Optimization method and system for single-channel speech recognition model
A speech recognition model, a single-channel technology, applied in speech recognition, speech analysis, neural learning methods, etc., can solve the problems of complex models, poor performance, cumbersome training process, etc., and achieve model simplification, good performance, and improved model performance Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment approach
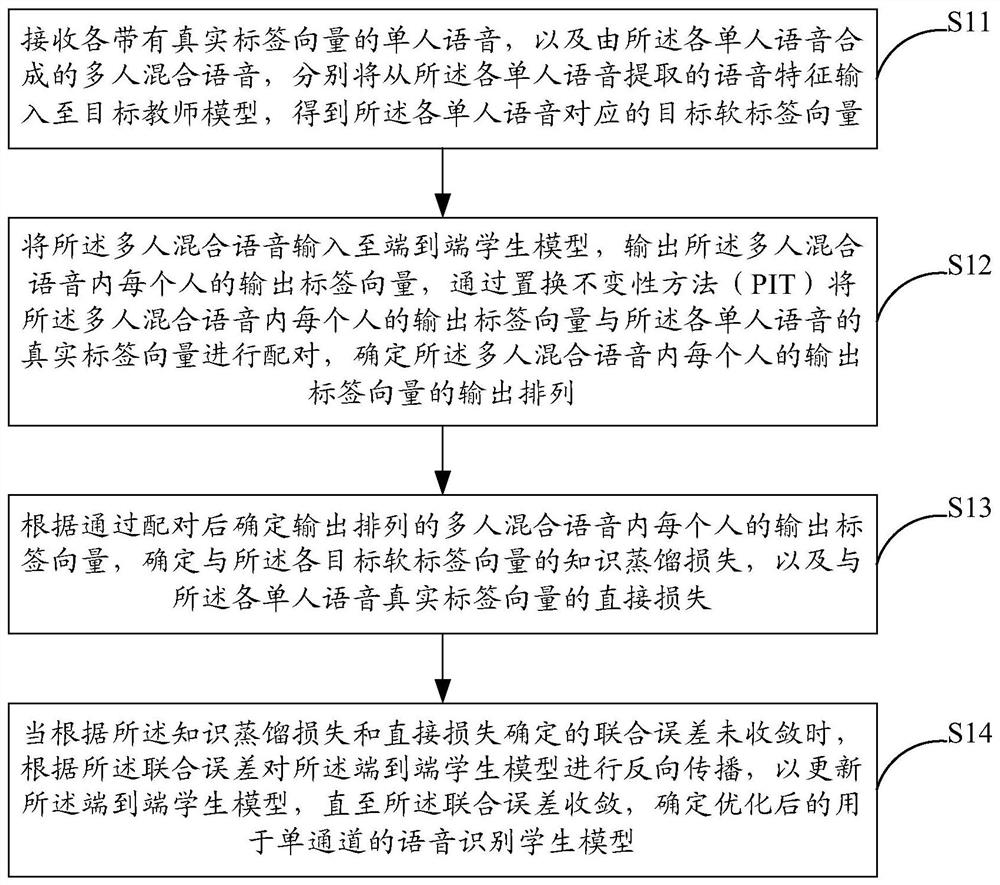
[0062] As an implementation manner, the joint error determined according to the knowledge distillation loss and the direct loss includes:
[0063] The knowledge distillation loss and the direct loss are weighted and summed according to a preset training mode to determine a joint error.
[0064] In order to meet different recognition requirements, different training modes can be set according to different usage environments during the training process. Then, through different weighting ratios, speech recognition models that meet different needs are trained.
[0065] It can be seen from this embodiment that by setting different training modes, during the training process, the joint error of the knowledge distillation loss and the direct loss is determined according to different weight ratios, so as to meet different requirements of the recognition environment. Thus, the recognition effect of the speech recognition model is improved.
