

Action recognition method based on attention mechanism of convolution recurrent neural network
A technology of recursive neural network and convolutional neural network, which is applied in the field of computer vision action recognition, can solve problems such as the inability to effectively extract salient areas, and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
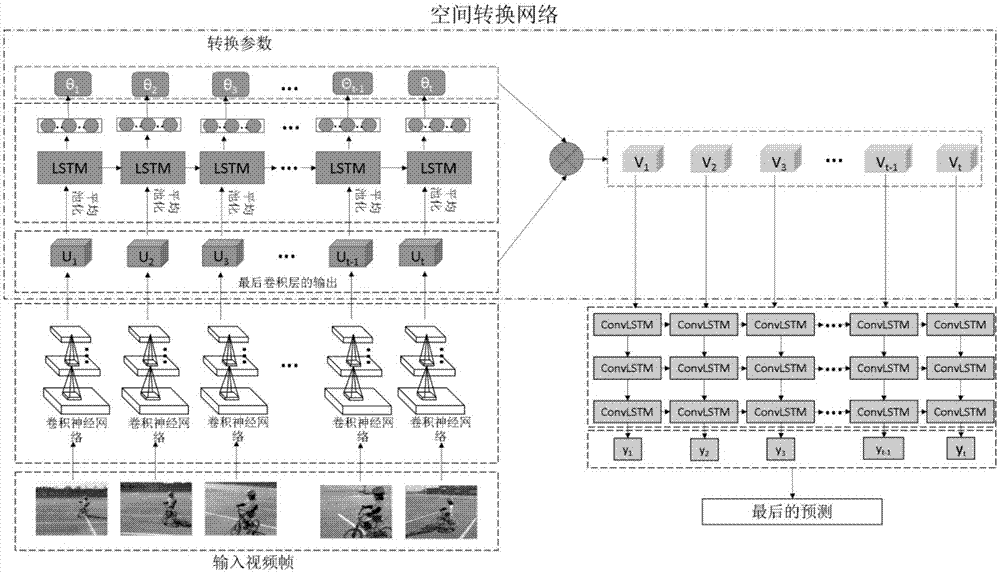
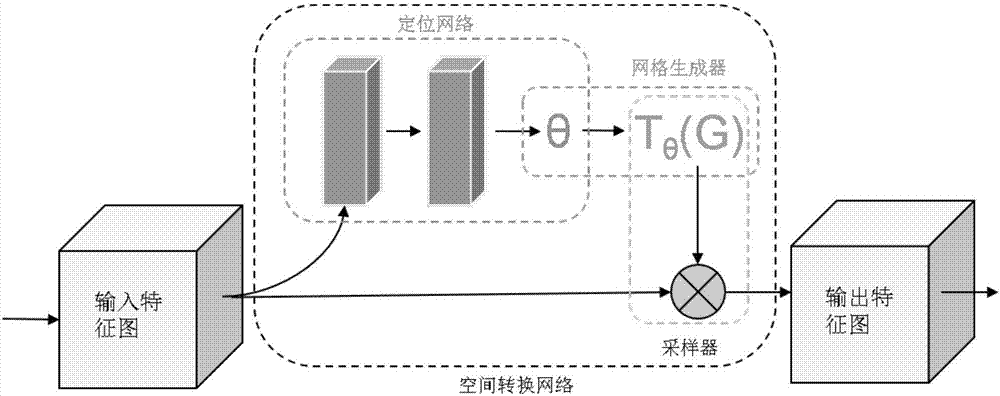
[0030] An embodiment of the present invention provides an action recognition method based on an attention mechanism. The specific embodiments discussed are merely illustrative of implementations of the invention, and do not limit the scope of the invention. Embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings, specifically including the following steps:
[0031] 1 Data preprocessing. The size of the RGB image of the original video frame is not uniform, which is not suitable for subsequent processing. The present invention cuts the original image so that its size can be unified. At the same time, in order to speed up the subsequent processing, the present invention performs normalization processing on the image.
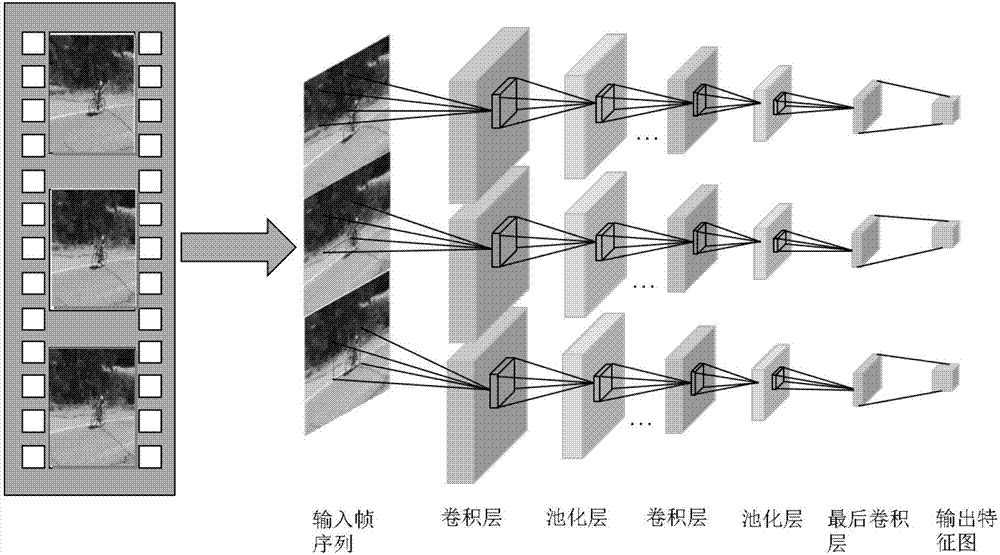
[0032] 2 feature extraction. In view of the success of the GoogleNet neural network in image feature representation, the present invention regards a video as an image collection composed of multiple fr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More