

Multi-robot collaborative navigation and obstacle avoidance method
A collaborative navigation and multi-robot technology, applied in the field of robot navigation, can solve problems such as the amount of calculation can no longer support high real-time requirements, system stability deterioration, etc., to reduce training time, solve difficult convergence, and speed up the training process Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0073] This embodiment includes a network of actors and a network of judges, such as Figure 5 and Figure 6 . The actor network structure mainly includes convolutional layers, maximum pooling layers, linear layers, activation layers, and long-short-term memory layers. The activation function uses a linear correction unit activation function to solve the problem of gradient disappearance and neuron "death". The convolutional layer and the pooling layer process the input red, green and blue three-channel image to extract features. The judge network adds action variables in the input of long and short-term memory, and the others are consistent with the actor network.
[0074] The convolutional neural network consists of two convolutional layers, the convolution kernel sizes are 16×3×3 and 32×3×3, the number of channels is 16 and 32, and the step size is 3. The maximum pooling layer selects the maximum value in the convolution kernel as output.
[0075] The hyperparameters ar...
Embodiment 2
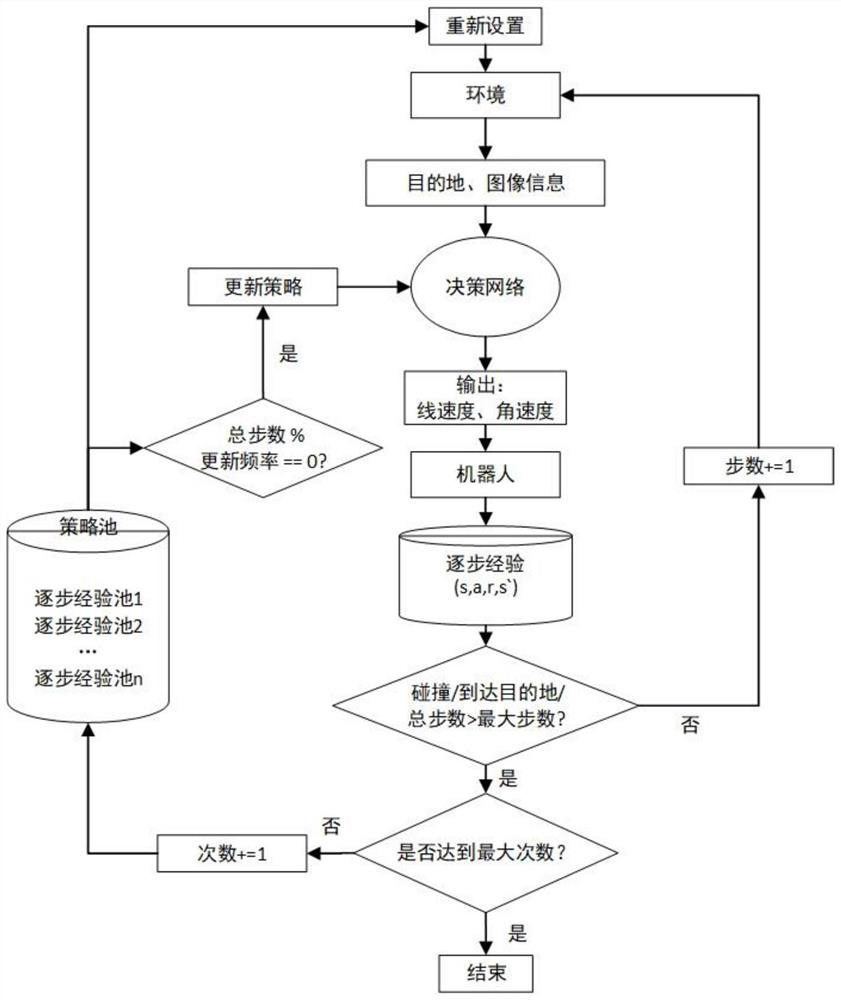
[0078] The purpose of this embodiment is to implement a deep reinforcement learning algorithm network for a single robot to learn obstacle and reward information in the environment. Figure 8 It is an implementation flowchart of a deep reinforcement learning algorithm of a long short-term memory-deep deterministic policy gradient algorithm for multi-robot navigation provided by an embodiment of the present invention. As shown in the figure, the method may include the following steps:
[0079] S1: Establish the state model of the robot: use partially observable Markov decision process to infer the distribution of the state of the robot according to the observation information of the environment, and describe it with a six-tuple (S, A, T, R, Z, O).
[0080] S2: Establish a convolutional neural network for robot camera data processing: obtain the current camera data of the robot, perform Gaussian blur and scale transformation, and obtain the vector of the robot's image observation...
Embodiment 3
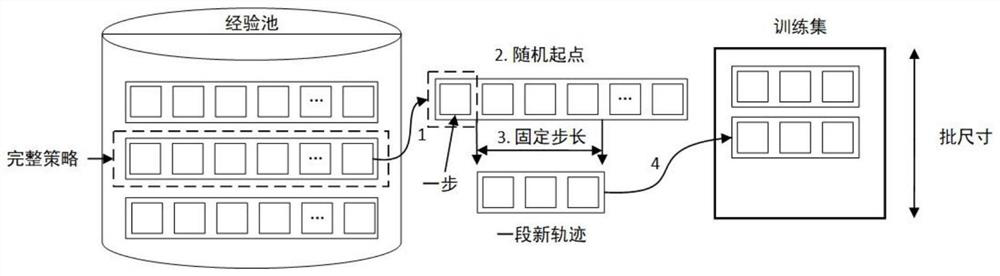
[0127] Embodiment 3 of the present invention provides an improved long-short-term memory network. This embodiment adopts the network structure of long-short-term memory-deep deterministic policy gradient algorithm. The purpose is to introduce short-term memory, speed up and improve the speed and performance of the reinforcement learning training process , adapted to a reinforcement learning process with long short-term memory networks. The improvement part mainly includes two parts: random update and jump update. image 3 It is a schematic diagram of the random update of the long short-term memory network of a specific embodiment of the multi-robot cooperative navigation and obstacle avoidance method and system in the present invention. As shown in the figure, the strategy randomly selects a time point in each randomly selected overall strategy , start learning with a fixed number of steps from this moment, and reset the state of the long-short-term memory hidden layer to zero...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More