

An Adaptive Structured Document Extraction Method
A structured and adaptive technology, applied in special data processing applications, network data browsing optimization, natural language data processing, etc., can solve problems such as low practicability, difficulty in adapting to site updates and changes, and achieve high scalability Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035]下面结合实施例对本发明作进一步说明。
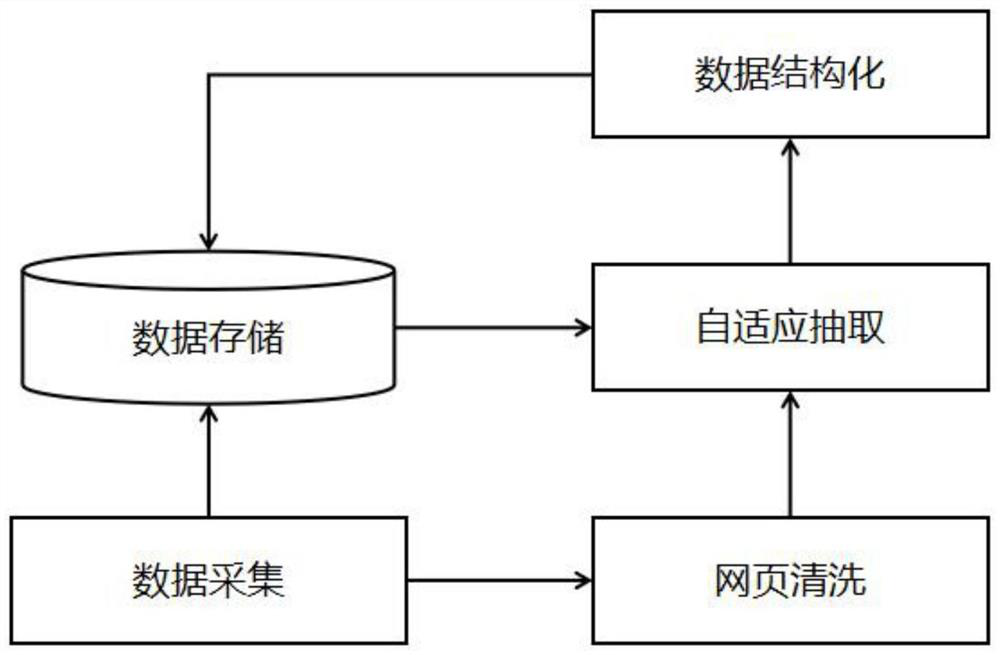
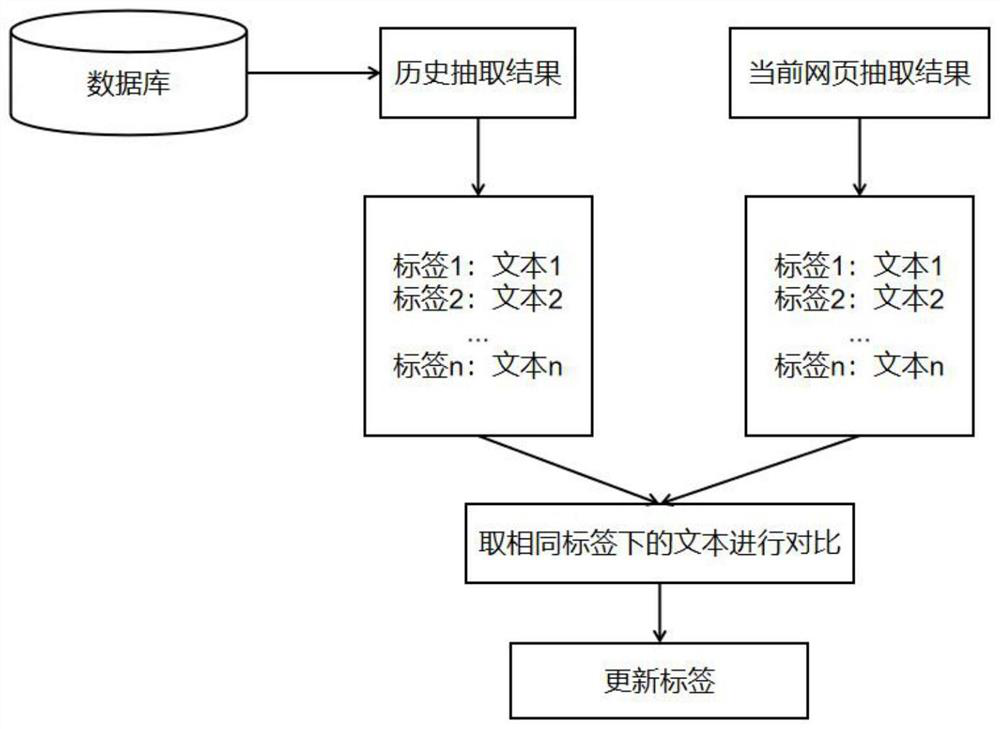
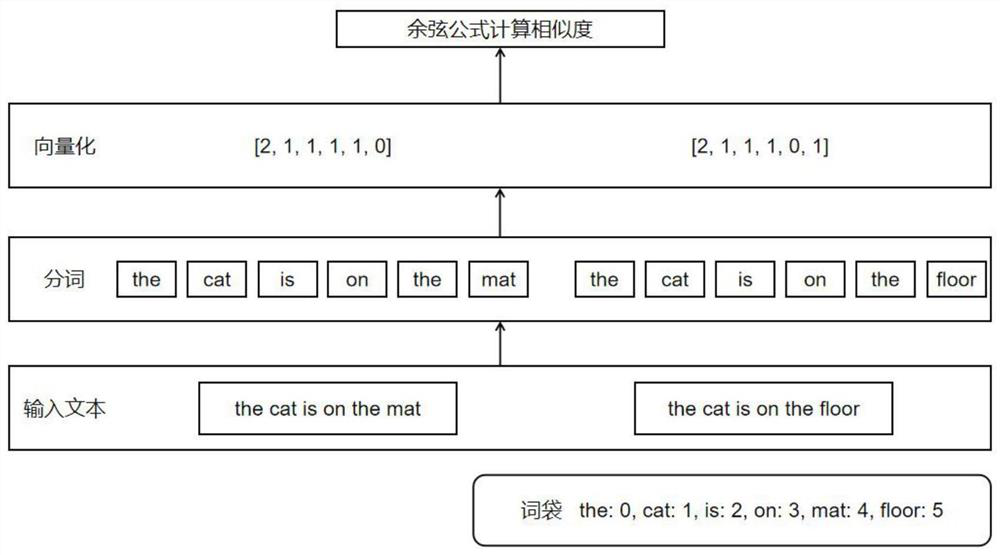
[0036]如图1、图2和图3所述,本发明首先从互联网中采集原始网页并存储,然后对采集到的原始网页中的原文进行通用无意义清洗,接下来根据Xpath定位网页中的元素,自动对比抽取出网页中有价值的内容,最后将抽取到的内容按照结构化的格式存储起来。本发明的核心改进点主要是对于抽取规则的改进,不需要先验知识和人工标注数据,而是通过挖掘网页之间的语义相似性,自动生成适用的抽取模式。
[0037]步骤1:根据指定的网页地址从互联网采集公开原始网页,并获得原始网页的文档内容。
