

Data information consistency processing method, system and device based on big data
A data information and consistency technology, applied in the field of big data, can solve problems such as long execution time and complex process processing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
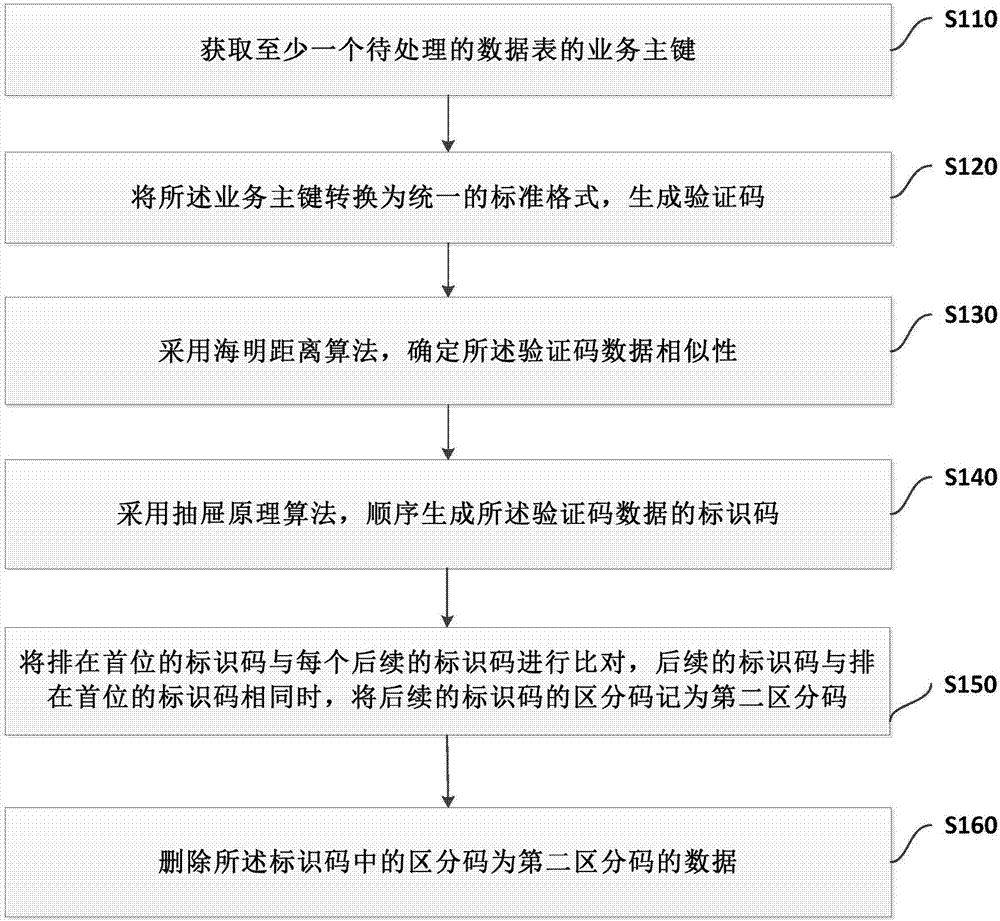
[0056] refer to figure 1 , figure 1 A flow chart of an embodiment of a big data-based data information consistency processing method provided by the present invention is shown. Including: step S110 to step S160.
[0057] In step S110, the business primary key of at least one data table to be processed is obtained.
[0058] In step S120, the business primary key is converted into a unified standard format to generate a verification code.
[0059] In step S130, the Hamming distance algorithm is used to determine the similarity of the verification code data.
[0060] In step S140, the identification codes of the verification code data are sequentially generated by using the drawer principle algorithm.
[0061] In step S150, the first identification code is compared with each subsequent identification code, when the subsequent identification code is the same as the first identification code, the identification code of the subsequent identification code is recorded as the secon...
