Data query method and device, electronic equipment and storage medium
A technology of a data query device and a query method, which is applied in the field of electronic equipment, storage media, devices, and real-time data query methods under large-scale data volumes, and can solve the shortcomings, consumption, and multiple resources of large-scale data statistics and data deduplication and other issues to achieve the effect of increasing value and significance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
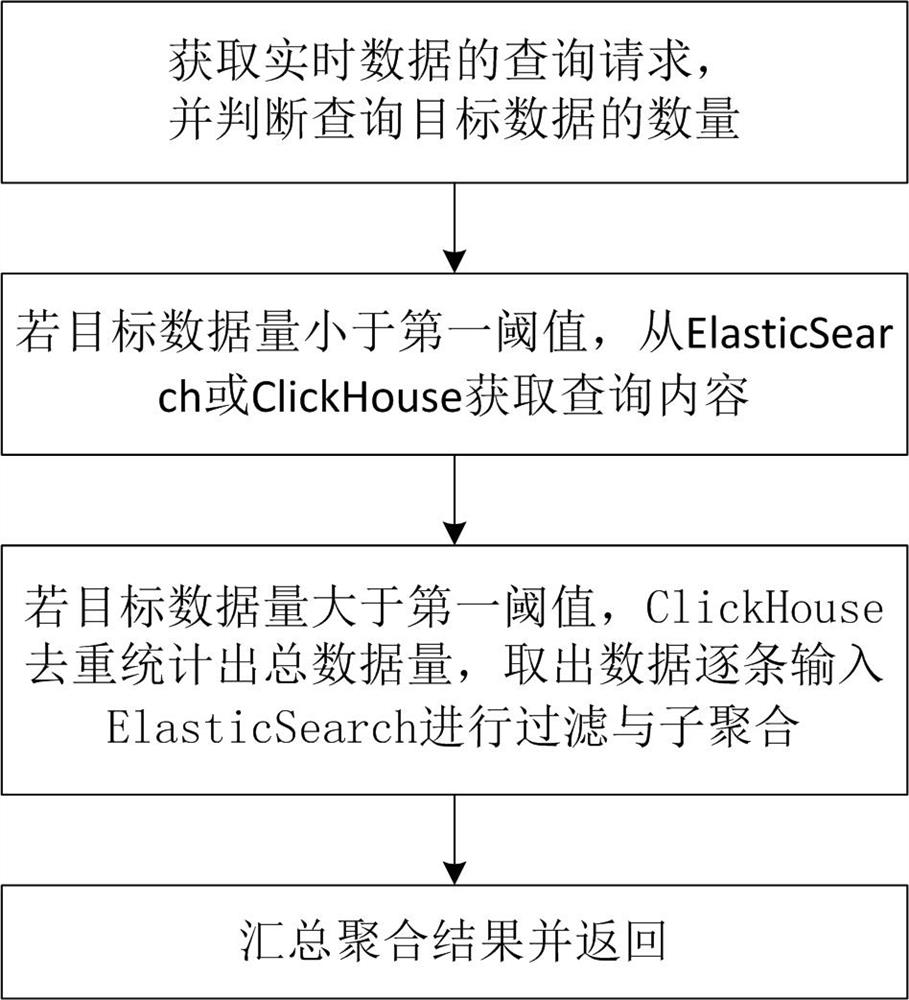
[0032] Such as figure 1 Shown, a kind of data real-time query method, described method comprises
[0033] Obtain query requests for real-time data and determine the size of the query target data;
[0034] If the amount of target data pointed to by the query request is less than the first threshold, the query content is obtained from ElasticSearch (for convenience of description, hereinafter referred to as ES) or ClickHouse;
[0035] If the amount of target data pointed to by the query request is greater than the first threshold, ClickHouse deduplicates and counts the total data amount, takes out the data, and inputs them into ES one by one for filtering and sub-aggregation, and summarizes the aggregation results and returns them.
