Improved algorithm for missing value interpolation
A missing value and interpolation technology, applied in the field of data analysis and preprocessing, can solve problems such as the difficulty of grasping the rationality and correctness of missing value interpolation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
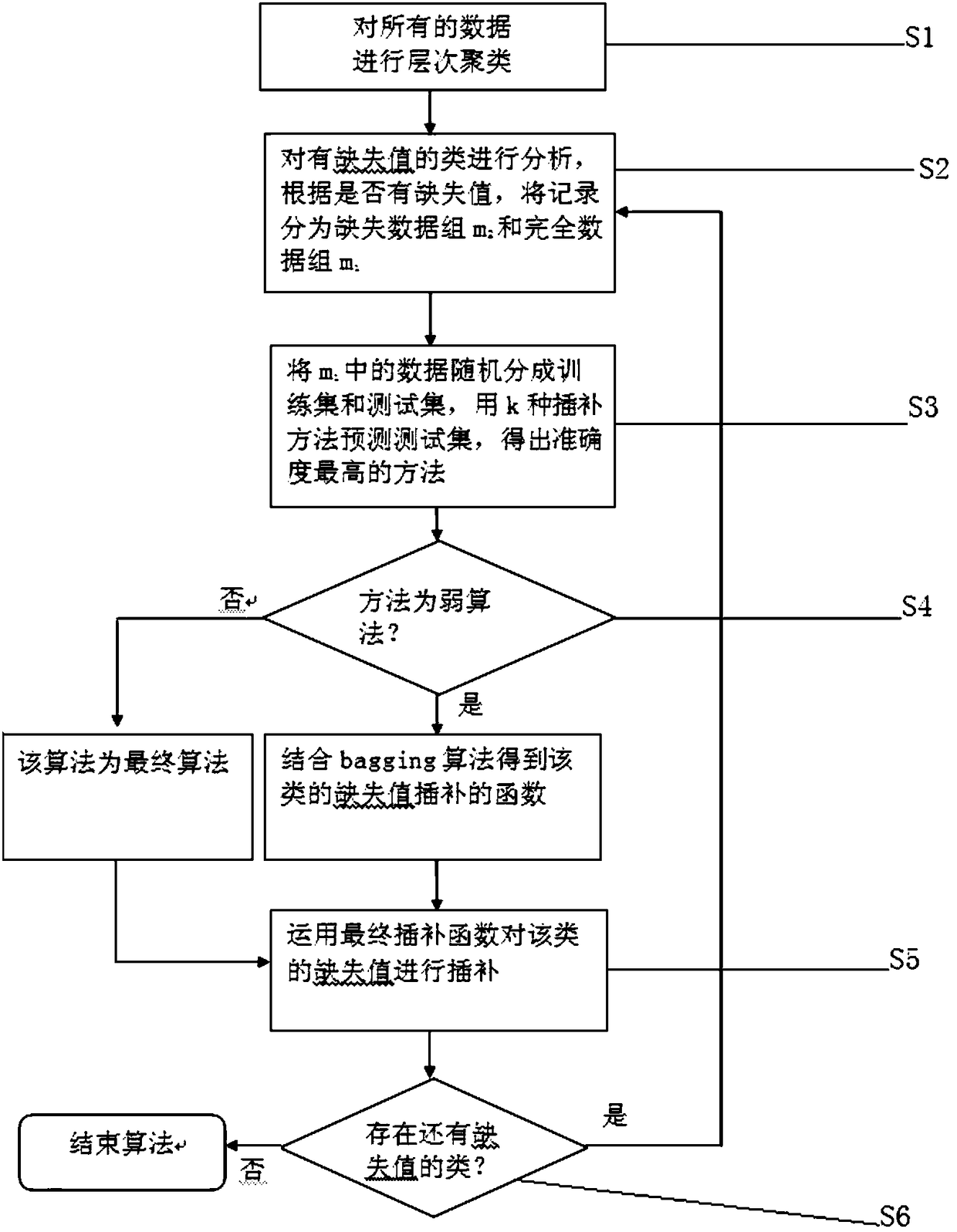
[0022] Such as figure 1 As shown, the present invention is an improved interpolation scheme for data missing values, combined with the existing interpolation method, using the principle of bagging algorithm, to select and retrain various interpolation algorithms according to the characteristics of the data, Improve the original algorithm, and then achieve the purpose of restoring a complete and approximate real data set. The group and algorithm include the following steps for the imputation scheme for missing values:
[0023] Step S1, performing hierarchical clustering on all data.
[0024] To a certain extent, it is guaranteed that the complete data and missing data of the same type are gathered together for analysis, which is more reasonable and convenient to construct a model suitable for missing imputation.
[0025] Step S2, for the classes with missing values, divide the records into complete data groups m according to whether they are records with missing values 1 and...
