

Text classification method based on CNN-SVM-KNN combined model
A technology of text classification and combined models, which is applied in text database clustering/classification, unstructured text data retrieval, special data processing applications, etc., and can solve the problems of low text classification accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
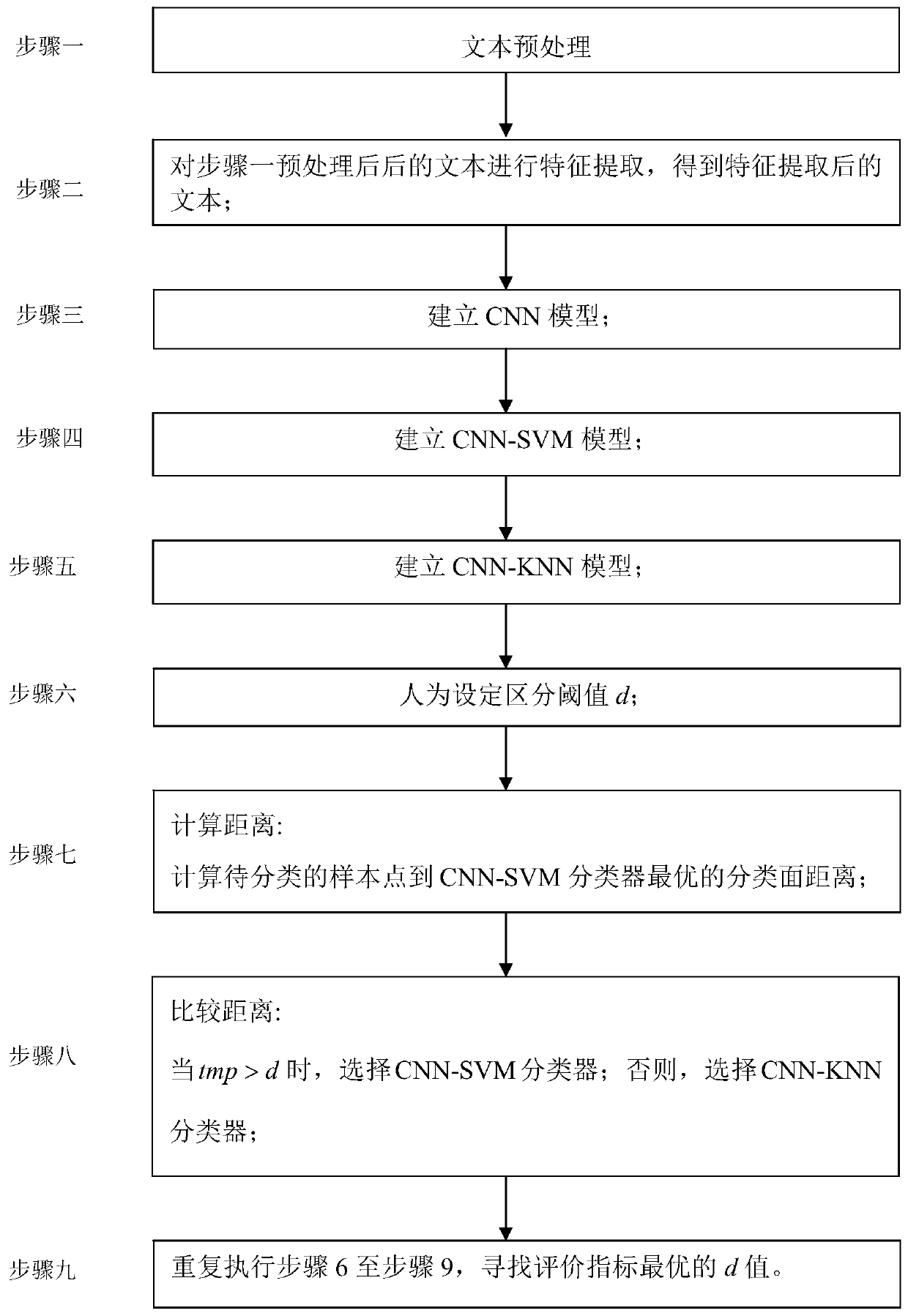
[0037] Specific implementation mode one: combine figure 1 Describe this embodiment, the specific process of the text classification method based on CNN-SVM-KNN combination model in this embodiment is:
[0038] The general process of text classification can generally be divided into the following processes: text preprocessing, feature selection, training and testing, and index evaluation. First, use the training set to establish a classifier model, and then use the model in the test set for classification, and finally compare the predicted category label with the real label, and judge the quality of the classifier through indicators.
