Text type data identification method and system and storage medium
A data identification and type technology, applied in the field of machine learning, can solve the problem that the data asset sorting method cannot be effectively applied to text type data, etc., and achieves the effect of saving the time of data identification rules, short work time and high operation efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
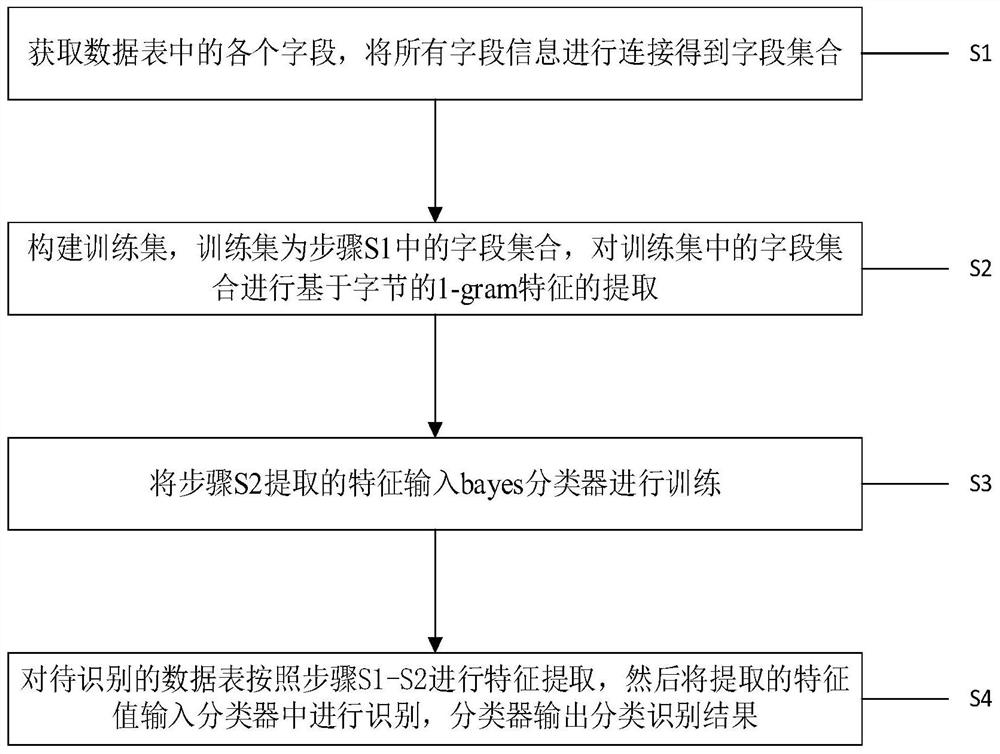
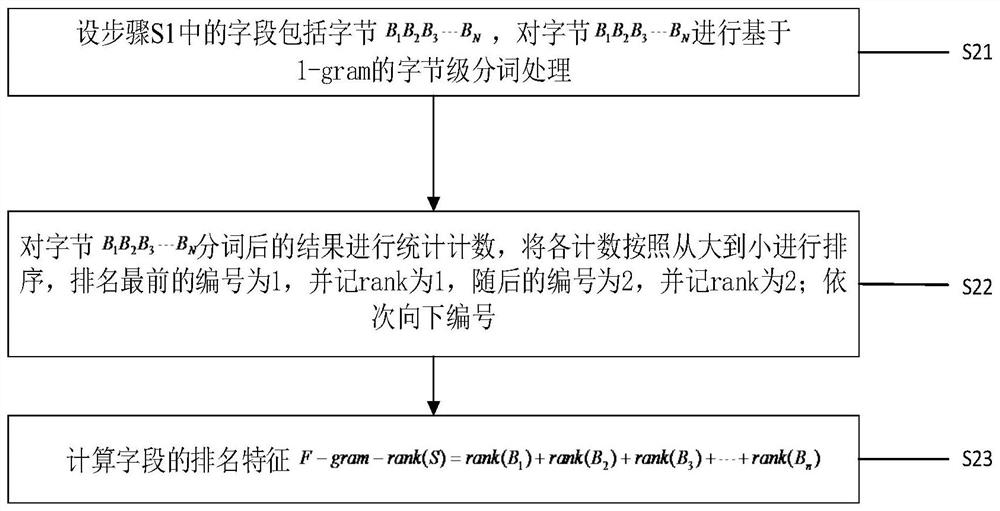
[0063] figure 1 is a method for text type data recognition according to an embodiment of the present invention, such as figure 1 shown, including the following steps:
[0064] S1. Obtain each field in the data table, and connect all field information to obtain a field set;
[0065] There will be multiple data tables in the data source, and there will be multiple fields in each data table, and all fields in all data tables will be concatenated to obtain a field set.
