

Multi-task reinforcement learning method for realizing parallel task scheduling
A technology of reinforcement learning and task scheduling, applied in the fields of information, distribution and parallel computing, it can solve problems such as the difficulty of accurate modeling and the difficulty of heuristic algorithms to show scheduling performance, and achieve the effect of improving generalization.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

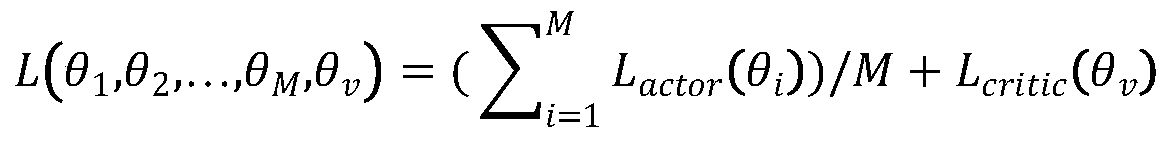
Examples
Embodiment Construction
[0038] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings.
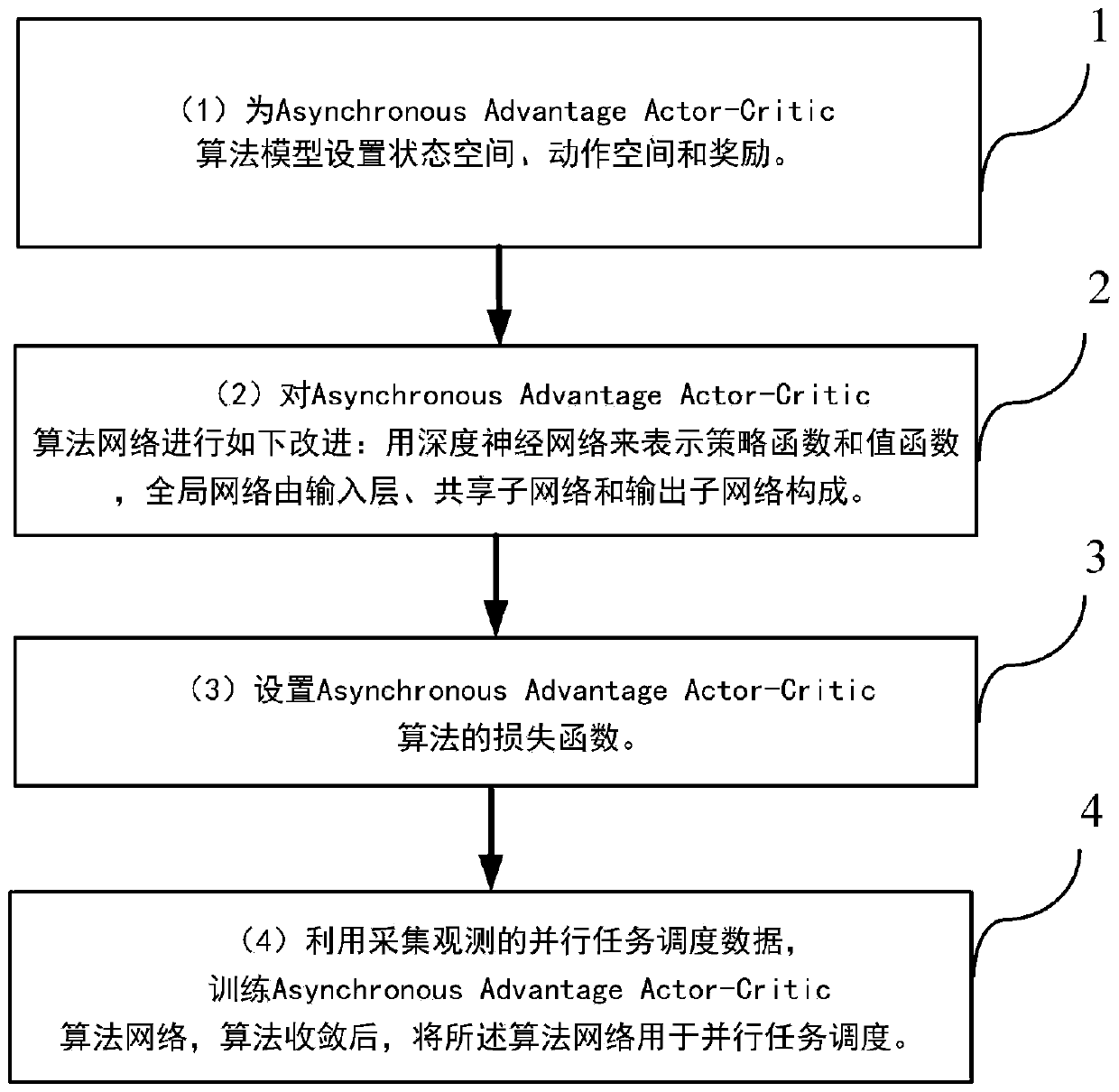
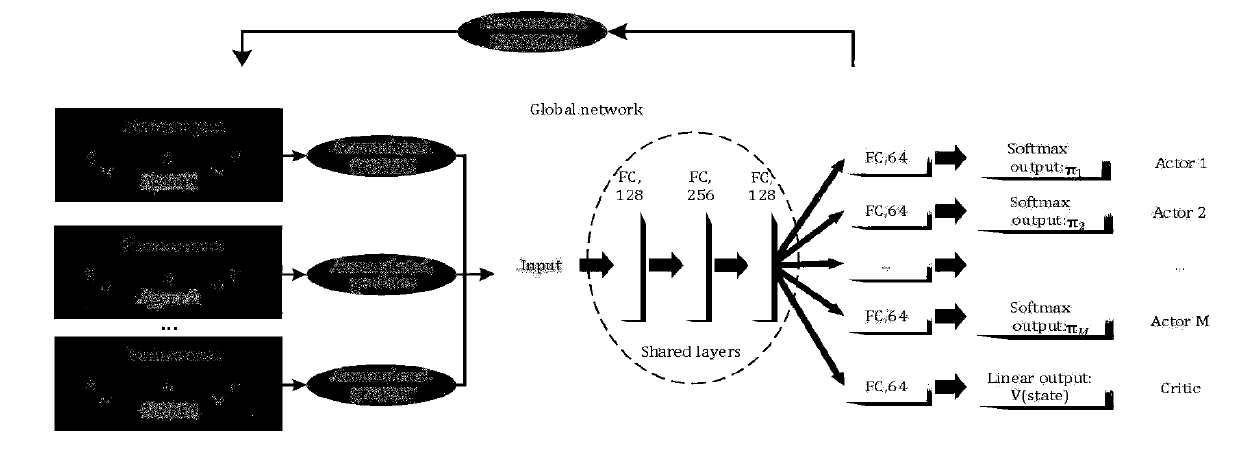
[0039] see figure 1 , introduce a kind of multi-task reinforcement learning method that realizes parallel task scheduling that the present invention proposes, realize based on the Asynchronous Advantage Actor-Critic algorithm of asynchronous advantage performer critic, described method comprises the following operation steps:
[0040] (1) Perform the following setting operations on the Asynchronous Advantage Actor-Critic algorithm model to better solve the parallel multi-task scheduling problem:
[0041] (1.1) set the state space S as a set, that is: S={F task ,L,T,F node}, where,
[0042] f task ={f 1 , f 2 , f 3 ,..., f M} represents the CPU instruction number of a job, where M is a natural number, representing the maximum number of subtasks of a job; f ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More