

Method and system for building big data distributed log
A distributed, big data technology, applied in the field of big data processing, can solve problems such as inability to meet real-time performance, performance bottlenecks, log data loss, etc., to achieve flexibility and reliability, good scalability and stability, and system internal The effect of flexible networking
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0057] The principles and features of the present invention are described below in conjunction with the accompanying drawings, and the examples given are only used to explain the present invention, and are not intended to limit the scope of the present invention.
[0058] figure 1 It is a flow chart of the method for constructing a big data distributed log according to the present invention.
[0059] Such as figure 1 As shown, a method for constructing a distributed log of big data includes the following steps:
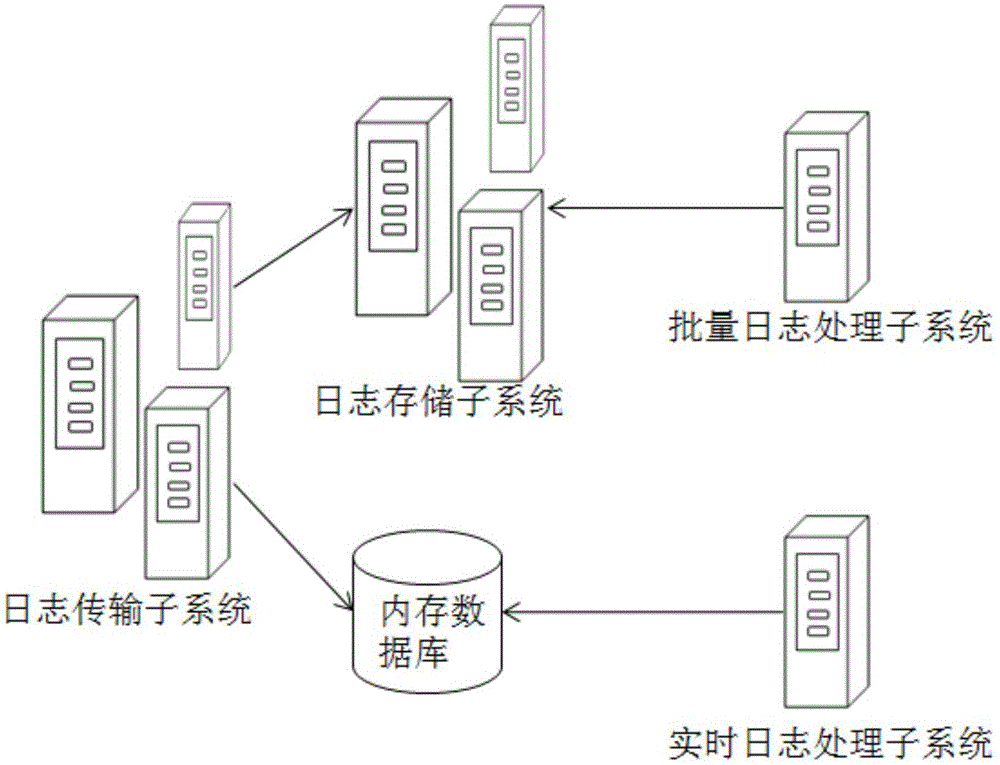
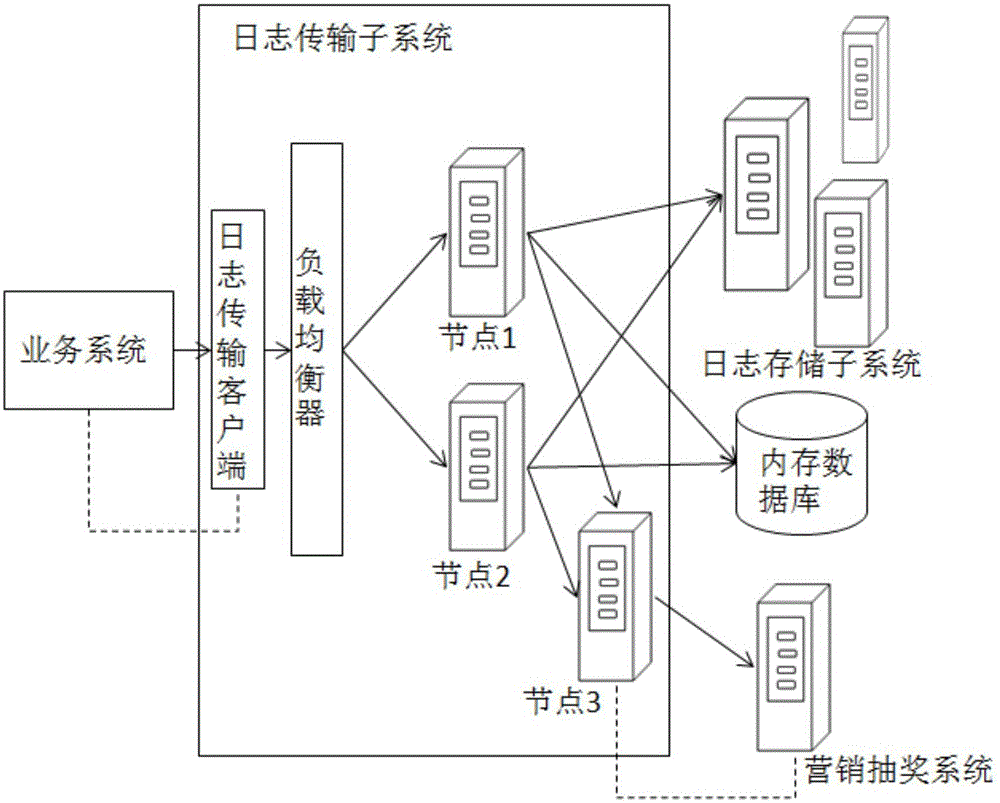
[0060] Step S1, the log transmission subsystem receives the log data from the business system, generates a UUID identifier for each received log data, and sends the log data with the UUID identifier through multiple nodes after load balancing to the log storage subsystem;
[0061] Step S2, the log storage subsystem receives the log data, stores the log data through horizontal expansion, and then sends the log data to the batch log processing subsystem;
[0062] St...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More