

Parallel k-means algorithm used for high-dimensional text data
A text data and algorithm technology, applied in the direction of electrical digital data processing, special data processing applications, computing, etc., can solve the problems of large randomness of clustering results and inappropriate use of distance to measure similarity, so as to improve the operation speed and reliability The effect of improving portability and accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

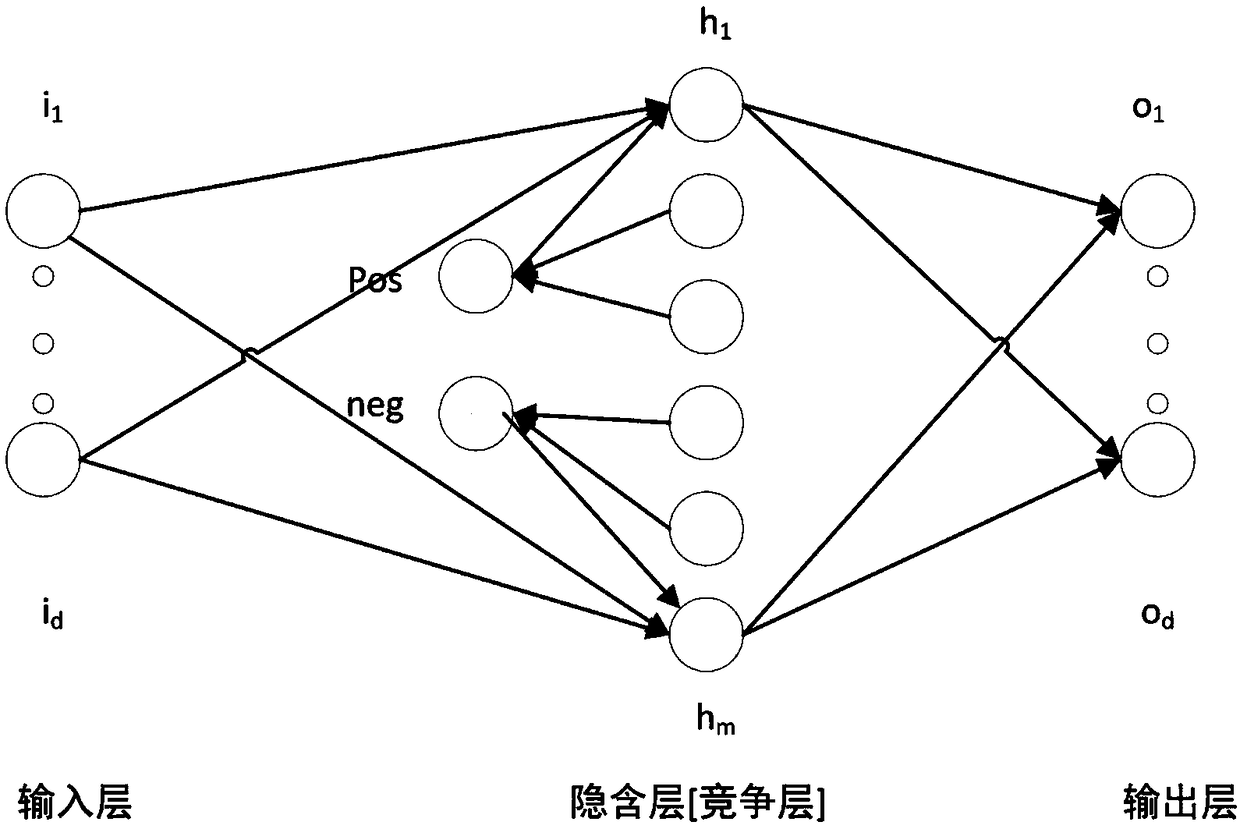
Examples
Embodiment Construction
[0031] Embodiments of the present invention will be described in detail below.