[0066] S2, build a training set, the training set is the field set in step S1, and extract the byte-based 1-gram feature to the field set in the training set;
[0067] Bayesian classification algorithm is based on the conditional independence assumption when analyzing the text, assuming that the words in the text are independent of each other and do not depend on other adjacent words in the text. For example, the text d consists of l features, expressed as d=(x 1 ,x 2 ,...,x l ), then the probability of the ...
Embodiment 2
[0090] Figure 5 is a system for text type data recognition according to an embodiment of the present invention, such as figure 2 As shown, the following modules are included:
[0091] An acquisition module 51 , a feature extraction module 52 , a classifier training module 53 and a classifier identification module 54 .
[0092] The obtaining module 51 is used to obtain each field in the data table, and connects all field information to obtain a field set;
[0093] The feature extraction module 52 is used to construct the training set, and the training set is the field collection obtained by the acquisition module 51, and the field collection in the training collection is extracted based on byte-based 1-gram features;
[0094] Classifier training module 53 is used for the feature input bayes classifier that feature extraction module 52 extracts and trains;
[0095] The classifier identification module 54 extracts the features of the data table to be identified after being p...
Embodiment 3
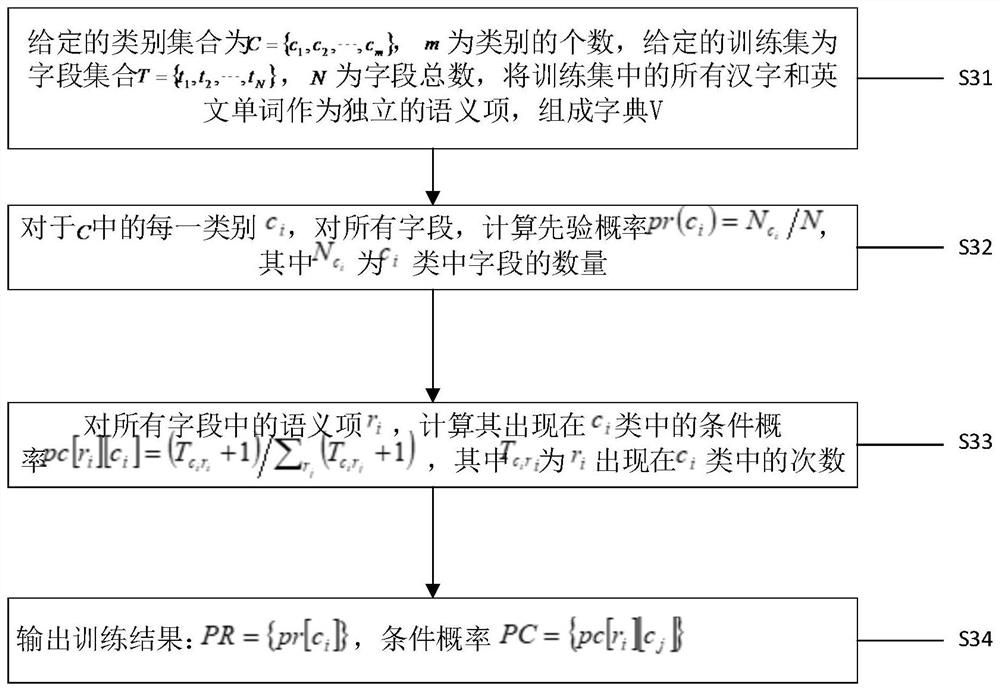
[0112] Suppose the training set includes two categories, each with a data table as follows:
[0113] Table 1c 1 Category: Personal Information
[0114] Name address Zhang San Chaoyang Road Li Si Renmin Road Wang Wu Wenhua Road Zhu Liu College Road Zhao Qi Li Ning Road
[0115] Table 2c 2 Class: Enterprise Information
[0116] business name address Zhong An Wei Shi Zhongguancun South Street Qihoo Technology Wangjing Street Baidu Technology Xi'er Banner Sina Technology Zhongguancun Ali Group hangzhou
[0117] Merge all the contents of the two fields of each category to obtain a field set, which is regarded as a large file. In the training phase, it is necessary to calculate the conditional probability of each semantic item for each category as a classification model.
[0118] The category is: C={personal information, enterprise information};
[0119] The total number of fi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com