[0039] Step 1: Text preprocessing;
[0040] Step 2: Perform feature extraction on the text after step 1 preprocessing to obtain the text after feature extraction;
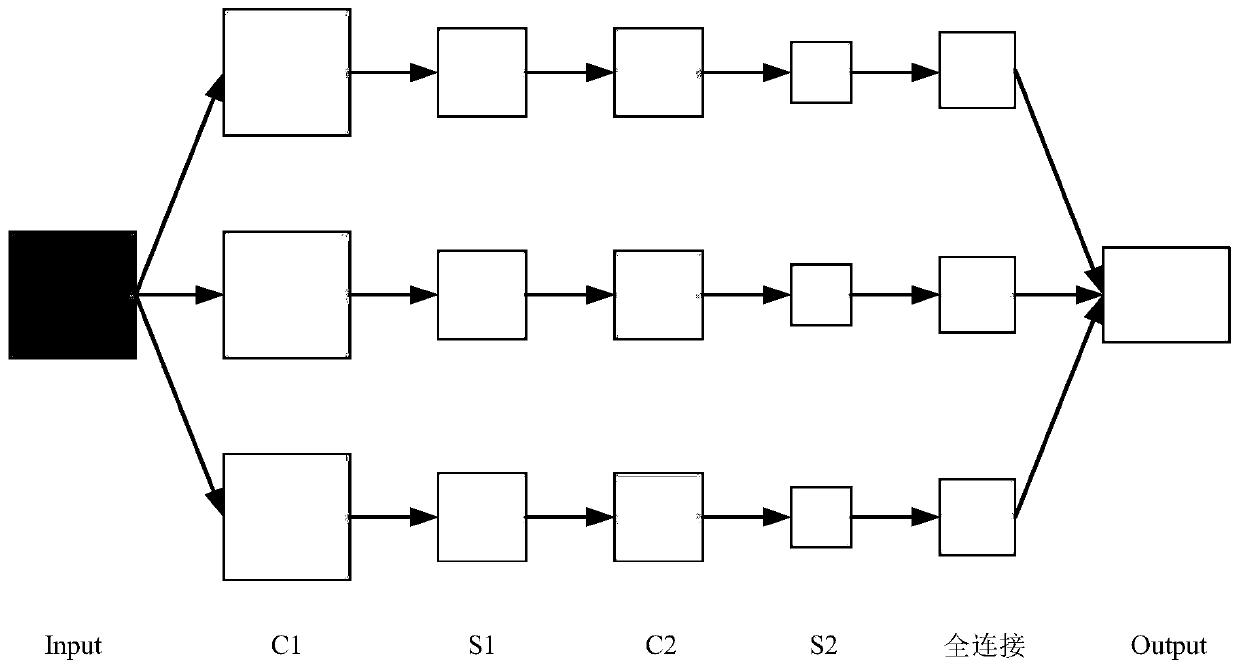
[0041] Step 3: Establish a CNN model based on step 2;
[0042] Step 4: Establish a CNN-SVM model;
[0043] Step 5: Establish CNN-KNN model;
[0044] Step 6: artificially set the...
specific Embodiment approach 2
[0054] Specific embodiment two: the difference between this embodiment and specific embodiment one is that the text is preprocessed in the step 1; the specific process is:
[0055] Text information is usually composed of words and sentences. Computers cannot directly recognize these text information. Therefore, it is necessary to preprocess the text to remove useless information and convert it into a language that can be recognized by the computer. Since the preprocessing methods of Chinese and English are different, they need to be operated separately.
[0056] Each word in the English text is connected by spaces, so its word segmentation operation can be completed by using spaces to perform word segmentation. Such as Figure 9 ;
[0057] The English text preprocessing process is:
[0058] (1) Convert uppercase letters to lowercase;
[0059] (2) Remove stop words, such as a, an, the words that have no practical meaning;
[0060] (3) morphological restoration; all English...
specific Embodiment approach 3
[0066] Specific embodiment three: the difference between this embodiment and specific embodiment one or two is that in the step 2, the text after the preprocessing of step one is subjected to feature extraction to obtain the text after the feature extraction; the process is:
[0067] Feature selection is to select b(b<B) features from B features, and the other B-b features are discarded.
[0068] So in this case, the new features are only a subset of the original features. The discarded features are considered to be of no importance and cannot represent the theme of the article. After the preprocessing operation, usually the feature matrix at this time will be very large and the dimension is very high, which leads to problems such as excessive calculation, long training time, and low classification accuracy, and feature selection is to eliminate those Part of the unimportant noise retains the features that can highlight the theme of the article, thereby achieving the purpose ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More