

Action set output method and system based on multi-agent reinforcement learning
A technology of reinforcement learning and collective output, applied in instruments, character and pattern recognition, computer components, etc., to achieve good scalability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
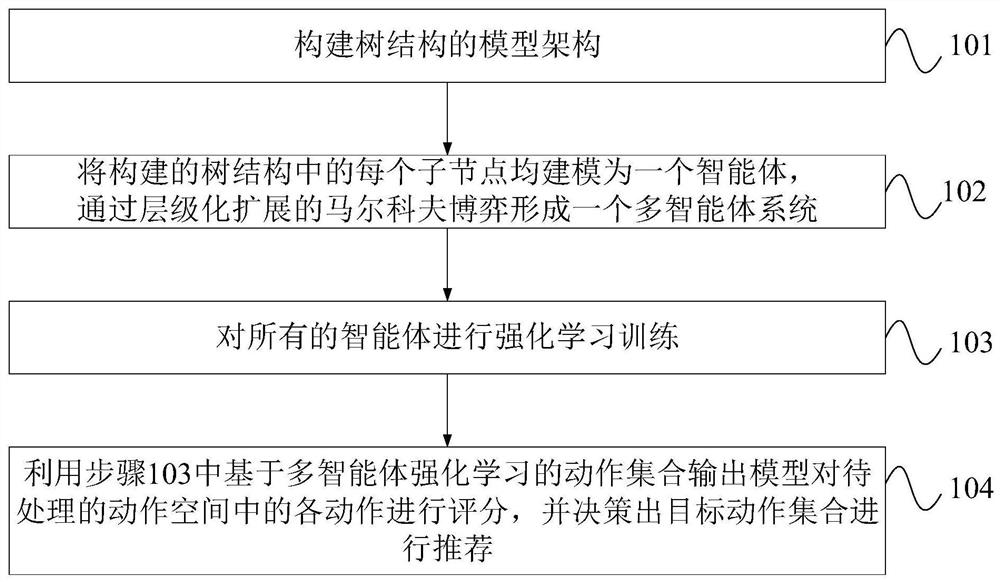
[0040] This embodiment provides an action set output method based on multi-agent reinforcement learning. The method can deal with the action set output problem of a large-scale action space through the mutual cooperation of multi-agents in a tree structure. Specifically, it can be expanded. The problem of outputting a set of thousands of actions in an action space of tens of millions of levels.
[0041] Such as figure 1 As shown, the described action set output method based on multi-agent reinforcement learning comprises the following steps:
[0042] Step 101, building a tree-structured model architecture;
[0043] Wherein, in this embodiment, the model architecture of TDM (Tree-based Deep Model, based on the depth model of the tree) is specifically constructed, and a 4-layer 12-fork tree is specifically constructed, and the TPGR (Tree-based Policy Gradient Recommendation System) is used. The method for constructing a balanced clustering tree, the clustering method includes ...
Embodiment 2
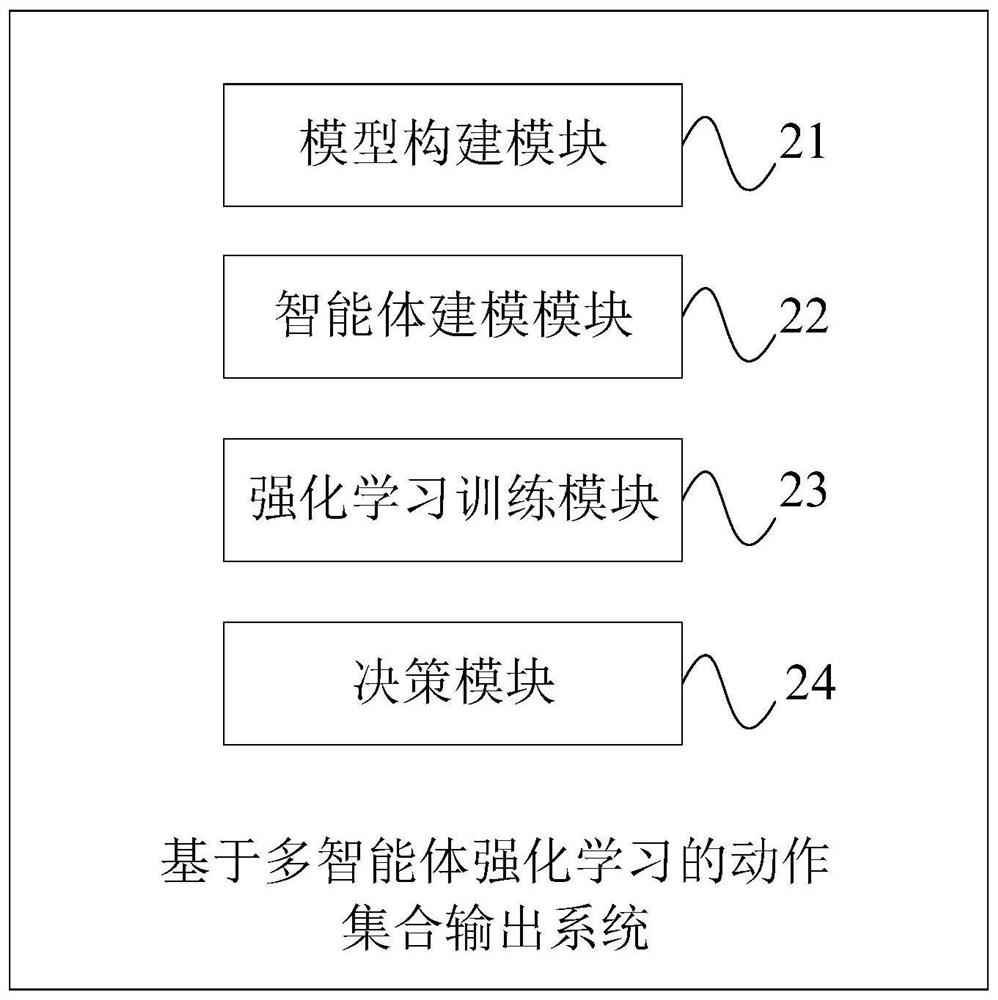
[0070] This embodiment provides an action set output system based on multi-agent reinforcement learning, such as figure 2 As shown, the system includes: model building module 21, agent modeling module 22, reinforcement learning training module 23 and decision-making module 24;
