Unstructured text similarity judgment method and system
A text similarity and unstructured technology, applied in the field of data processing, can solve the problems of leading role, ignoring text semantics, high word frequency weight, etc., and achieve the effect of improving accuracy, improving measurement accuracy, and strong robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
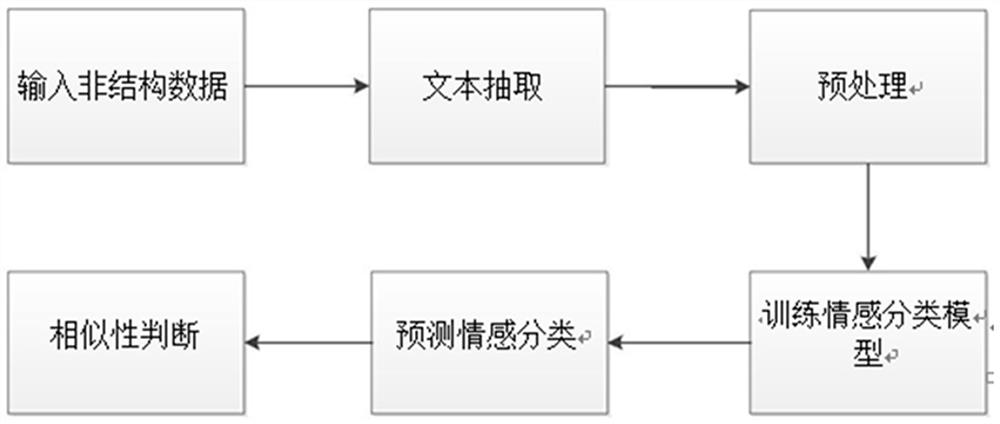
[0065] As shown in the figure, the present invention comprises the following steps:
[0066] 1. Input unstructured data
[0067] The unstructured data may be webpages or word documents from web crawlers.
[0068] 2. Text extraction
[0069] Extract textual information from unstructured data. This step uses apache tika (apache organization open source text extraction component) to extract text content, which is compatible with text content extraction in various formats, such as excel, pdf, xml, json, markdown, etc. This step finally outputs the extracted txt file .
[0070] 3. Preprocessing
[0071] In this step, a series of text preprocessing is performed on the txt obtained in the previous step. It includes operations such as removing web page html tags, removing garbled characters, removing special characters, and formatting punctuation marks. This step will output available plain text information.
[0072] 4. Training sentiment classification model
[0073] Step A: P...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More