Embodiment 2
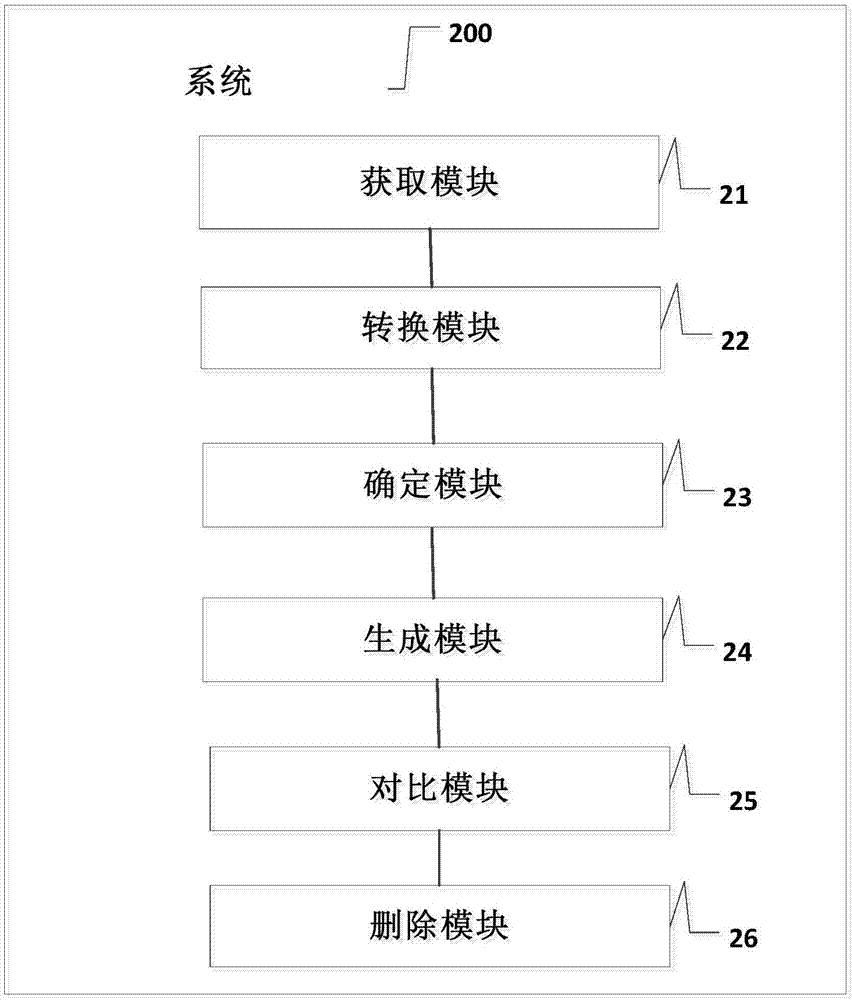
[0089] refer to figure 2 , figure 2 A structural block diagram of an embodiment of a data information consistency processing system 200 based on big data provided by the present invention is shown. include:
[0090] An acquisition module 21, configured to acquire the business primary key of at least one data table to be processed;
[0091] A conversion module 22, configured to convert the business primary key into a unified standard format to generate a verification code;
[0092] A determining module 23, configured to determine the similarity of the verification code data by using the Hamming distance algorithm;
[0093] The generating module 24 is used to sequentially generate the identification codes of the verification code data by adopting the drawer principle algorithm;
[0094] Contrast module 25, is used for comparing the first identification code with each subsequent identification code, when the subsequent identification code is the same as the first identifica...
Embodiment 3
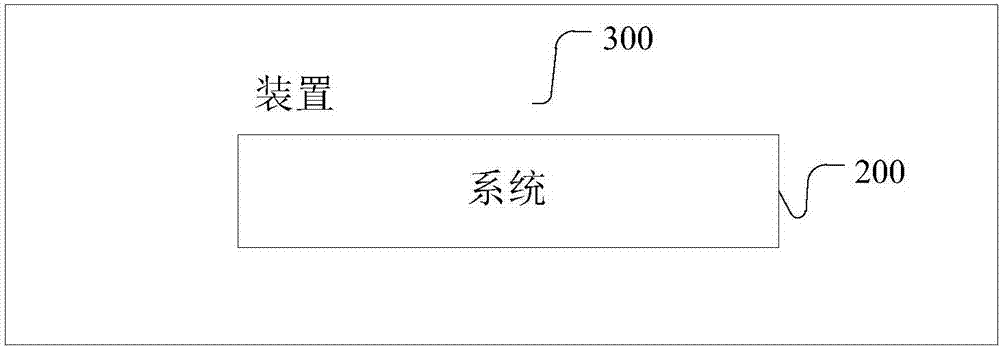
[0113] refer to image 3 , image 3 A structural block diagram of an example of a data information consistency processing device 300 based on big data provided by the present invention is shown. It includes the system 200 described in any one of the second embodiment.
[0114] Embodiment 3 of the present invention provides a data information consistency processing device based on big data. The invention obtains at least one business master key of a data table to be processed; converts the business master key into a unified standard format to generate a verification code; Use the Hamming distance algorithm to determine the similarity of the verification code data; use the drawer principle algorithm to sequentially generate the identification codes of the verification code data; compare the first identification code with each subsequent identification code, and follow-up When the identification code is the same as the first identification code, record the identification code o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More