

A Text Classification Method and System Based on Rough Set and KNN
A text classification and rough set technology, applied in the direction of text database clustering/classification, unstructured text data retrieval, etc., can solve the problems of high computational cost, without considering the problem of massive data processing speed, text recall rate, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
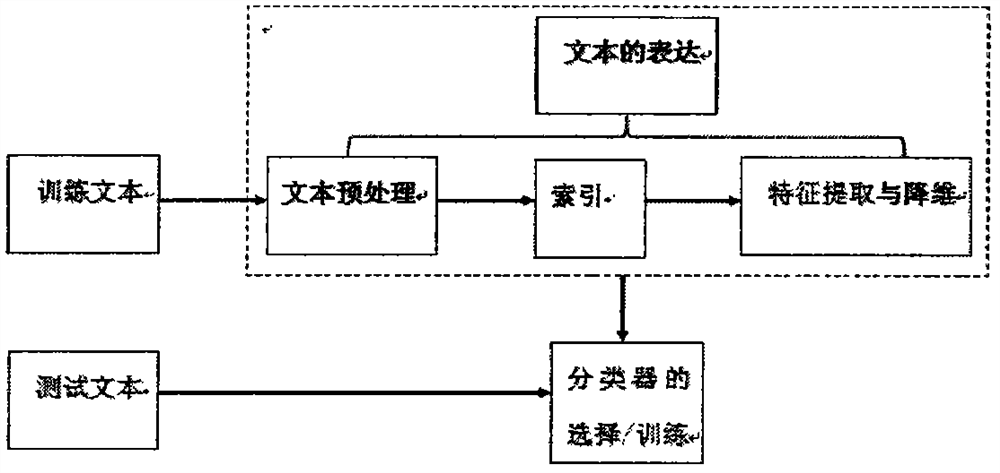
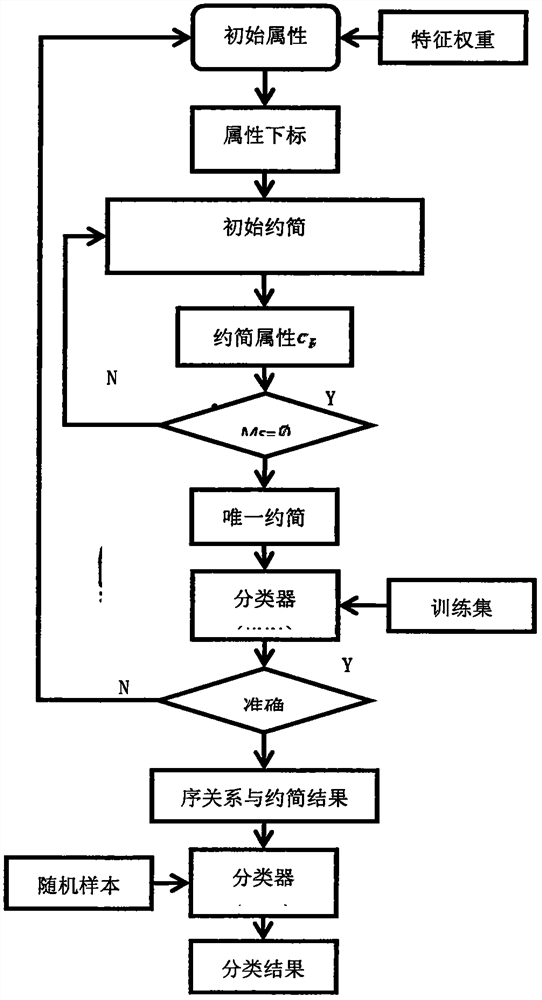
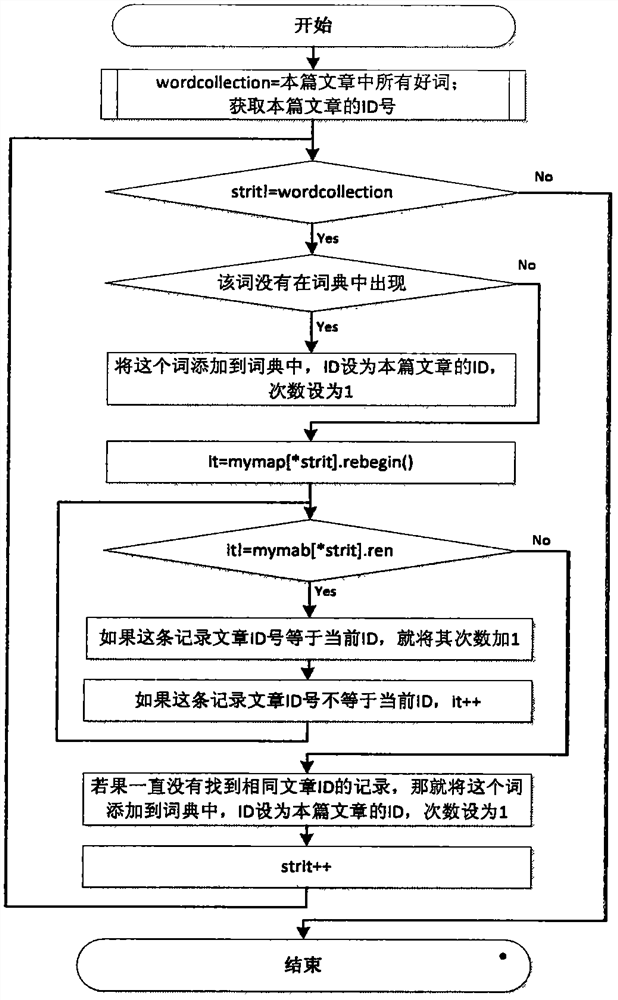
[0016] In view of the high dimensionality and calculation times of the text data to be classified in the KNN (K Nearest Neighbor) text classifier, which leads to problems such as high time and space costs, the present invention adopts the rough set attribute reduction algorithm to be classified The data is preprocessed. Then, the NP-hard problem in rough set attribute reduction is further solved by processing methods and algorithms based on attribute order. In terms of reducing the computational complexity of the algorithm, we start from the two aspects of the algorithm itself and computing skills: propose a decreasing calculation method in the calculation of the positive region of the key link of the rough set discrimination matrix to reduce the calculation workload of the equivalence class; use to stop the word search The table method, the introduction of location information in the attribute sequence and the retrieval method of inverted index further reduce the running time ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More