

Operation fault location method for concurrent job
A locating method and technology for operating faults, applied in the field of high-performance computing, can solve the problems of no fault locating method and no guarantee of fault locating timeliness.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
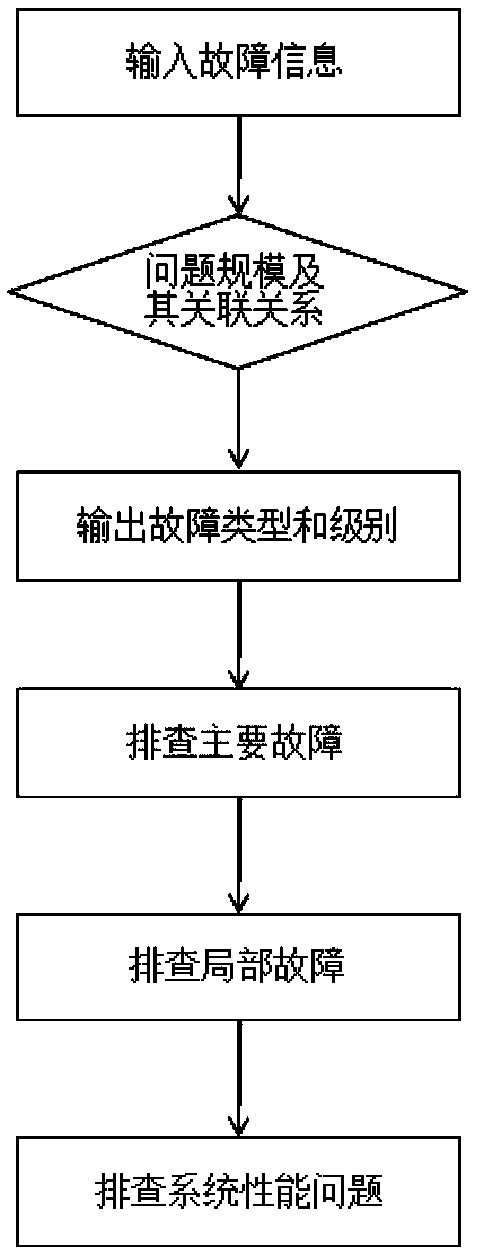
[0081] A method for locating a parallel job running fault, comprising the following steps:
[0082] 1) Get system information
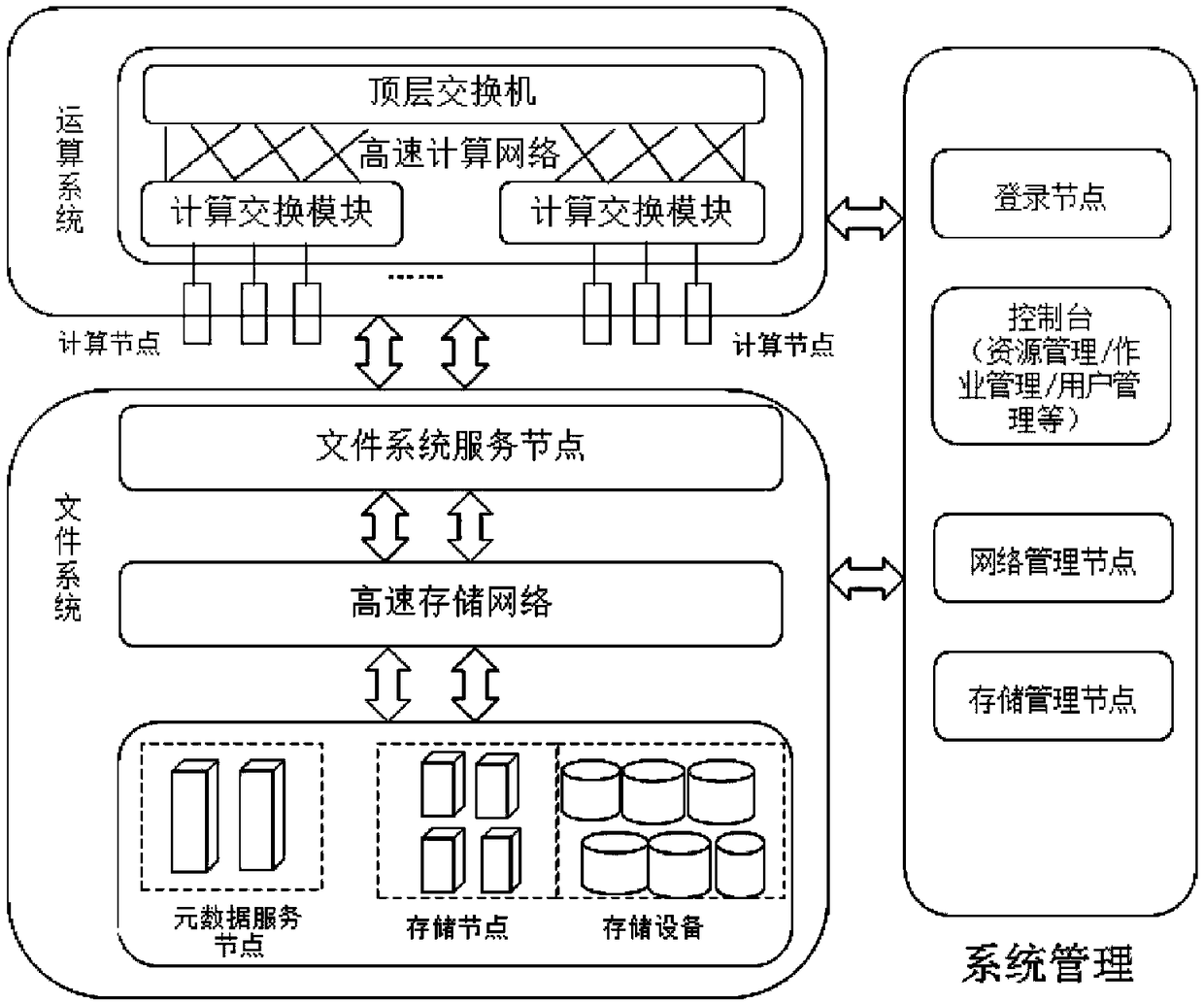
[0083] The system information includes job status, computing node status, network system status, file system status, and job and resource management system status; computing node status, network system status, file system status, and job and resource management system status are dependent on job operation The status of system resources; the system information is obtained through existing system monitoring and management tools;
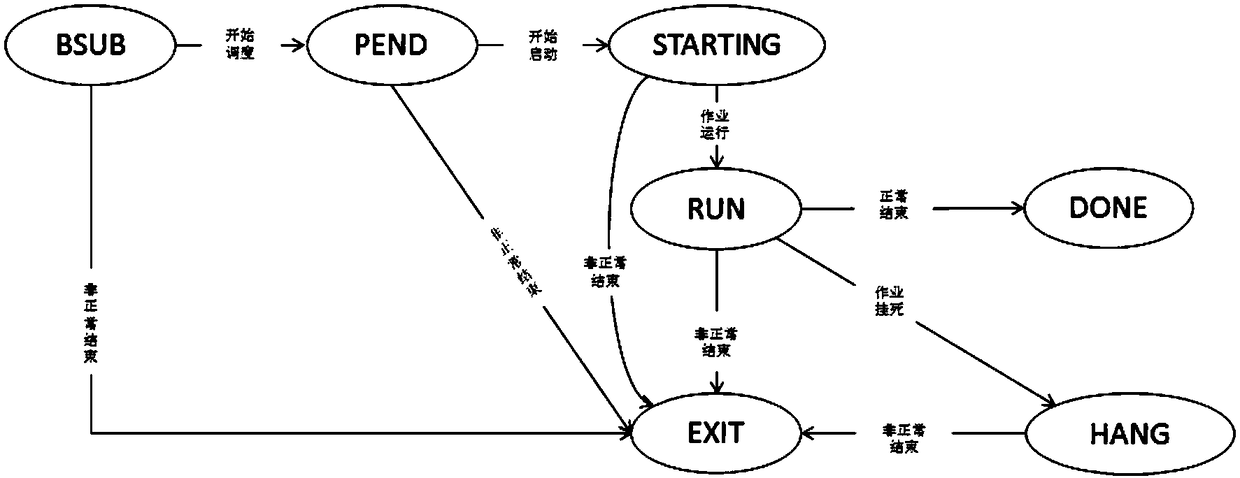
[0084] From the user submitting the job to the system, to the completion and exit of the job, each stage has a corresponding job status. The job status transition relationship is as follows figure 1 shown.
[0085] The job status is the running status of the job program submitted by the user in the high-performance computing system; the meaning of the job status is as follows:
[0086] 1.1) PEND: The job is being scheduled...
Embodiment 2
[0142] As in the parallel job running fault location method described in Embodiment 1, further, the job status 1.1)-1.5) is obtained through the job status query command; the job status 1.6) is obtained by monitoring the output of the job running log and job data; if the job If the status shows RUN, but the output of the job data has stopped, it is judged that the job is hung;
[0143] If there is no result output after executing the job status query command, it is determined that the job management master control in the job and resource management system is faulty, and the event severity level is 1; further check the job management master control status;
[0144] On the system console or the user login node, use the computing node status query command cnload to obtain the computing node status, network system status, and file system status corresponding to the job;
[0145] In addition to the fault information obtained through the system monitoring management tool, the fault ...
Embodiment 3
[0147] As in the parallel job running fault location method described in Embodiment 1, further, for the error messages that appear during the job running and the error messages in the logs, the causes of the faults and handling suggestions are given through the associated knowledge base. For example, the reason for the error "Exceed user avail resource quota" returned by the job is that the disk exceeds the limit; the reason for "Connect tormsctld failed" is the failure of the overall resource control.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More