

Speech-driven lip-synchronous face video synthesis algorithm based on concatenated convolution LSTM
A technology of lip synchronization and video synthesis, applied in the field of computer vision, it can solve problems such as under-constrained, and achieve the effect of expanding the receptive field and increasing the depth
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0036] The technical solutions of the present invention will be clearly and completely described below in conjunction with the accompanying drawings in the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
[0037] In order to make the object, technical solution and advantages of the present invention clearer, the embodiments of the present invention will be described in detail below with reference to the accompanying drawings.
[0038] According to the embodiment that the complete method of the present invention is specifically implemented is as follows:
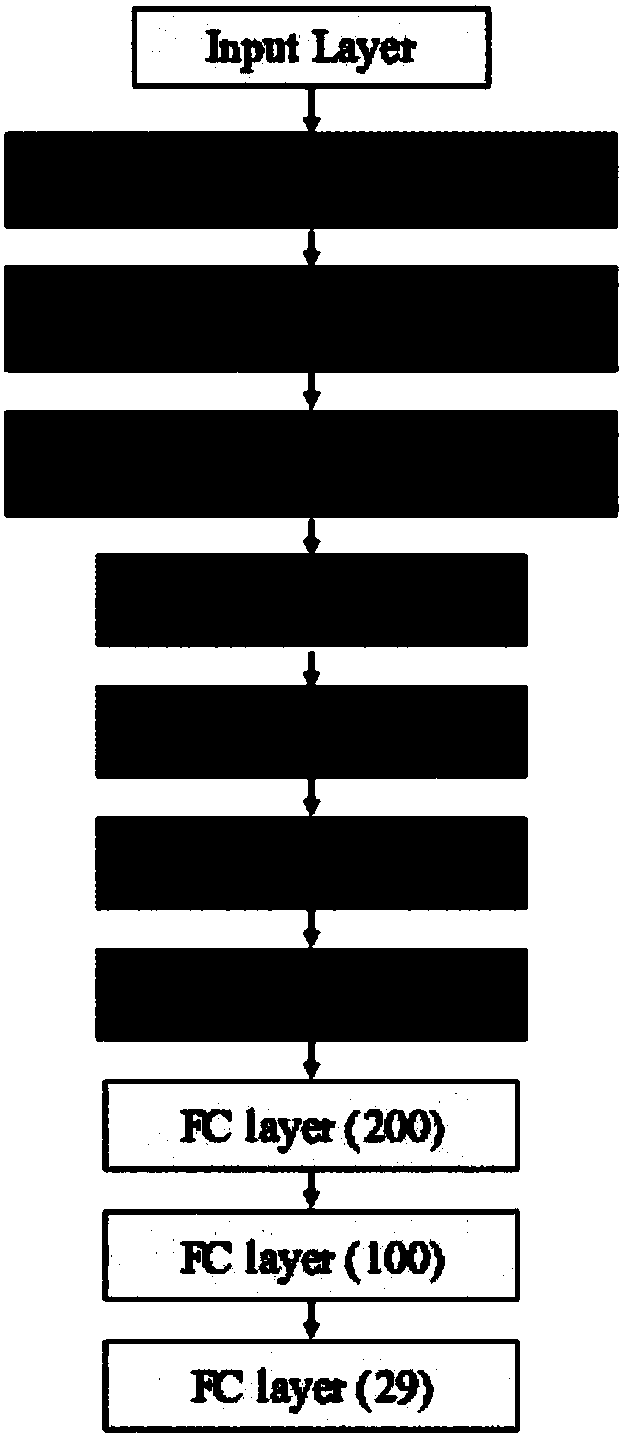
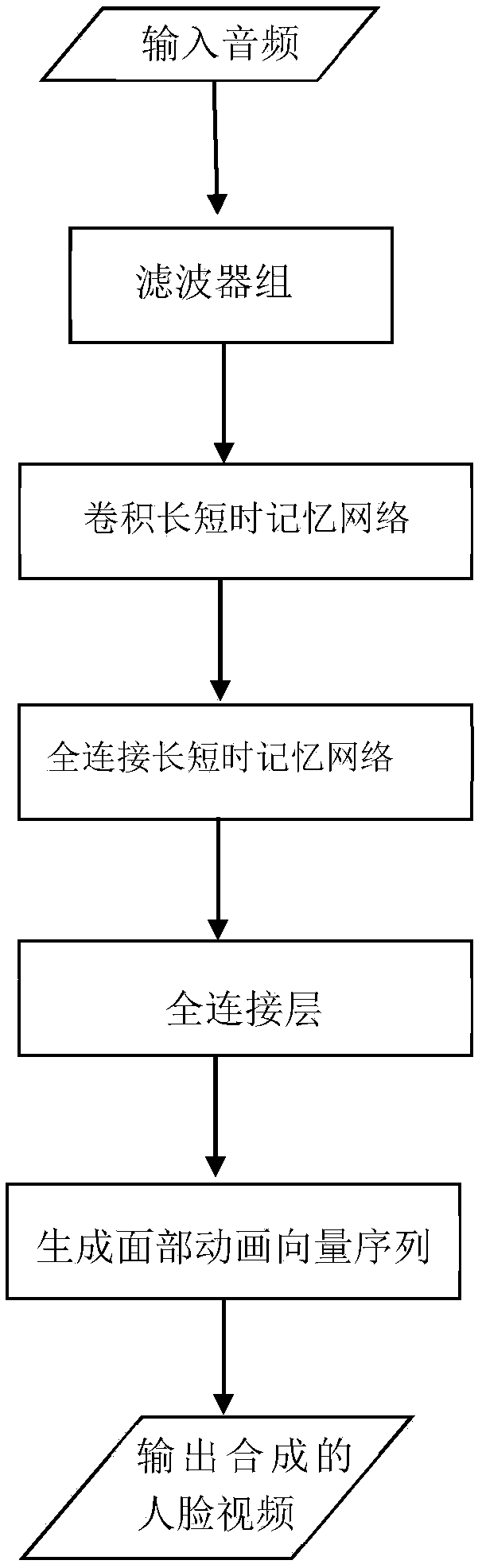
[0039] Such as figure 2 As shown, the following system modules are used:
[0040] The input module is used to receive the audio signal of the user's input voice or the audio signal of the text-synthesized speech, and then send it to the cascaded con...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More