

Stochastic gradient descent optimization method based on distributed coding
A stochastic gradient descent, distributed coding technology, applied in neural learning methods, resource allocation, computer components, etc., can solve problems such as gradient delay and efficiency decline
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

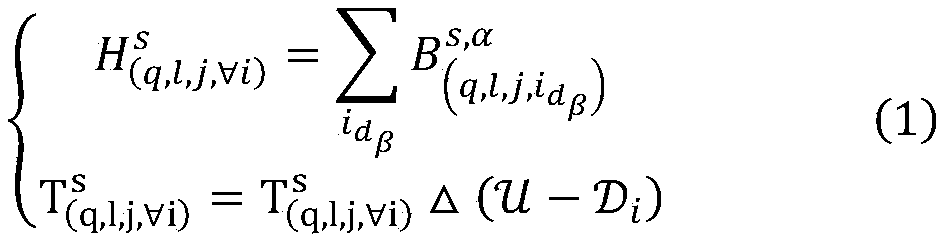
Examples
Embodiment Construction
[0049] The specific implementation manners of the present invention will be described below in conjunction with the accompanying drawings.
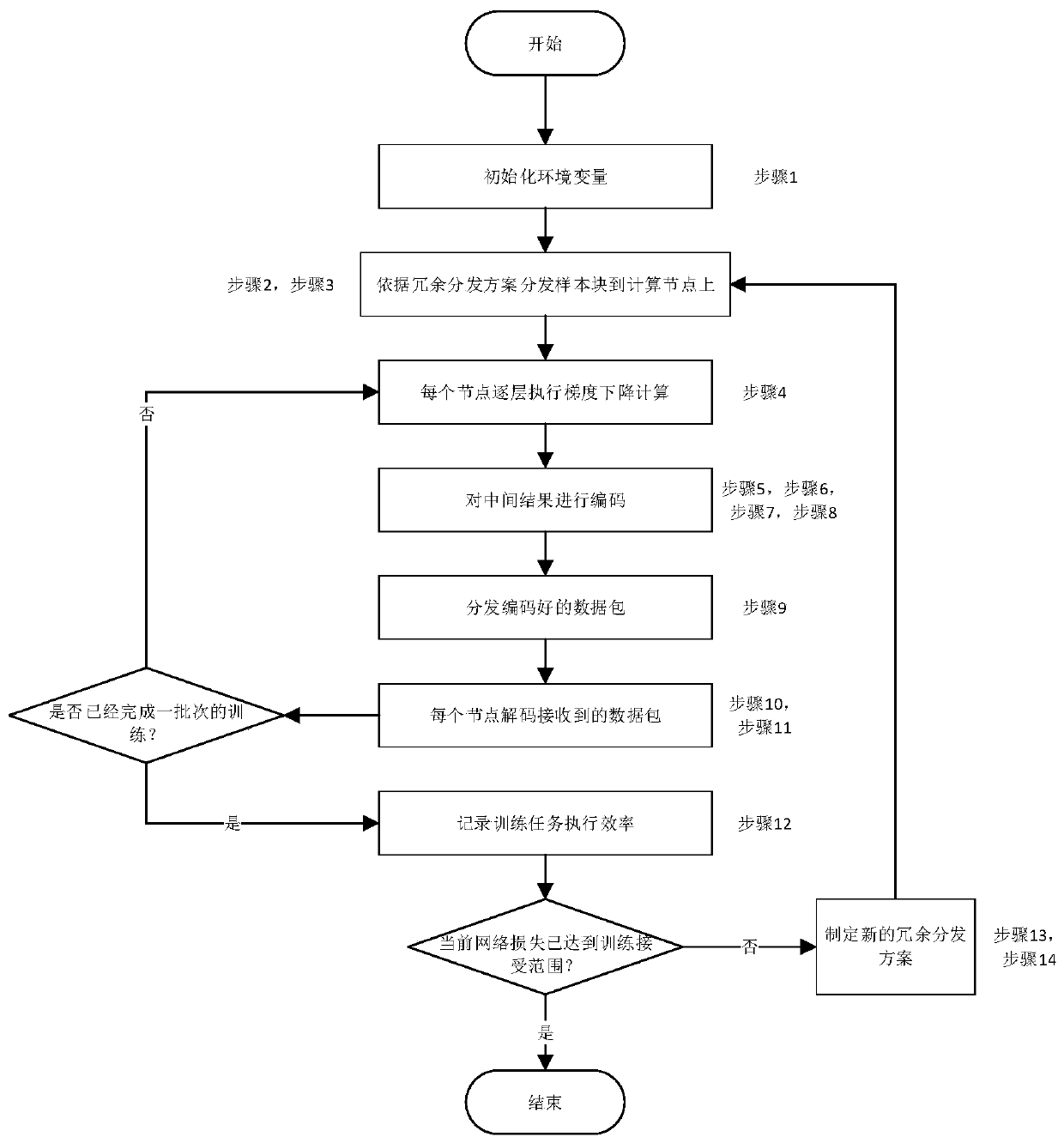
[0050] like Figure 1-2 As shown, the present invention has designed a stochastic gradient descent optimization algorithm of distributed coding, comprising the following steps:
