

Text data stream clustering algorithm based on affinity propagation
A technology of data stream clustering and neighbor propagation, which is applied in electrical digital data processing, special data processing applications, and computing, etc. Problems such as local solution, a priori parameters—the average clustering dimension is difficult to determine, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

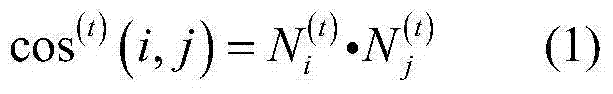
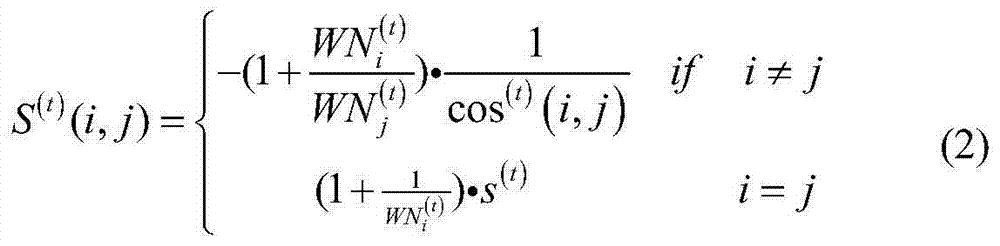
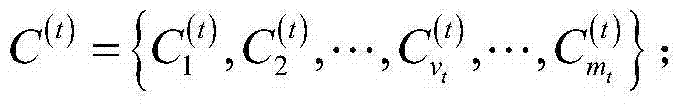
Examples
Embodiment Construction
[0044] In this embodiment, a text data flow clustering algorithm based on neighbor propagation——OWAP-s algorithm is carried out according to the following steps:
[0045] Step 1. Perform dimensionality reduction processing on the text data set to obtain the corresponding text vector set;
[0046] In order to cope with the high-dimensional and sparse characteristics of text data, the following dimensionality reduction method is adopted:
[0047] First, build a word index by building the entire document, and then convert the obtained to . Among them, index refers to the serial number of the word, and value refers to the value. Since the indexes of all documents are arranged from small to large, we search for the indexes in the vectors of the two documents in order when calculating the similarity. If the index values of the two documents are equal, then the two documents are indexed accordingly. The values are multiplied together and accumulated until the similarity betw...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More