[0071] Wherein, the action set output system based on multi-agent reinforcement learning in this embodiment corresponds to the action set output method based on multi-agent reinforcement learning in Embodiment 1, so the model construction module 21, the agent modeling module 22, the reinforcement The learning and training module 23 and the decision-making module 24 can respectively execute step 101 , step 102 , step 103 and step 104 in Embodiment 1.
[0072] Specifically, the model building module 21 is used to build a tree-structured model architecture;
[0073] Wherein, in this embodiment, the model architecture of TDM (Tree-based Deep Model, based on the depth model of the tree) is specifically co...
Embodiment 3
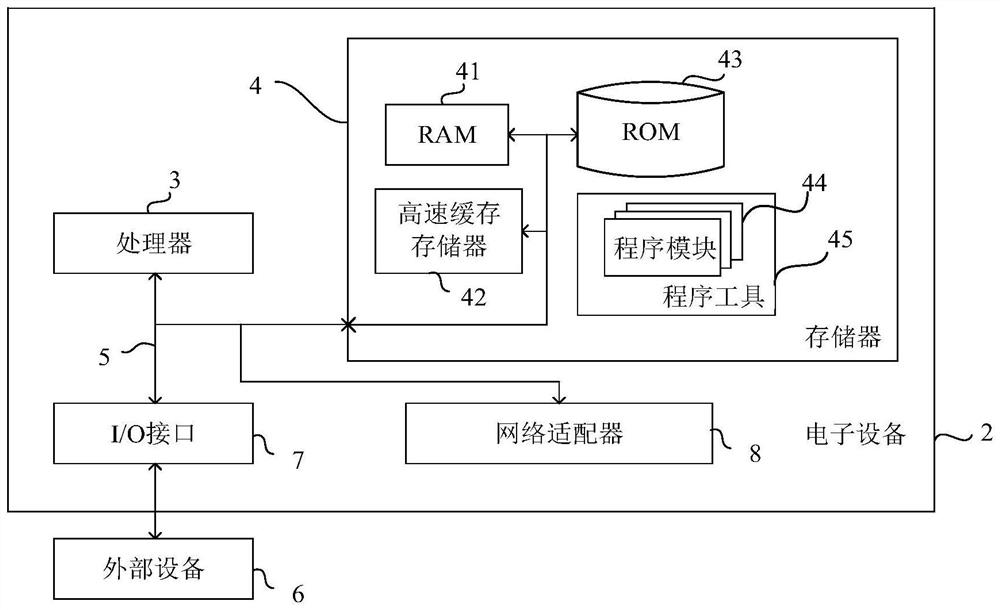
[0100] The present invention also provides an electronic device, such as image 3 As shown, the electronic device may include a memory, a processor, and a computer program stored on the memory and operable on the processor. When the processor executes the computer program, the multi-agent-based reinforcement learning in the foregoing embodiment 1 is implemented. The steps of the action set output method.
[0101] Understandably, image 3 The electronic device shown is just an example and should not limit the functions and scope of use of the embodiments of the present invention.
[0102] Such as image 3 As shown, the electronic device 2 may be in the form of a general-purpose computing device, for example, it may be a server device. Components of the electronic device 2 may include, but are not limited to: at least one processor 3 , at least one memory 4 , and a bus 5 connecting different system components (including the memory 4 and the processor 3 ).
[0103] The bus 5 ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More