

Speech synthesis method and system for new tone generation
A technology of speech synthesis and timbre, applied in the speech synthesis method and system field of timbre generation, which can solve the problems of high complexity of the speech synthesis model and the method's over-reliance on the sound bank, etc., to save computing costs, flexible and diverse methods, and improve application foreground effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
preparation example Construction
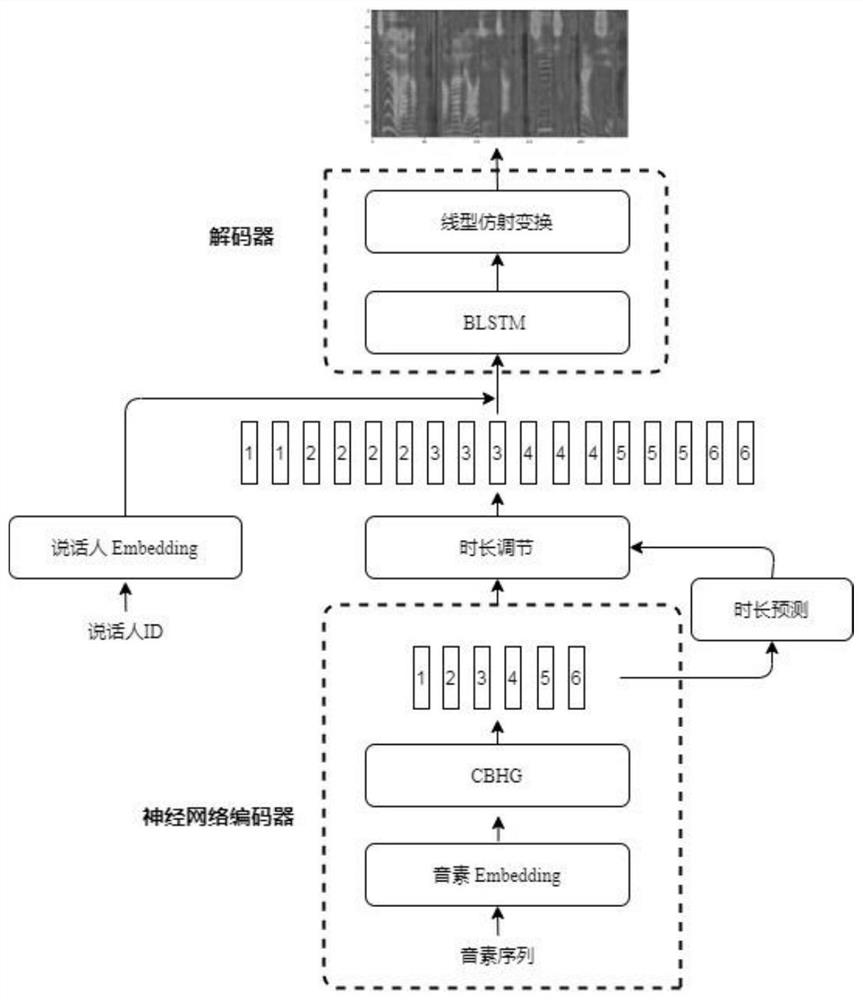
[0032] Such as figure 1 As shown, the speech synthesis method that a kind of new timbre of the present invention generates comprises the steps:
[0033] Step 1. Obtain the sample text and the corresponding real voice audio and speaker label, convert the real voice audio into a real Mel spectrum, process the sample text to obtain a phoneme sequence, and extract the pronunciation duration of the phoneme corresponding to the text;
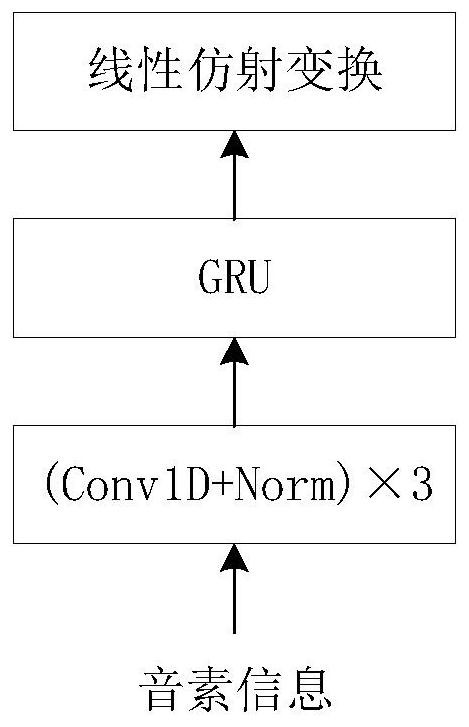
[0034] Step 2, build the speech synthesis model that new timbre produces, comprise speaker Embedding embedding layer, neural network coder, duration prediction module and decoder, described neural network coder is made of phoneme Embedding embedding layer, CBHG module;
[0035] Step 3, using the phoneme sequence and the speaker label to train the speech synthesis model generated by the new timbre;
[0036] Step 4. For the text to be synthesized, after preprocessing and the specified speaker label, it is used as the input of the speech synthesis model...
Embodiment
[0074] The present invention is tested on 46,500 pieces of audio and corresponding text datasets containing 8 speakers. The present invention carries out following pretreatment to data set:
[0075] 1) Extract the phoneme file and the corresponding audio, and use the open source tool Montreal-forced-aligner to extract the pronunciation duration of the phoneme.
[0076] 2) Extract the mel spectrum for each audio, where the window size is 50 milliseconds, the size of the frame shift is 12.5 milliseconds, and the dimension is 80 dimensions.
[0077] 3) Summing the mel-spectrum extracted from the audio in dimensions to obtain the energy of the mel-spectrum.
[0078] In the process of training the model, the text information is encoded as the input of the neural network encoder, the audio speaker label corresponding to the text is used as the input of the speaker Embedding layer, and the speaker vector and the time-length adjusted text The encoded information is concatenated and ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More