

R-TBF-based RFID redundant data cleaning strategy
A redundant data and strategy technology, applied in the field of data cleaning, can solve problems such as incomplete considerations, reduced data quality, poor cleaning effect, etc., to achieve the effect of improving cleaning effect and improving data quality
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

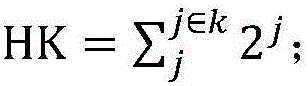
Examples
Embodiment 1
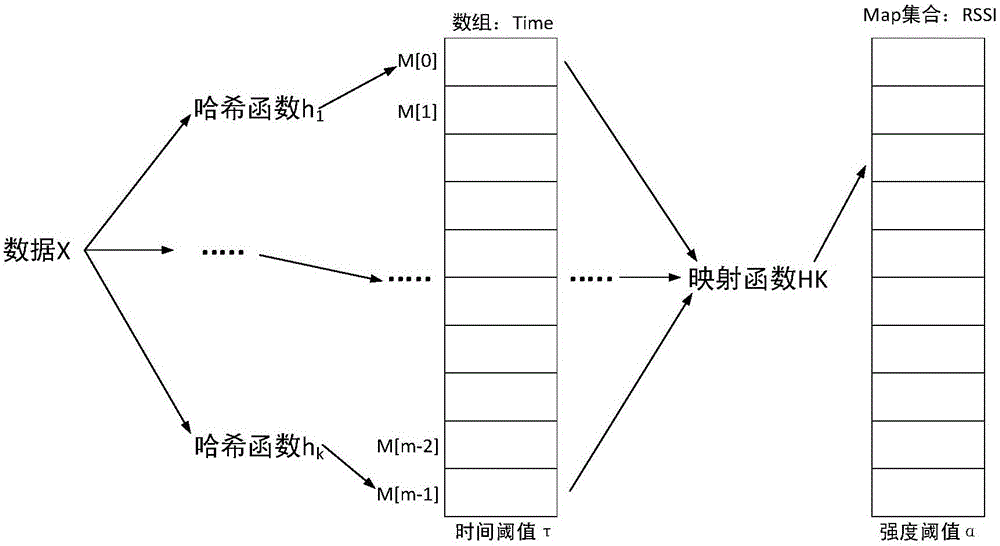
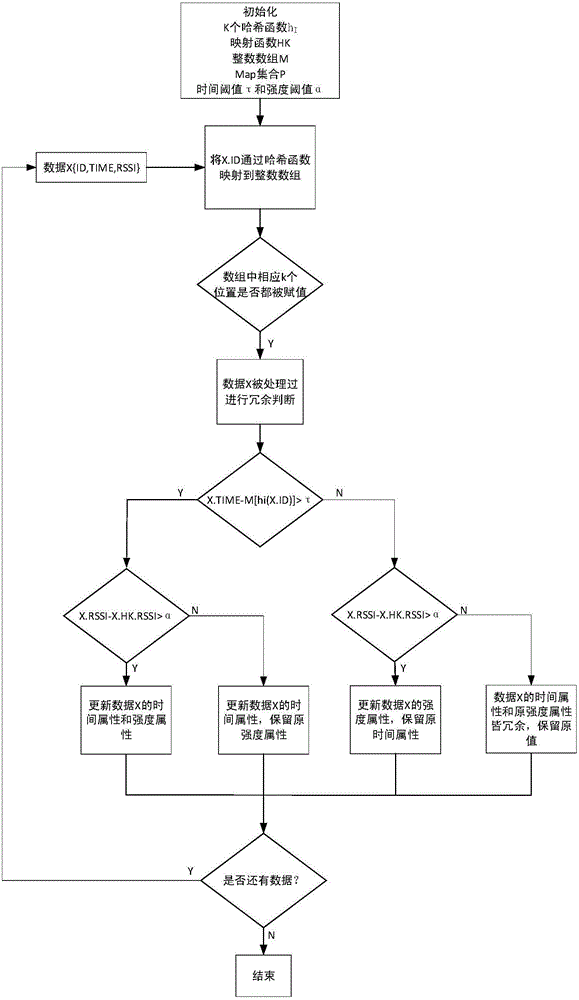
[0045]As shown in the figure, the R-TBF-based RFID redundant data cleaning strategy provided by this embodiment solves the problem that the traditional TBF-based RFID data cleaning strategy has poor cleaning effect due to insufficient constraints and deletes useful data by mistake. Further improve the data quality, restore the authenticity of the data, and provide a strong guarantee for the effective use of subsequent data; on the basis of the TBF-based RFID data cleaning strategy, the consideration factor is adjusted from a single time to two factors of time and intensity, because in In the actual application scenario, due to the large coverage of the reader, the mobile RFID inspection vehicle can already read the data information of the corresponding tag before it reaches the position facing the tag. The typical characteristics of this type of information are that the time is short and the intensity is high. Small, if only relying on time to judge whether the data is redundan...
Embodiment 2
[0074] Combine below figure 2 The shown cleaning process is described in detail, and the cleaning process provided in this embodiment mainly includes the following steps:
[0075] Step 1: Initialize the filter, the initialization content includes:
[0076] 11) an integer array M used to save the data time attribute, with a size of m;
[0077] The size of m is calculated according to the following formula:
[0078]
[0079] Among them, n is the size of the input data, P represents the probability that a unit in the integer array is still empty after k n times of mapping, and k is the number of hash functions;
[0080] 12) k hash functions h for mapping data label information to integer arrays 1 … h k ;
[0081] The size of k should satisfy the following inequality:
[0082] k·n
[0083] Among them, n is the size of the input data volume, and m is the size of the integer array;
[0084] The formula for calculating k is:
[0085]
[0086] Among them, n is the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More