Embodiment 2
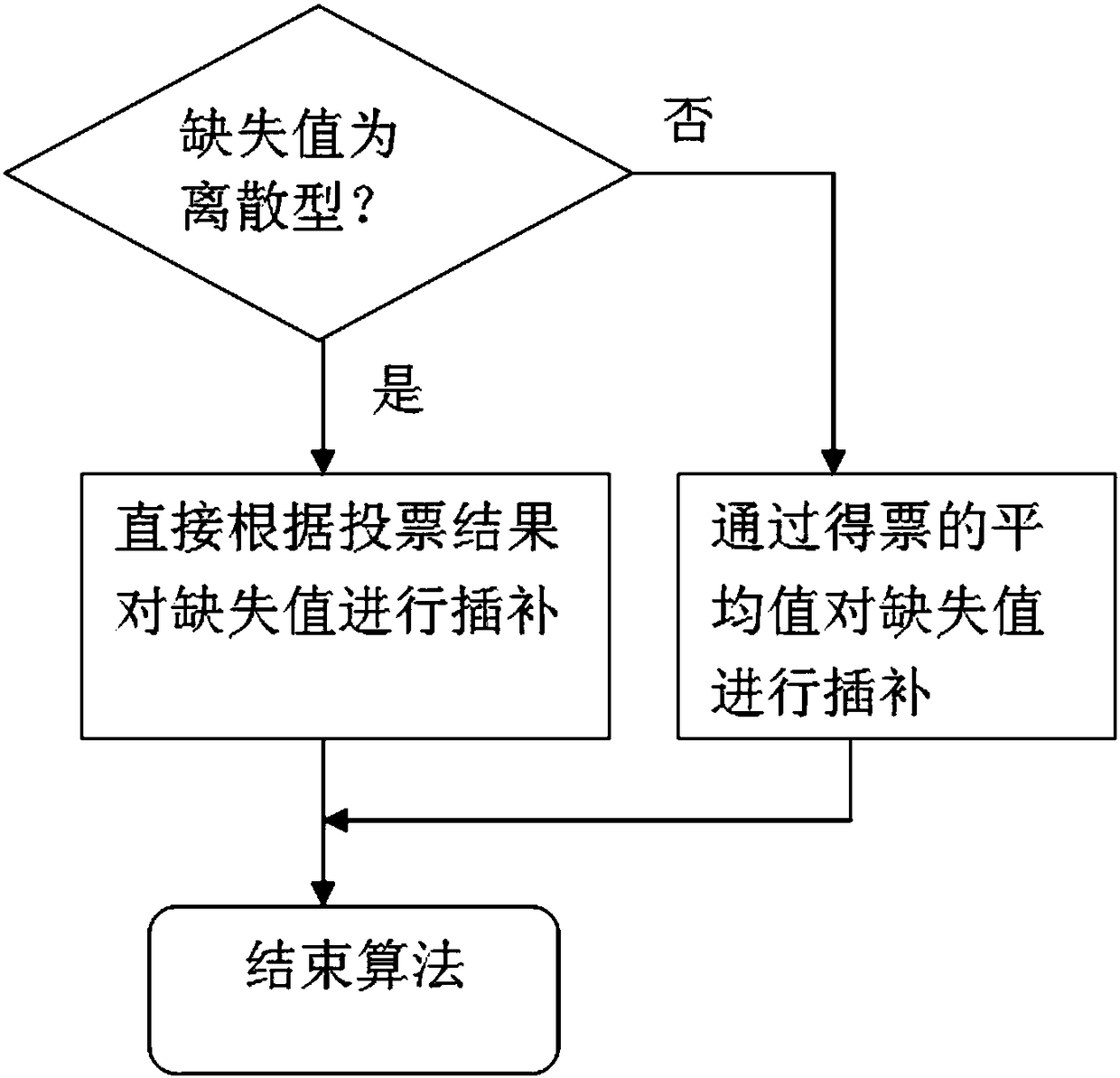
[0034] Such as figure 2 Shown are the different processing methods of the bagging algorithm for different types of missing values.
[0035] The basic idea of bagging algorithm:
[0036] Given a weak learning algorithm and a training set, the accuracy of a single weak learning algorithm is not high, and the learning algorithm is used multiple times to obtain a sequence of prediction functions and vote, and the accuracy of the final result will be improved.
[0037] Step S1: Independently and randomly extract a certain amount of data from the data set to form a self-service data set, and repeat this process independently for many times until many independent self-service data sets are generated.
[0038] Step S2: Each bootstrap dataset is independently used to train a "component classifier".
[0039] Step S3: The final classification decision is decided by voting on the respective decision results of these "component classifiers".
[0040] Improve the bagging algorithm for...
Embodiment 3
[0042] On the basis of the above-mentioned implementation, taking a certain amount of normal distribution data set containing multiple variables randomly generated as an example, use data analysis software to simulate the complete data set and random missing data with different missing rates, and use the above method to interpolate repair.
[0043] First, the data is hierarchically clustered, the classes with missing values are analyzed, and the complete data in the classes are randomly divided into training sets and test sets; then, mean replacement method, hot card filling method, regression replacement method, multiple Substitution and group deletion methods deal with missing data.
[0044] The imputation effect was examined from two aspects of accuracy and distribution, the K-S normality test was used to evaluate whether the data sets processed by different methods conformed to the normal distribution, and the Wilcoxon signed rank sum test was used to compare the process...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More