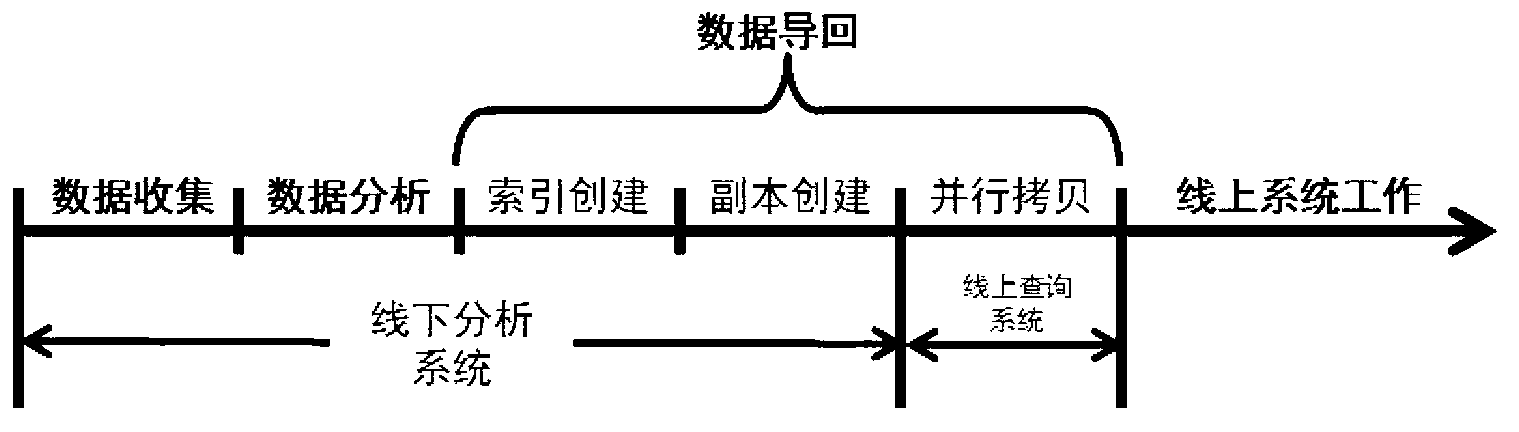
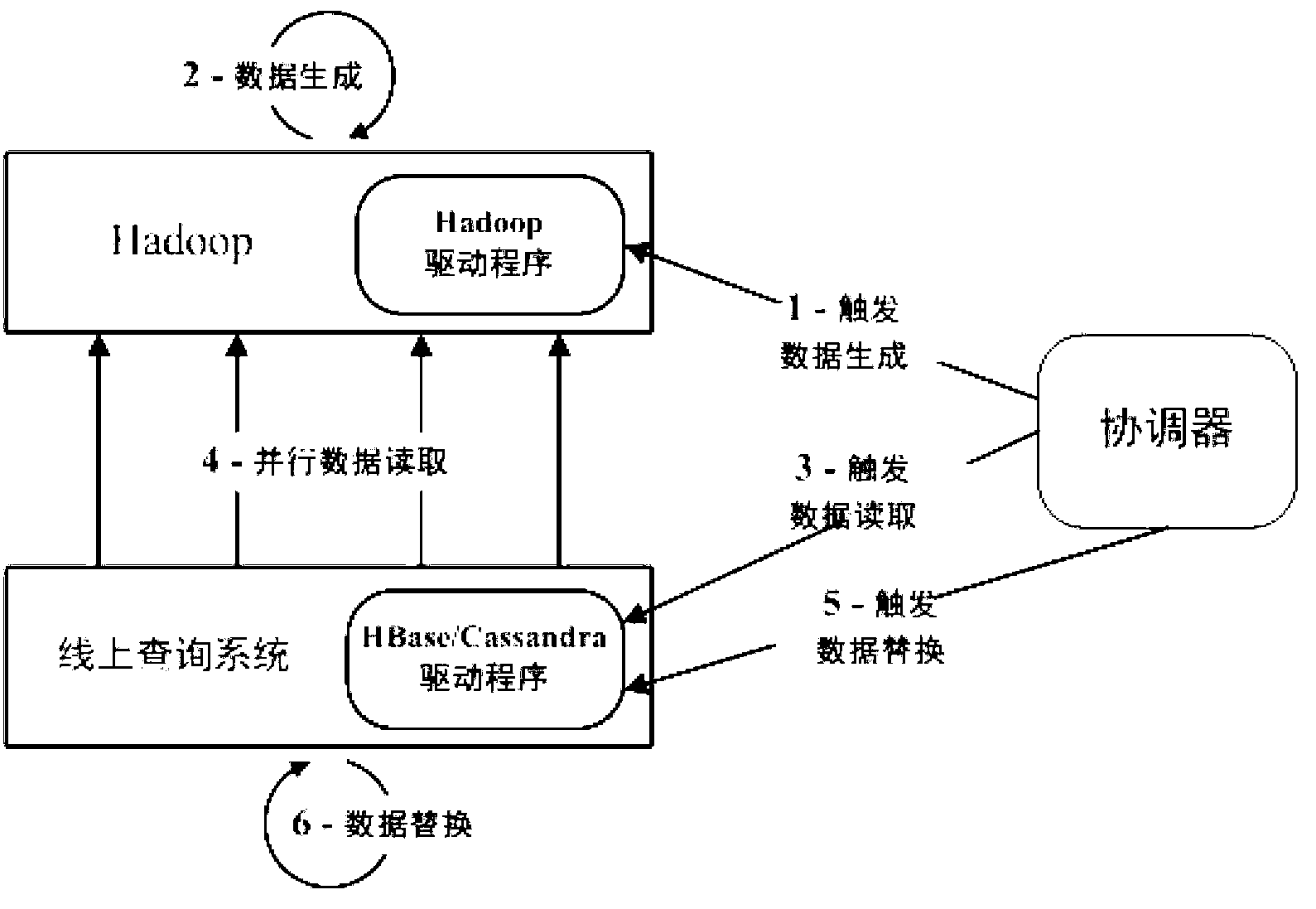
Examples
Embodiment 1
[0059] The original data of 256MB-1280MB is processed by Cassandra and MySQL respectively, and the timing starts. The data after the data is completely imported back to the Cassandra and MySQL online systems and provides services.
[0060] Such as Figure 6 Shown is a schematic diagram of the result comparison of Cassandra and MySQL as the online system data size and processing time in an embodiment of the method of data parallel batch import into the read-only query system of the present invention. The Cassandra system deployed with the present invention takes less time to process and import data than MySQL at various data scales, and because of parallel processing, the problem of MySQL processing speed reduction due to data accumulation does not occur.
Embodiment 2
[0062] On the basis of Embodiment 1, the running time of the online system under high load conditions is counted (it is considered that the CPU load is above 80% as high load conditions).
[0063] Such as Figure 7 Shown is a schematic diagram of the result comparison of Cassandra and MySQL as the online system data size and CPU high load time in an embodiment of the method of data parallel batch import into the read-only query system of the present invention. Cassandra's high load ratio is less than 20%. According to the experimental analysis, the high load mainly occurs in the parallel data import phase, and 20% of the time has little impact on the online system; because MySQL uses the online system to build indexes, the system has a high load. The ratio is higher than 80%, that is, the entire data processing stage has a relatively large impact on the online system.
[0064] The above embodiments illustrate that the present invention improves the efficiency of the entire da...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More