Method for reducing training set of machine learning
A machine learning and training set technology, applied in the computer field, can solve the problems of training set reduction that cannot be applied to multi-class classification, reduced reduction effect, uncertain class distribution, etc., to improve overall work efficiency, achieve reduction, time complexity and Effects with low space complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0034] As the best implementation mode of the present invention, the present invention discloses a method for reducing machine learning training sets, the steps of which are as follows:
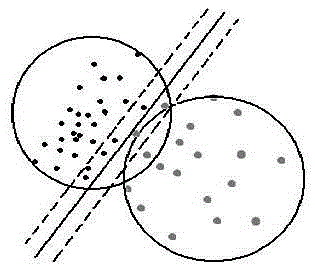
[0035] (1) Define the central formula of class A as , where S is the number of samples in class A, x i is the vector of samples in class A;
[0036] (2) Calculate the center point p of class A;
[0037] (3) Take a vector point x from class A, calculate the distance d from the vector point x to the center point p, if d is less than the screening factor λ, delete x from class A;
[0038] (4) Repeat step (3) to check all vector points in class A, if the number S of the remaining vector points in class A is less than the threshold α, proceed to step (6); if the remaining vector points in class A If the number S is greater than the threshold α, proceed to step (5);
[0039] (5) Repeat steps (2), (3) and (4), and proceed to step (6) after completion;
[0040] (6) Output the remaining vector p...
Embodiment 2
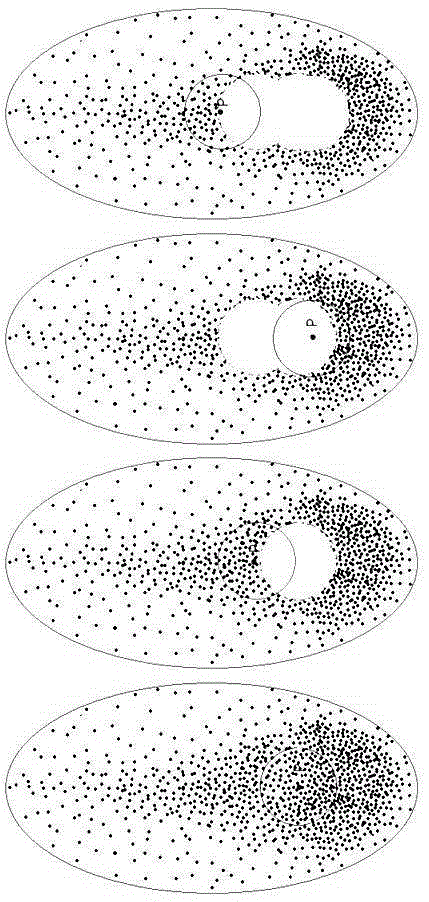
[0050] The overall design idea of the experiment is to use the training set reduction method to reduce the general training set Newgroup, and then use the classic machine learning model SVM (support vector machine) model and CBC (centroid-based classification) model for testing.
[0051] The introduction of experimental materials and indicators, the training set Newgroup shares 20 categories, each category has 1000 samples, the entire training set has a total of 20000 samples, and the experimental indicators include micro-average F1 (micro_F1, the higher the value, the better), macro-average F1 ( macro_F1, the higher the value, the better), information entropy (Entropy, the lower the value, the better)
[0052] The following are the specific experimental steps.
[0053] 1. experiment process
[0054] (1) When the general training set is not reduced, 10% of the samples are randomly selected as the test set and the remaining 90% of the samples are used as the training set. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More