

A short text box clustering method, system, device and storage medium
A clustering method and short text technology, applied in text database clustering/classification, unstructured text data retrieval, instruments, etc., can solve problems such as poor practicability, reduce complexity, improve accuracy, and avoid vector The effect of high dimensionality
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
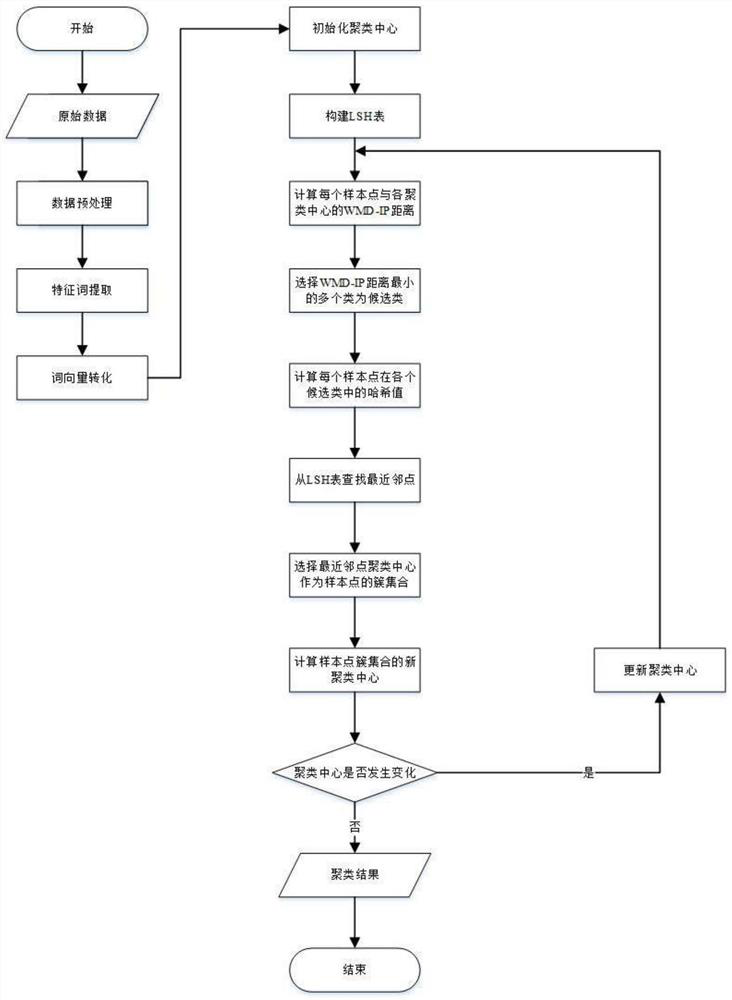
[0092] A short text box clustering method, such as figure 2 shown, including steps:
[0093] (1) Data preprocessing is performed on the extracted original short text to obtain the word segmentation of the short text;
[0094] (2) Extract the feature words of each short text;
[0095] (3) Convert the feature words of the short text into feature word vectors;
[0096] (4) Initialize the cluster center first, and then use the locality-sensitive hash algorithm to map the cluster center to the LSH table;
[0097] (5) According to the text similarity between the short text and the cluster center, select several candidate classes; the number of candidate classes is artificially set, generally 3-5, depending on the specific situation, the number of candidate classes will be change;
[0098] (6) Calculate the hash value of each short text feature vector in each candidate class, and find the nearest neighbor of the short text feature vector from the LSH table, and select the cluste...
Embodiment 2
[0102] According to a short text box clustering method provided in Embodiment 1, the difference is:
[0103] In step (1), data preprocessing is performed on the extracted original short text, such as figure 1 shown, specifically:
[0104] 1) Data cleaning: remove spelling mistakes, acronyms, colloquial expressions, irregular grammatical expressions, emoticons, garbled characters, links and useless symbols in the original short text; useless symbols such as "@, #, [] , []";
[0105] Data cleaning is performed on the data set to reduce data noise, achieve format standardization and remove duplicate data.
[0106] 2) Perform text segmentation on the short text after data cleaning: for English text, directly use spaces to segment English text; for Chinese text, use jieba tokenizer to segment Chinese text;
[0107] 3) Carry out stop word processing: By establishing a stop word dictionary, the text segmentation result is matched with the words in the stop word dictionary. If the ...
Embodiment 3
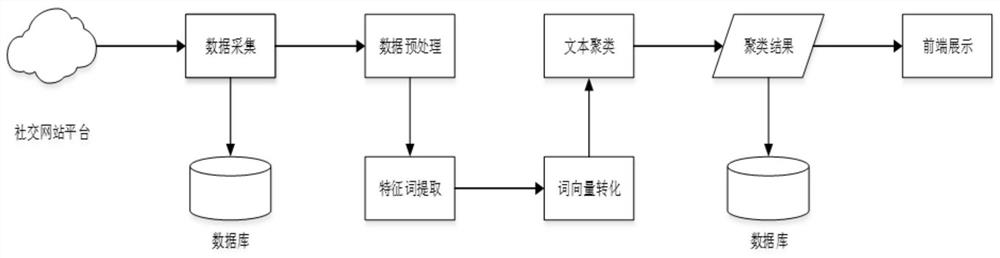
[0150] The realization system of a kind of short text box clustering method that embodiment 1 or 2 provides, as image 3 shown, including:
[0151] The data collection module is used to collect short text data from the social networking website platform, and then store the collected short text data into the database;
[0152] The data preprocessing module is used to preprocess the short text data collected by the data acquisition module to obtain the short text word segmentation result;
[0153] Feature word extraction module, used to extract the feature words of each short text;
[0154] The word vector conversion module is used to convert short text feature words into short text feature vectors;
[0155] The text clustering module is used to perform text clustering on short text feature vectors, store the text clustering results in the database, and display the short text data clustering results on the front-end interface.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More