[0038]1-1所述网页地址即url链接网址,是因特网上标准的资源地址,用于定位互联网上的资源,以获得指定网页的文档内容。
[0039]1-2通过url获得对应网页全部的文档内容。
[0040]步骤2:将步骤1抽取的文档内容存储到数据库中。存储时同步存储文档内容对应的url。
[0041]步骤3:对文档内容进行清洗。
[0042]通过对文档内容的清洗过滤掉采集的广告、网页中的meta信息等无效信息。由于原始文档内容中噪音数据较多,它们或许使用户浏览页面更方便,但保留这些数据对信息抽取没有意义,具体清洗实施步骤如下:
[0043]3-1对于文档内容中与主题内容无关的节点进行清除,所述的节点包括、等标签。
[0044]3-2清除注释、脚本语言、样式定义等标签及标签对应内容。
[0045]其中,对于步骤3-1、3-2中提及的html语法中固定标签的删除较为简单,可以直接利用预设的正则表达式集合,进行模式匹配,找到对应标签删除即可。
[0046]3-3清除导航栏、分类表、广告区域或友情链接。对于导航栏、分类表、广告区域或友情链接,若在它们的内容块中链接文字所占的比例小于设定阈值,则说明该表是一个可保留的链接列表。由于内容块中链接文字多以链接列表的形式存在,因此可计算表中链接文字和普通文字总数的比值,若该比值小于设定阈值,则说明该表有较大可能是一个可保留的链接列表。
[0047]3-4清除空表。在清除噪音数据后,可能会产生一些内容被清空的空表。这些空表信息价值较小,需要被清除。
[0048]步骤4:对清洗后的文档内容进行自适应抽取。
[0049]4-1基于Xpath对文档内容进行抽取。
[0050]具体的,Xpath为我们提供了一个对页面数据进行解析提取的方法。XPath是一门用于在HTM...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More