[0051] If you want to perform MNIST handwritten digit recognition neural network training on a distributed cluster with four computing nodes, the neural network is a fully connected multilayer perceptron with a total of 6 layers. A redundancy setting of r = 2 was used with a sample size of 60,000 and a batch size of 360.
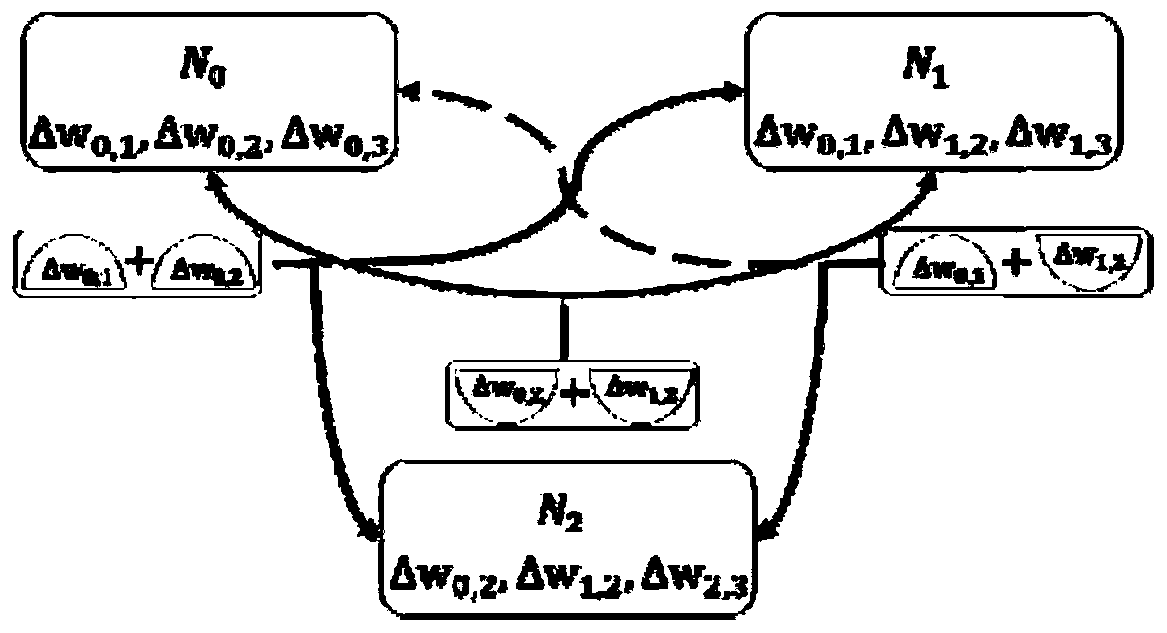
[0052] Step 1: To node N 1 , N 2 , N 3 , N 4 Arranged and combined, there are a total of A combination scheme, denoted as D 1 ,D 2 ,...,D 6 . D. 1 ={N 1 , N 2},D 2 ={N 1 , N 3},...,D 6 ={N 3 , N 4}. The combined result is recorded as
[0053] Step 2: The above 60,000 samples were equally divided into 166 sample batches...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More