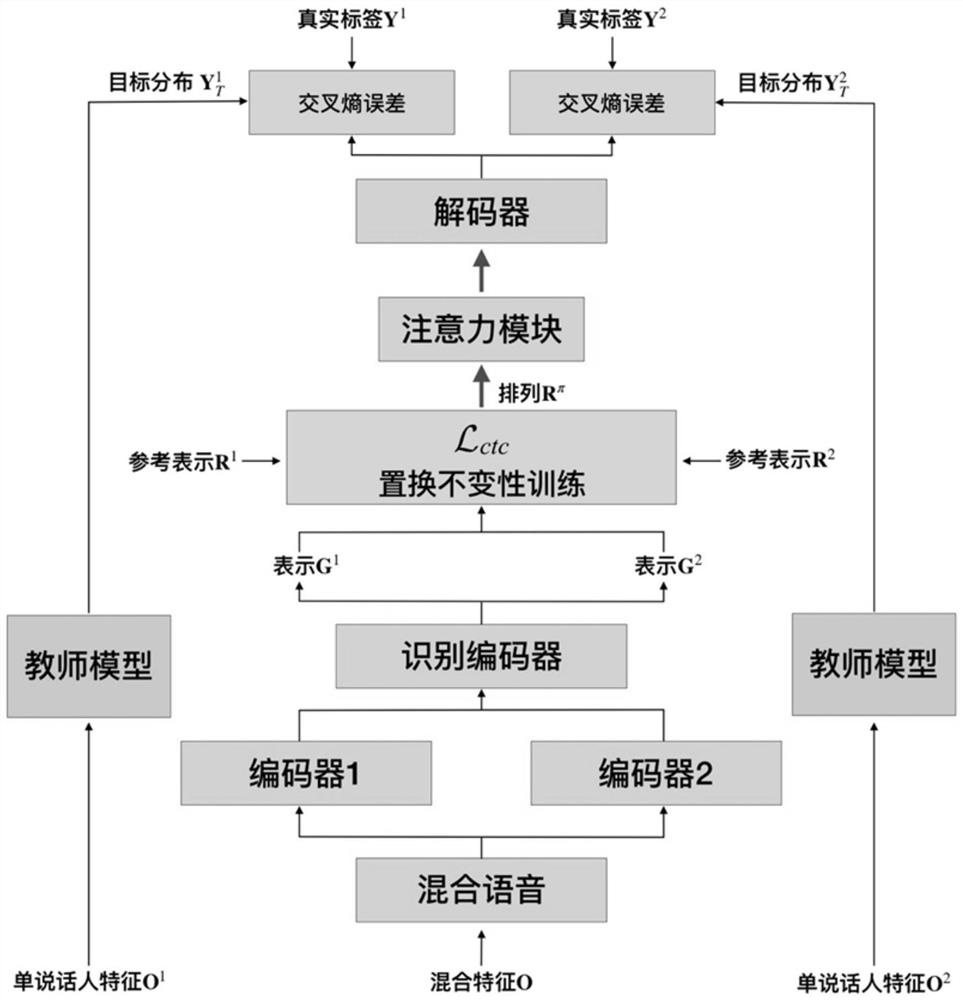
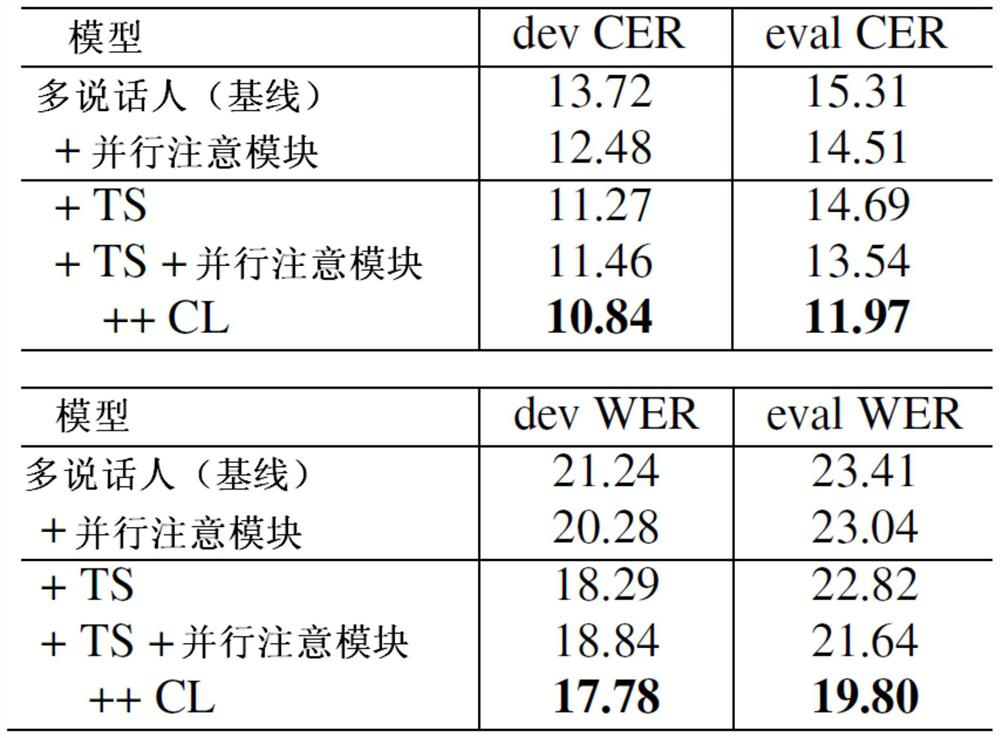
[0066] For further specific implementation...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com