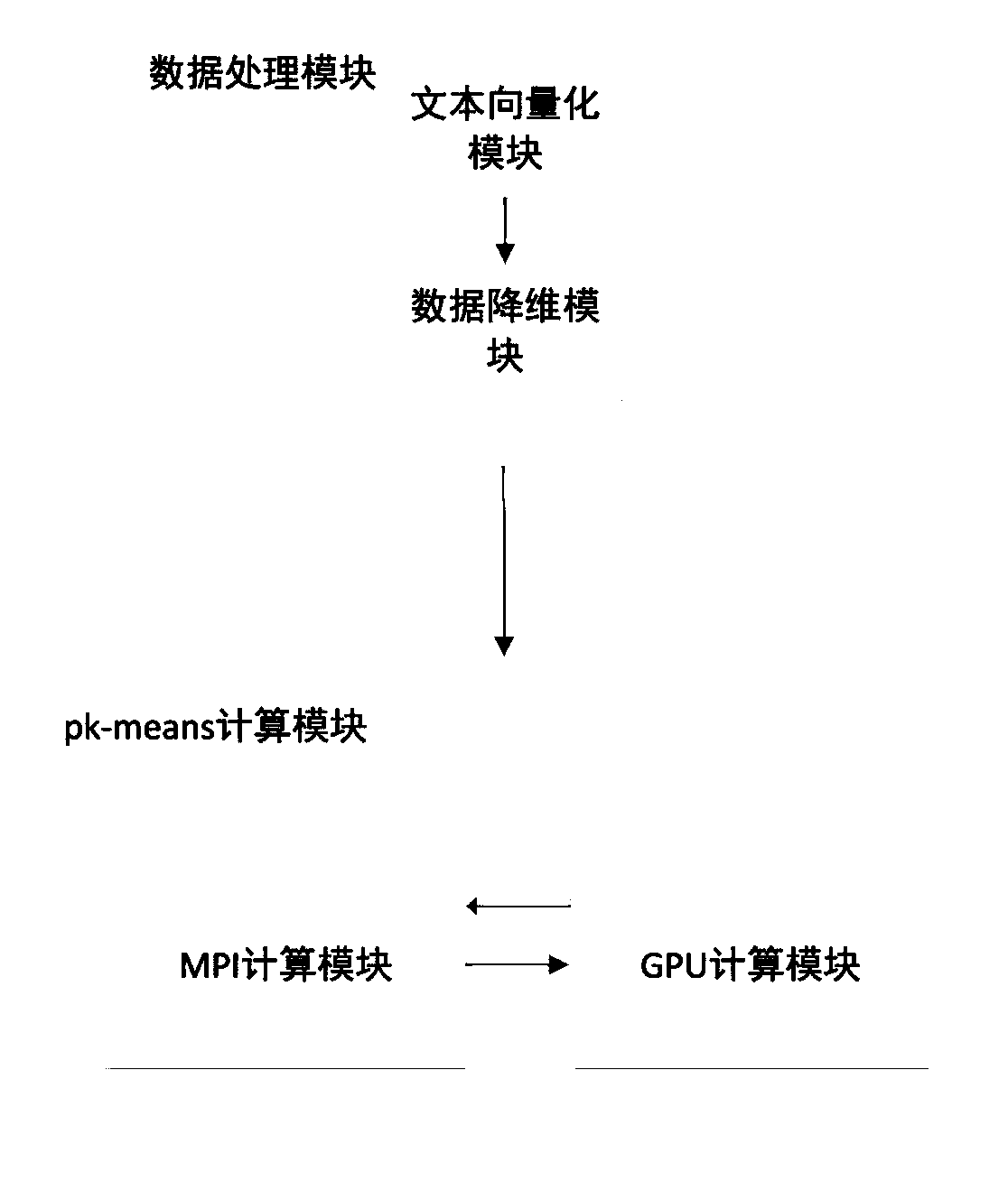
[0032] A parallel k-means algorithm for high-dimensional text data, including the following steps:
[0033] The first step is to train high-dimensional text data to obtain low-dimensional data
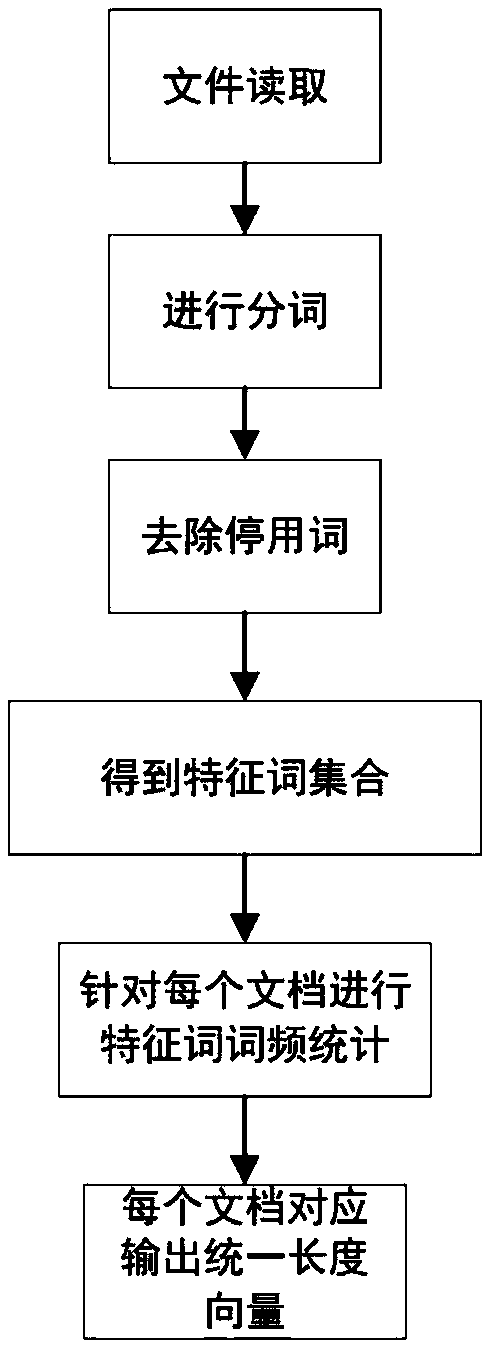
[0034] 1.1) Select an appropriate text representation model to vectorize text data. The present invention adopts the Bag-of-words text representation model, and the matrix size that obtains by this model is N*d, and what N represents among them is text quantity, and what d represents is the feature word number of whole corpus, also can be said to be each The current dimension of the document. Such as figure 2 The process of vectorizing text using the bag-of-words model is shown: first, read the content of the file line by line; then, use the nltk library in Python to segment the read content; after that, read the content in the stop word list, Remove the stop words in the file; finally, the feature wo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More