

Hadoop-based fast neighborhood rough set attribute reduction method
A neighborhood rough set and attribute reduction technology, applied in special data processing applications, instruments, electrical digital data processing, etc., to improve analysis efficiency, reduce time complexity, and reduce output
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


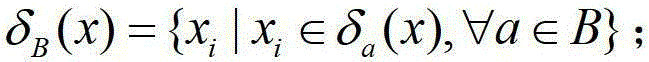
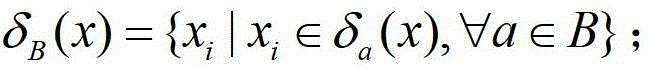
Examples
Embodiment Construction
[0031] In order to achieve the above object, the present invention proposes a Hadoop-based neighborhood rough set fast attribute reduction method, comprising the following steps:
[0032] a) Set up a distributed platform based on Hadoop: set up the HDFS distributed file system and the MapReduce parallel programming model; the HDFS distributed file system adopts a master-slave structure system, consisting of a manager and multiple workers, and the manager manages files The namespace of the system maintains the file system tree and all files and directories in the entire tree. The worker is the working node of the file system, stores and retrieves data blocks as needed, and periodically sends a "heartbeat" report to the manager. If the management If the operator does not receive the worker's "heartbeat" report within the specified period of time, the manager starts a fault-tolerant mechanism to process it; the MapReduce parallel programming model divides the task into several sma...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More