[0036] Nested aggregation is the data aggregation of multiple fields in sequence. For example, the "gender" field is aggregated first, and then the "age" field is nested (sub-aggregation), that is, one aggregation is nested within another aggregati...
Embodiment 2
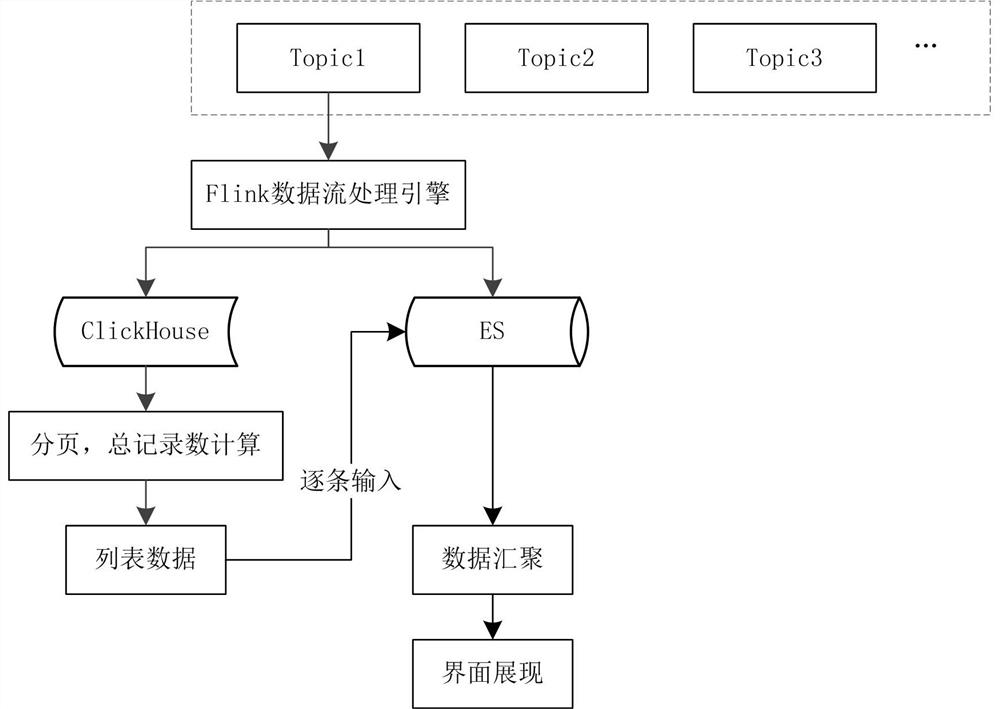
[0044] Such as figure 2 As shown, before obtaining the query request described in the first embodiment, the real-time collected target data is split and stored in different Kafka topics according to the data type. Topic is the basic unit of Kafka data writing operation. Producers (such as various network security devices) can publish data (such as security event logs) to the selected Topic (topic), and each record published to Topic is assigned For each consumer instance in the subscription consumer group, where the consumer instance can be distributed in multiple processes or on multiple machines. ClickHouse and ES, as the data consumers in this embodiment, consume data from the same topic through the Flink data flow processing engine and store them separately. ClickHouse only stores field data that participates in aggregation analysis.
[0045] Kafka is a distributed, partition-supporting, and multi-copy distributed message system. Its biggest feature is that it can proces...
Embodiment 3
[0055] Such as image 3 As shown, a data query device is provided, comprising:
[0056] The query receiving module obtains the real-time query request initiated by the data, and parses to obtain the aggregation analysis dimension;
[0057] A query judging module, configured to judge whether the amount of target data pointed to by the query request is greater than a preset first threshold;
[0058] The query processing module is used for initiating corresponding data aggregation analysis according to the amount of target data pointed to by the query request, and returning the aggregation result.
[0059] Preferably, the query processing module is used for:
[0060] If the amount of target data pointed to by the query request is less than the first threshold, the query content is obtained from ElasticSearch or ClickHouse;
[0061] If the amount of target data pointed to by the query request is greater than the first threshold, ClickHouse deduplicates and counts the total amou...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com