

Adaptive parallel processing method aiming at variable length characteristic extraction for big data
A feature extraction and parallel processing technology, applied in the field of big data processing, can solve the problems of high cost and limited number of CPU cores in distributed cluster systems
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0025] The content of the present invention will be further described in detail below in conjunction with the accompanying drawings.
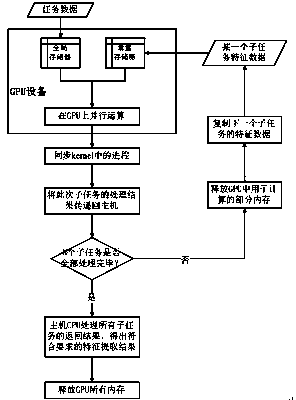
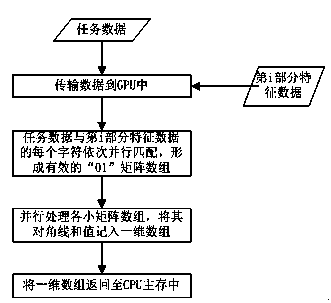
[0026] 1. The overall process of a large data-oriented adaptive parallel processing method for variable-length feature extraction involved in the present invention is: according to the length of its own hardware characteristics and feature data, adaptively adopt parallelizable matrix arrays The processing method divides the feature data to be extracted into N parts (see attached figure 1 ), process the data in batches, extract features of a certain length each time, construct a matrix array with good parallelism in parallel according to each part of the feature data and the task data from the big data to be processed, and perform multi-threading on the data Execute the processing concurrently and record the matching results; after the entire feature extraction is completed, process all the matching results according to the error tolerance rate ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More