

Grid clustering algorithm based on density peak value
A technology of grid clustering and density peaks, applied in computing, computer parts, instruments, etc., can solve problems such as inability to process large-scale data sets, failure of selecting center points, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0066] The technical solutions in the embodiments of the present invention will be described clearly and in detail below with reference to the drawings in the embodiments of the present invention. The described embodiments are only some of the embodiments of the invention.
[0067] The technical scheme that the present invention solves the problems of the technologies described above is:
[0068] DPC clustering algorithm
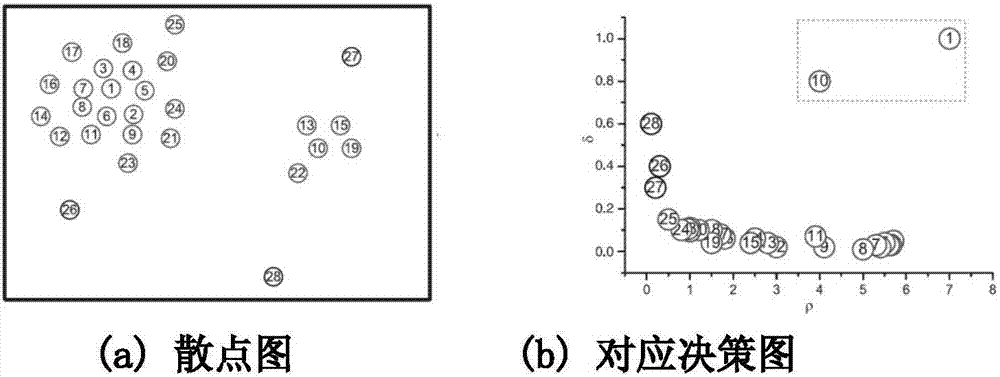
[0069]The idea of the density peak clustering algorithm is simple and novel. First, two variables of each point are calculated: the local density and the distance to the high-density point. The selection of the cluster center is based on two basic assumptions: (1) the density of the cluster center is higher than the density of its adjacent sample points; (2) the distance between the cluster center and the cluster center with a higher density is relatively larger. Obviously, the cluster center point is a point with a large local density and a large dista...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More