A Distributed Data Deduplication Method and Device Based on Self-Matching Feature
A technology of de-duplication and self-matching, applied in the direction of digital data processing, input/output process of data processing, instruments, etc., can solve the problems of data redundancy in distributed storage systems, save network bandwidth and save storage space Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
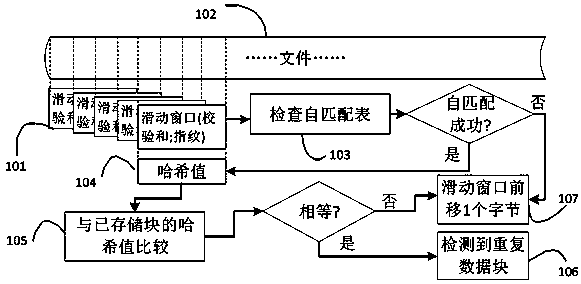
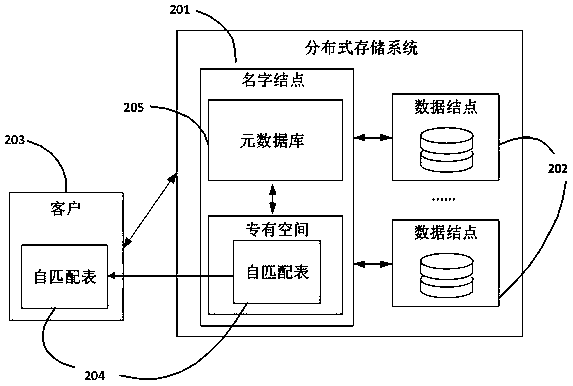
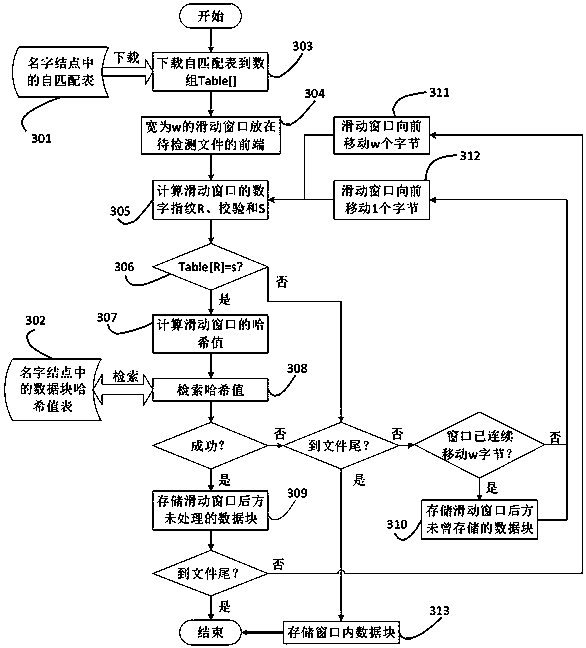
[0038] The invention provides a distributed duplicate data deletion method based on a self-matching feature, which is used to solve the data redundancy problem in a distributed storage system. In view of the low detection rate of duplicate data in the fixed block method and the content-based block method in the prior art, and the problem that the sliding block method cannot be applied in a distributed storage environment due to excessive network traffic, the embodiment of the present invention simultaneously Calculate the digital fingerprint and checksum of the data in the sliding window, and preliminarily screen out possible duplicate data blocks by querying the self-matching table; Data blocks with the same hash value are discarded, otherwise they need to be uploaded and saved; before uploading files, customers download the self-matching table from the name node to obtain the initial feature information of self-matching, so that the entire system can achieve the effect of dis...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com