Method of voice recognition self-adaptive system based on heterogeneous dual-MIC in mobile environment
A technology of speech recognition and mobile environment, applied in speech recognition, speech analysis, instruments and other directions, to achieve the effect of simple implementation, reducing the pressure of complex scenes, and improving the accuracy rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0028] The present invention will be further elaborated below in conjunction with accompanying drawing:
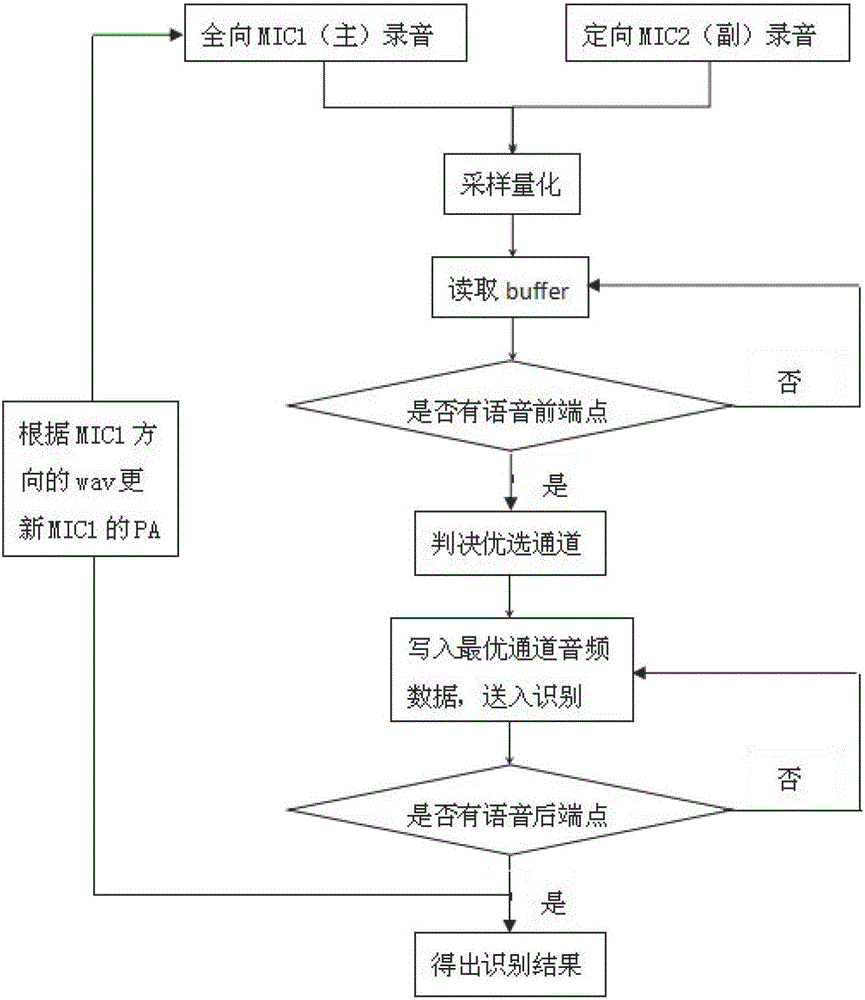
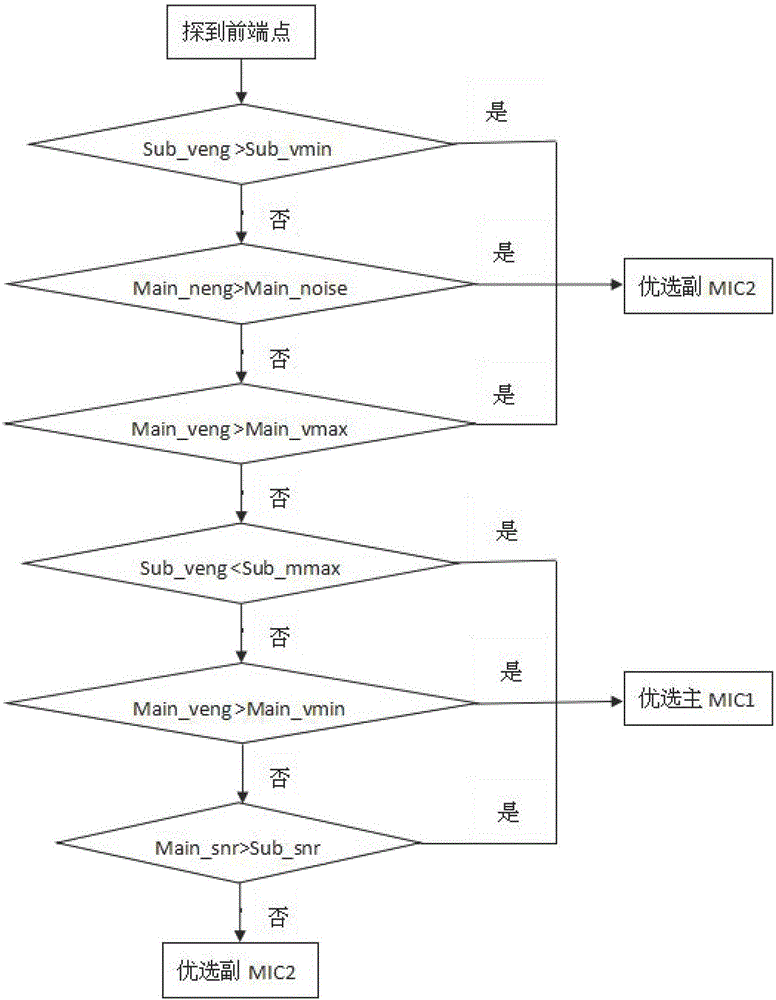
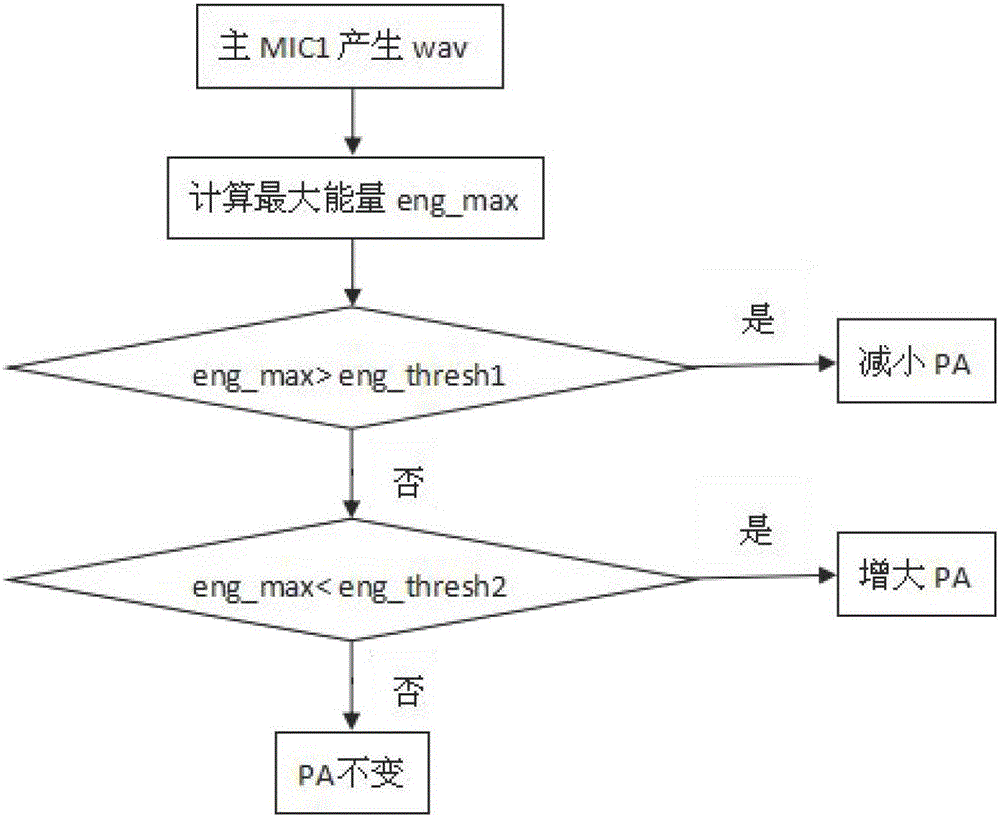
[0029] as attached figure 1 and attached Figure 4 As shown, the mobile terminal of the present invention includes: a PA binding module, a preference module and an update module. Initially set the PA value of the omni-directional main MIC1 and directional sub-MIC2, the main MIC1 realizes dynamic binding of PA, and the sub-MIC2 binds a fixed PA value; after binding the PA module, enter the preferred module, first need to set the preferred mode of the main and sub-MIC Identify the rules, and when the terminal enters the recording mode, start the recording channels of the main and auxiliary MICs at the same time, and keep recording; detect in real time whether the main and auxiliary MICs have voice endpoint characteristics, and if so, select the optimal audio according to the optimization rules Voice recognition is performed on the data of the channel until the end point of...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



