

Search algorithm based on DNA k-mer index problem four-node list trie tree
A search algorithm and DNA sequence technology, applied in computing, digital data processing, special data processing applications, etc., can solve problems such as slow computing speed and large storage capacity, and achieve the effect of saving node space
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
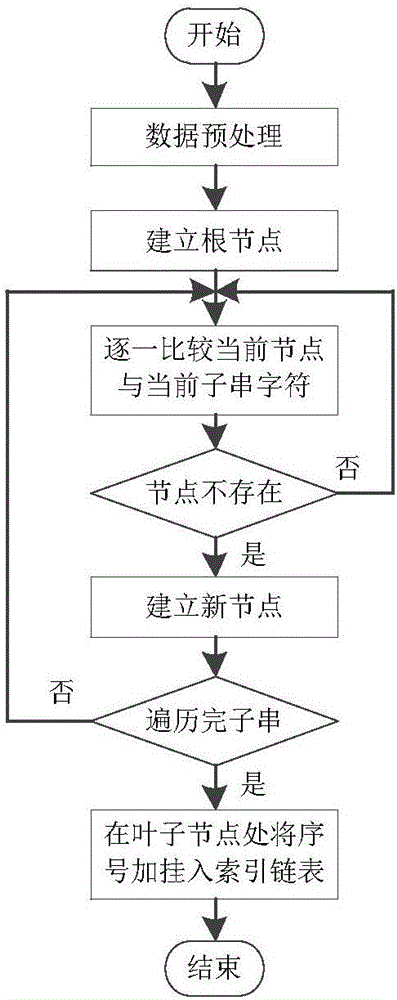
[0025] The present invention is described in more detail below in conjunction with accompanying drawing example:
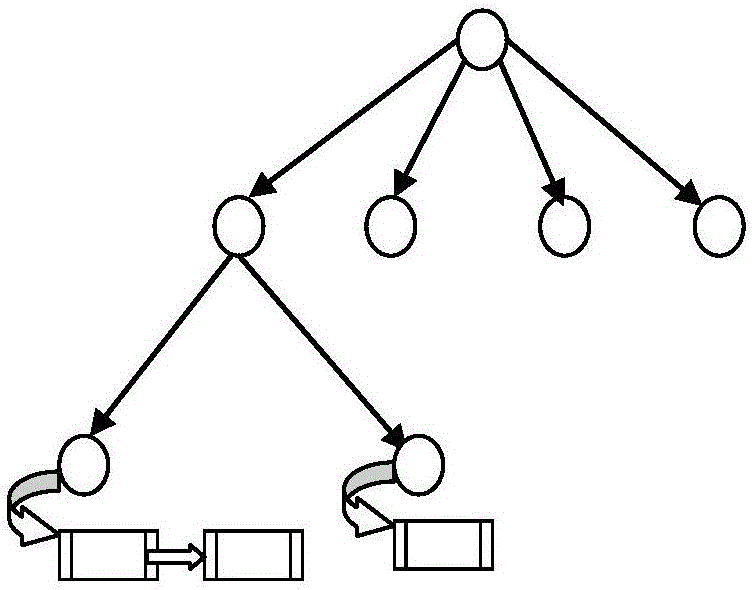
[0026] The method realizes the optimization of the original data of the traditional dictionary tree, and saves the storage space. At the same time, the leaf node is used as the end mark of k-mer to facilitate the return of query results and reduce the complexity of word search.
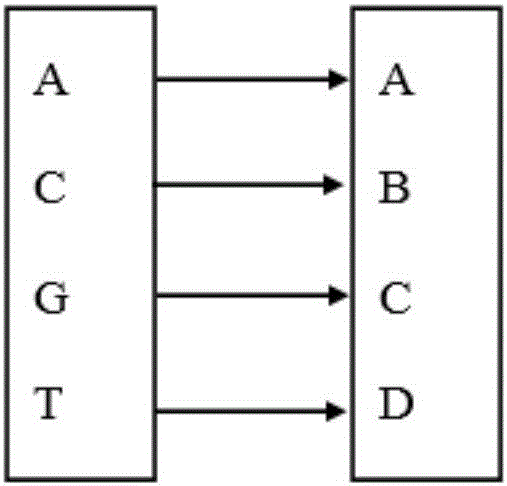
[0027] A four-word linked list dictionary tree retrieval algorithm based on the DNA k-mer index problem, including two steps of establishing a four-word retrieval dictionary tree model and word search. Its characteristics are: making further improvements on the basis of the dictionary tree model, preprocessing the original data and using the leaf nodes of the dictionary tree as word end marks. This processing not only has no effect on the query speed but also saves storage space and reduces space complexity.
[0028] A four-word linked list dictionary tree retrieval algorithm based on t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More